"ประเทศไทยมีข้อมูลกฎหมายและประกาศหลายล้านฉบับ แต่ทำไมเราถึงยังไม่มี AI กฎหมายเก่งๆ หรือระบบค้นหาที่เข้าใจบริบทได้สักที?" คำตอบสั้นๆ คือ "ข้อมูล" ครับ.. ข้อมูลส่วนใหญ่ของเรายังติดอยู่ในรูปแบบ PDF หรือรูปภาพสแกน ที่มนุษย์อ่านรู้เรื่อง แต่คอมพิวเตอร์กลับมองเห็นเป็นเพียงความว่างเปล่า นี่จึงเป็นจุดเริ่มต้นของโครงการที่เกิดจากความร่วมมือระหว่างภาคประชาชนและฝ่ายนิติบัญญัติ โดยมีเป้าหมายคือทำให้ข้อมูลสาธารณะจากภาครัฐให้กลายเป็นข้อมูลเปิดและแปลงข้อมูลให้พร้อมใช้งานได้จริง
โครงการ Open Law Data Thailand เกิดจาก สว.ตวงคุณ ทรงธรรมวัฒน์ (วุฒิสภา) ร่วมกับ นักพัฒนาซอฟต์แวร์อาสา และ สำนักเลขาธิการคณะรัฐมนตรี (สลค.) ได้เปิดเผยชุดข้อมูลราชกิจจานุเบกษาย้อนหลังตั้งแต่ปี พ.ศ. 2428 จนถึงปัจจุบัน จำนวนกว่า 1.3 ล้านฉบับ ในรูปแบบที่คอมพิวเตอร์สามารถประมวลผลได้ ผ่าน Hugging Face เพื่อให้นักพัฒนาและนักวิจัยนำไปต่อยอดใช้งานได้โดยไม่มีค่าใช้จ่าย
บทความนี้จะเล่าถึงรายละเอียดของโครงการ ก่อนจะเปิดข้อมูลให้นักพัฒนาได้เข้าไปใช้งานในเฟสแรก
อุปสรรคการเข้าถึงข้อมูลกฎหมายของภาคธุรกิจ
โจทย์จากภาคธุรกิจ: ความเสี่ยงที่เกิดจากการเข้าถึงข้อมูลยาก
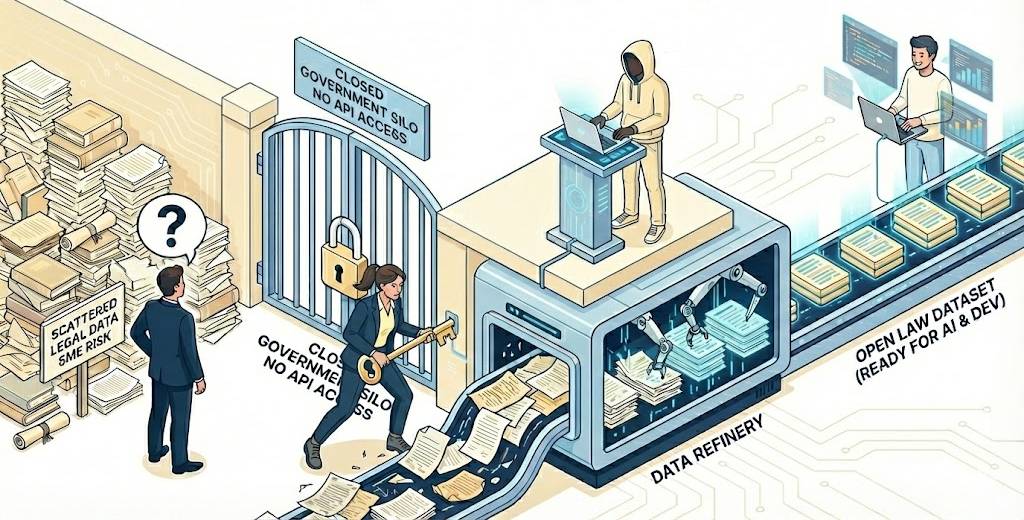
จุดเริ่มต้นของโครงการนี้เกิดจากปัญหาจริงในภาคอุตสาหกรรม โดย สว.ตวงคุณ ทรงธรรมวัฒน์ คณะกรรมาธิการการพาณิชย์และการอุตสาหกรรม วุฒิสภา ได้สะท้อนปัญหาของผู้ประกอบการ โดยเฉพาะ SME และนักลงทุนต่างชาติ ที่พบว่าการเข้าถึงข้อมูลกฎหมายและระเบียบข้อบังคับของไทยเป็นเรื่องยุ่งยากและมีต้นทุนสูง เนื่องจากข้อมูลกระจัดกระจายอยู่ตามเว็บไซต์ราชการนับร้อยแห่ง ไม่มีการรวมศูนย์ และตรวจสอบสถานะความเป็นปัจจุบันได้ยาก ความไม่รู้นี้กลายเป็น "ความเสี่ยง" ในการดำเนินธุรกิจ ท่านจึงมีแนวคิดที่จะพัฒนาระบบฐานข้อมูลกฎหมายที่ค้นหาง่าย รวดเร็ว และแม่นยำ เพื่อปลดล็อกอุปสรรคนี้
ความจริงจากฝั่ง Tech: เรามีแค่ "เว็บ" แต่ไม่มี "ข้อมูล"
เมื่อโจทย์ดังกล่าวถูกส่งต่อมายังทีม Tech คำตอบในเชิงเทคนิคคือ "ระบบค้นหาหรือ AI ไม่ใช่เรื่องยาก... แต่ปัญหาอยู่ที่ข้อมูล" ทีมงานได้ชี้แจงข้อเท็จจริงว่า แม้กฎหมายไทยจะเป็นข้อมูลเปิดเผย (Open Information) ที่ใครก็เปิดเว็บอ่านได้ แต่รัฐไม่มีช่องทางให้นักพัฒนาเชื่อมต่อหรือดึงข้อมูลไปใช้งานได้ (No Open API / No Open Data)
ทางออก: โมเดลความร่วมมือ "รัฐเปิด-เอกชนทำ"
เมื่อเห็นปัญหาตรงกันว่า "มีข้อมูลแต่เอาออกมาใช้ไม่ได้" จึงนำไปสู่การตั้ง "คณะทำงาน Open Law Data" โดยวางกลยุทธ์ว่าจะไม่เรียกร้องให้หน่วยงานรัฐต้องลงทุนสร้างระบบ IT ใหม่ซึ่งใช้งบประมาณสูงและใช้เวลานาน แต่เราจะเข้าไปทำหน้าที่เป็น "ผู้ช่วยแปรรูปข้อมูล" แทน
- ฝ่ายนิติบัญญัติ (สว.): ทำหน้าที่ประสานงานนโยบายกับหน่วยงานเจ้าของข้อมูล เพื่อขอความร่วมมือในการส่งมอบไฟล์ดิจิทัลหรือเปิดช่องทางเชื่อมต่อข้อมูลดิบ
- ภาคประชาชน (ทีม Tech): รับข้อมูลเหล่านั้นมาทำหน้าที่เป็นแปรรูปข้อมูล จัดการ Clean Data, ทำ OCR, และจัดโครงสร้างใหม่
เป้าหมายของความร่วมมือนี้จึงชัดเจน คือการอำนวยความสะดวกให้ภาครัฐ เพื่อดึงข้อมูลที่กระจัดกระจายมารวมศูนย์ และแปลงสภาพเป็น Standard Dataset เปิดให้นักพัฒนาและประชาชนดาวน์โหลดไปใช้งานต่อได้จริง เพื่อให้ระบบนิเวศของ Legal Tech ในประเทศไทยเกิดขึ้นได้
พันธมิตรแรกและโมเดล "Win-Win" ของการจัดการข้อมูล
ราชกิจจานุเบกษา: จิ๊กซอว์ชิ้นแรกจาก สลค.
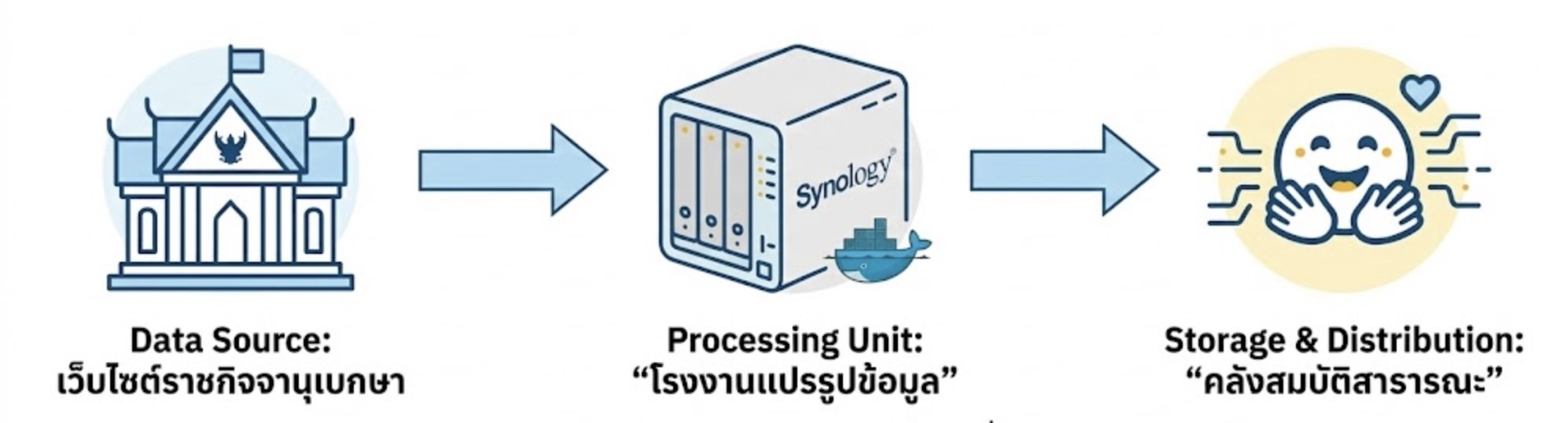
เป้าหมายแรกของโครงการคือข้อมูล "ราชกิจจานุเบกษา" ซึ่งเป็นกฎหมายและประกาศสำคัญของประเทศ ทีมงานได้เข้าหารือกับ สำนักเลขาธิการคณะรัฐมนตรี (สลค.) ซึ่งเป็นหน่วยงานดูแลข้อมูลหลัก จากการพูดคุยพบว่าเจ้าหน้าที่และผู้บริหารของ สลค. มีวิสัยทัศน์ที่สอดคล้องกัน คือต้องการให้ข้อมูลถูกนำไปใช้ประโยชน์และเข้าถึงได้ง่าย การประสานงานจึงเป็นไปอย่างราบรื่น จนนำมาสู่การอนุเคราะห์ข้อมูลราชกิจจานุเบกษาย้อนหลังเพื่อนำมาจัดทำเป็น Dataset ชุดแรกของโครงการ
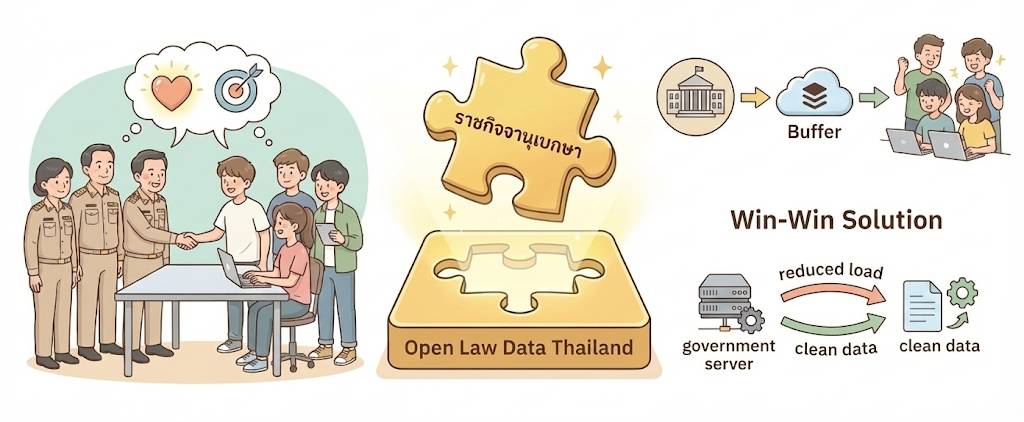
แก้ปัญหา "Scraping" ด้วยโมเดล Buffer
ความร่วมมือนี้ไม่ได้เพียงแค่ช่วยปลดล็อกข้อมูล แต่ยังช่วยแก้ปัญหาทางเทคนิคเรื้อรังของภาครัฐ ในอดีตเมื่อนักพัฒนาต้องการข้อมูลจำนวนมาก มักใช้วิธีเขียนโปรแกรม Scraping ยิง Request เข้าเว็บไซต์ราชการโดยตรง ซึ่งสร้างภาระ (Load) ให้กับ Server อย่างหนัก ส่งผลกระทบต่อผู้ใช้งานทั่วไป และทำให้ภาครัฐต้องสิ้นเปลืองงบประมาณในการขยาย Infrastructure เพื่อรองรับ Traffic จากบอทเหล่านี้
ผลลัพธ์: ลดภาระรัฐ เพิ่มความสะดวกให้นักพัฒนา
โครงการ Open Law Data Thailand จึงเสนอตัวเข้ามาเป็น "ตัวกลาง" (Buffer) ในการกระจายข้อมูล โดยรับข้อมูลดิบจากหน่วยงานรัฐ แล้วนำมา Hosting ไว้บนแพลตฟอร์มภายนอกที่รองรับ Traffic ได้สูงและออกแบบมาเพื่อการแจกจ่ายข้อมูลโดยเฉพาะ (ในที่นี้คือ Hugging Face)
ผลลัพธ์ที่ได้คือ Win-Win Solution:
- นักพัฒนา: ได้ไฟล์ Clean Data เต็มก้อน (Bulk Download) ไปใช้งานได้ทันที ลดความเสี่ยงในการเขียน Scraper
- ภาครัฐ: สามารถ Offload Traffic ออกจากระบบหลัก ประหยัดงบประมาณ Server และทำให้เว็บไซต์หลักทำงานได้เต็มประสิทธิภาพเพื่อให้บริการประชาชน
ความร่วมมือกับ สลค. ในครั้งนี้จึงเป็น Use Case ต้นแบบที่พิสูจน์ว่า การเปิดเผยข้อมูล (Open Data) ผ่านตัวกลางที่มีความพร้อมด้านเทคโนโลยี คือทางออกที่ยั่งยืนและคุ้มค่าที่สุดสำหรับทุกฝ่าย
สถาปัตยกรรมระบบ
เมื่อได้รับข้อมูลดิบมาแล้ว โจทย์ใหญ่ทางวิศวกรรมคือ "จะจัดเก็บและประมวลผลอย่างไรให้ยั่งยืน?" โดยไม่มีงบประมาณสำหรับ Cloud Server หรือ Data Center ราคาแพง ทีมงานจึงต้องออกแบบสถาปัตยกรรมที่เน้นความคุ้มค่าสูงสุด โดยผสมผสานเครื่องมือที่เหมาะสมเข้าด้วยกัน
ทำไมต้อง Hugging Face
สำหรับการจัดเก็บและแจกจ่ายข้อมูล เราตัดสินใจเลือกใช้ Hugging Face เป็นฐานข้อมูลหลักแทนการใช้ Cloud Storage ทั่วไป เนื่องจากตอบโจทย์โครงการลักษณะนี้ที่สุด:
- Designed for Datasets: โครงสร้างพื้นฐานถูกออกแบบมาเพื่อรองรับ Dataset ขนาดใหญ่ระดับ Terabyte สำหรับงาน AI โดยเฉพาะ และไม่มีค่าใช้จ่ายสำหรับ Public Repository
- Native Viewer: มีระบบ Dataset Viewer ให้ผู้ใช้พรีวิวข้อมูล JSON/Text ผ่านหน้าเว็บได้ทันทีโดยไม่ต้องดาวน์โหลดไฟล์ทั้งหมด
- Community Standard: เป็นแพลตฟอร์มมาตรฐานที่นักพัฒนาสาย Data/AI คุ้นเคยอยู่แล้ว ทำให้ง่ายต่อการนำไปใช้งานต่อ
ใช้ NAS ให้เป็น Server
สำหรับหน่วยประมวลผล เพื่อรัน Data Pipeline ตลอด 24 ชั่วโมง (ตรวจสอบข้อมูลใหม่ -> ดาวน์โหลด -> รัน OCR -> อัปโหลด) เราเลือกใช้ทางออกที่เรียบง่ายและประหยัดที่สุดคือ "Synology NAS" (ได้รับการสนับสนุนจากสภาอุตสาหกรรมจังหวัดสมุทรสงคราม) แทนการเช่า Cloud Server:
- Docker Support: ทีมงานเขียน Data Pipeline ทั้งหมดเป็น Docker Container แล้ว Deploy ลงบน NAS
- Automation: ตั้ง Schedule ให้ Container ทำงานอัตโนมัติในช่วงเวลาที่เหมาะสม เพื่อประมวลผลข้อมูลวันละนิดละหน่อยอย่างสม่ำเสมอ
- Energy Efficient: กินไฟน้อยกว่าการเปิด PC หรือ Server เครื่องใหญ่ทิ้งไว้มาก ช่วยลดต้นทุนระยะยาว
การจัดการไฟล์ 1.3 ล้านฉบับบน Git
ข้อจำกัดของ Git เมื่อต้องรับมือกับไฟล์นับล้าน
เมื่อทีมงานได้รับข้อมูลย้อนหลังตั้งแต่ปี พ.ศ. 2428 จนถึงปัจจุบัน ซึ่งมีจำนวนไฟล์ PDF รวมกว่า 1.3 ล้านฉบับ (ขนาดประมาณ 170GB) เราพยายามนำเข้าสู่ระบบด้วยวิธีการ Commit ขึ้น Git Repository แบบปกติ แต่กลับพบปัญหาทางเทคนิคทันที:
- Git Index Bloat: Git ไม่ได้ถูกออกแบบมาให้จัดการกับจำนวนไฟล์ หลักล้านชิ้นใน Repository เดียว ทำให้ Index ของ Git มีขนาดใหญ่จนกินทรัพยากรเครื่องมหาศาล ส่งผลให้ Pipeline หยุดทำงาน
- Unclonable Repository: ขนาดของ Repository ที่ใหญ่เกินไปทำให้นักพัฒนาทั่วไปไม่สามารถสั่ง
git cloneได้สำเร็จ หรือต้องใช้เวลานานหลายวัน ซึ่งขัดต่อเป้าหมายที่ต้องการให้ข้อมูลเข้าถึงได้ง่าย - API Rate Limits: การยิง Request จำนวนมากไปยัง Hugging Face เพื่อจัดการไฟล์ทีละชิ้นทำให้ติดข้อจำกัดของ API
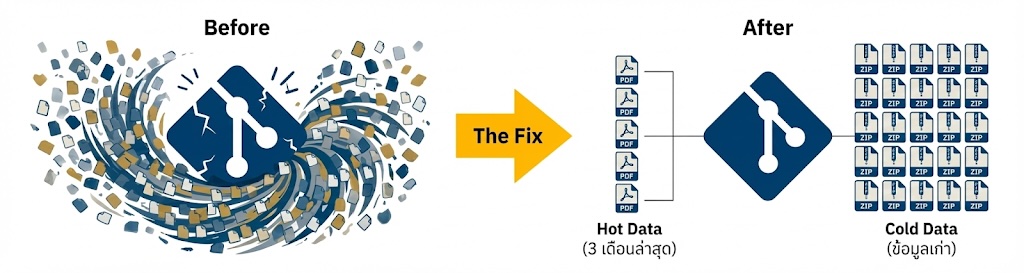
แก้ปัญหาด้วยสถาปัตยกรรม Hot/Cold Storage
เพื่อแก้ปัญหานี้ เราจึงรื้อระบบจัดเก็บใหม่โดยนำแนวคิด "Hot/Cold Data Strategy" มาประยุกต์ใช้ร่วมกับฟีเจอร์ Git LFS (Large File Storage) โดยแบ่งข้อมูลออกเป็น 2 ส่วน:
- Cold Data (Archive): สำหรับข้อมูลเก่าที่มีอายุมากกว่า 3 เดือน ทีมงานใช้วิธี "มัดรวม" (Batching) เป็นรายเดือนและบีบอัดเป็นไฟล์
.zip(เช่น1999-01.zip) วิธีนี้ช่วยลดจำนวน Object ใน Git จากหลักล้านเหลือเพียงหลักพัน ทำให้ Git กลับมาทำงานได้ลื่นไหล และช่วยให้นักพัฒนาสามารถเลือกดาวน์โหลดเฉพาะช่วงปีที่สนใจได้ (Selective Download) โดยไม่ต้องดึงข้อมูลทั้งหมด - Hot Data (Fresh Zone): สำหรับข้อมูลย้อนหลัง 3 เดือนล่าสุด เรายังคงจัดเก็บเป็น ไฟล์ PDF รายฉบับ เพื่อให้บอทหรือนักข่าวสามารถเข้าถึงประกาศรายวันได้แบบ Real-time และง่ายต่อการตรวจสอบความถูกต้องของ Pipeline ประจำวัน
การจัดโครงสร้าง Directory
ควบคู่ไปกับการบีบอัดไฟล์ เราได้จัดโครงสร้างโฟลเดอร์ใหม่แบบลำดับชั้น (YYYY/YYYY-MM/Files) เพื่อป้องกันปัญหา Directory Bloat (การมีไฟล์จำนวนมากเกินไปในโฟลเดอร์เดียว) ซึ่งช่วยให้ File System ทำงานได้เร็วขึ้นและเป็นระเบียบสำหรับผู้ใช้งานที่เข้ามาดูผ่านหน้าเว็บ
การปรับเปลี่ยนสถาปัตยกรรมครั้งนี้ถือเป็นจุดเปลี่ยนสำคัญที่ทำให้ระบบสามารถรองรับข้อมูล 1.3 ล้านฉบับได้อย่างมีประสิทธิภาพ และมีความยืดหยุ่น (Scalable) รองรับข้อมูลที่จะเพิ่มขึ้นในอนาคตได้โดยไม่กระทบต่อประสิทธิภาพการทำงาน
เปลี่ยนภาพให้เป็นข้อความด้วย OCR ภาษาไทย
ปัญหา Scanned PDF: เมื่อข้อมูลเป็นเพียง "รูปภาพ"
แม้จะบริหารจัดการไฟล์จำนวน 1.3 ล้านฉบับได้สำเร็จ แต่โจทย์ใหญ่ถัดมาคือ "รูปแบบของข้อมูล" เอกสารราชกิจจานุเบกษาจำนวนมาก ถูกจัดเก็บในรูปแบบ Scanned PDF ซึ่งในทางคอมพิวเตอร์มองเห็นเป็นเพียงไฟล์รูปภาพ ไม่ใช่ข้อความ ทำให้นักพัฒนาไม่สามารถนำไปทำ Indexing เพื่อค้นหาคำสำคัญ หรือนำไปประมวลผลต่อด้วย NLP ได้ หากไม่ผ่านกระบวนการแปลงภาพเป็นข้อความเสียก่อน
ความซับซ้อนของภาษาไทยและฟอนต์โบราณ
ทางออกคือการใช้เทคโนโลยี OCR (Optical Character Recognition) แต่บริบทของเอกสารราชการไทยมีความท้าทายเฉพาะตัวที่สูงมาก:
- Complex Script: ภาษาไทยมีสระและวรรณยุกต์ซ้อนทับกันหลายระดับ (พยัญชนะ, สระบน, สระล่าง, วรรณยุกต์) ซึ่งเอกสารเก่าที่สแกนมาไม่ชัดมักเจอปัญหาวรรณยุกต์ลอยหรือหางอักษรขาดหาย
- Legacy Fonts: เอกสารยุคเก่าใช้พิมพ์ดีดหรือฟอนต์เฉพาะทาง ซึ่ง OCR Engine ทั่วไปที่เป็น Global Standard มักมีปัญหากับการตัดคำและการอ่านตัวอักษรไทยรูปแบบเก่าเหล่านี้
ความร่วมมือจาก iApp Technology
เพื่อให้ได้คุณภาพข้อมูลที่ดีที่สุด ทีมงานได้รับความอนุเคราะห์จาก iApp Technology บริษัท AI สัญชาติไทย ซึ่งมีความเชี่ยวชาญด้าน Thai OCR ระดับ Enterprise โดยทาง iApp ได้สนับสนุน OCR API Quota ให้โครงการใช้งานได้โดยไม่มีค่าใช้จ่าย เพื่อร่วมเป็นส่วนหนึ่งในการผลักดัน Open Data ของประเทศ
กระบวนการประมวลผลแบบ Background Process
ทีมพัฒนาได้ออกแบบ Data Pipeline บน Synology NAS ให้ทำงานแบบ Asynchronous Background Job โดยค่อยๆ ส่งไฟล์ PDF ย้อนหลังเข้าสู่ API ของ iApp เพื่อประมวลผลทีละหน้าอย่างต่อเนื่อง เพื่อไม่ให้กระทบกับ Traffic หลัก ผลลัพธ์ที่ได้จะถูกบันทึกกลับมาเป็นไฟล์ Text/JSON ที่นักวิจัยสามารถนำไปใช้งานต่อได้ทันที เปลี่ยนเอกสารประวัติศาสตร์ที่เคยเป็นเพียงรูปภาพ ให้กลายเป็น Searchable Data ที่ค้นหา
การออกแบบโครงสร้างข้อมูลเพื่อการเข้าถึงผ่าน CLI
โจทย์ของการเข้าถึงข้อมูล
เมื่อรวบรวมข้อมูลได้ระดับ 1.3 ล้านไฟล์ โจทย์สำคัญคือการออกแบบวิธีการเข้าถึง ให้นักพัฒนาสามารถเลือกดึงข้อมูลเฉพาะส่วนที่ต้องการได้โดยง่าย หากกองข้อมูลทั้งหมดรวมกัน นักพัฒนาที่ต้องการเพียงข้อมูล Text ปีปัจจุบันอาจต้องเสียเวลาดาวน์โหลดไฟล์ ZIP ขนาดใหญ่ทั้งถังเพื่อมาคัดแยกเอง ซึ่งไม่ตอบโจทย์การใช้งานจริง
ทีมงานจึงเลือกใช้วิธีออกแบบ Directory Structure ให้เป็นระบบ เพื่อให้สามารถใช้งานร่วมกับ Hugging Face CLI และ Glob Pattern ในการ Filter ข้อมูลได้ทันทีโดยไม่ต้องพึ่งพา API ที่ซับซ้อน
การจัดโครงสร้าง Directory แบบแยกส่วน
เราจัดระเบียบข้อมูลบน Repository โดยแยกตามประเภทการนำไปใช้งาน ดังนี้:
ocr/: เก็บไฟล์ JSONL ที่ผ่านการทำ OCR แล้ว (มีเฉพาะ Text) เหมาะสำหรับงาน NLP และ AI Trainingmeta/: เก็บไฟล์ Metadata (ชื่อเรื่อง, วันที่, เล่ม/ตอน) เหมาะสำหรับงาน Data Analytics และ Visualizationpdf/(Hot Data): เก็บไฟล์ต้นฉบับย้อนหลัง 3 เดือน เหมาะสำหรับผู้ที่ต้องการตรวจสอบความถูกต้องของเอกสารล่าสุดzip/(Cold Data): เก็บไฟล์ต้นฉบับย้อนหลังตั้งแต่ปี 2428 บีบอัดเป็นรายเดือน เพื่อการจัดเก็บระยะยาว
การใช้งานผ่าน Hugging Face CLI และ Glob Pattern
ข้อดีของการจัดโครงสร้างแบบนี้คือรองรับการใช้ Wildcard (*, ?) ในคำสั่ง CLI ทำให้ผู้ใช้สามารถ "Query" ข้อมูลผ่าน File System ได้เสมือนจัดการไฟล์ในเครื่องตัวเอง
ตัวอย่างคำสั่งสำหรับการใช้งานรูปแบบต่างๆ:
1. สำหรับสาย AI / NLP (ต้องการเฉพาะ Text)
หากต้องการข้อมูล Text ของทศวรรษ 2020s (2020-2029) เพื่อนำไปเทรนโมเดล สามารถใช้ Glob Pattern 202? เพื่อดึงข้อมูลทั้งทศวรรษได้ในคำสั่งเดียว:
# ดึง Metadata ของยุค 2020s
hf download open-law-data-thailand/soc-ratchakitcha --repo-type dataset --include "meta/202?/*" --local-dir "downloads"
# ดึง OCR Text ของยุค 2020s
hf download open-law-data-thailand/soc-ratchakitcha --repo-type dataset --include "ocr/*/202?/*" --local-dir "downloads"
2. สำหรับสาย Data Analyst (ต้องการเฉพาะสถิติ)
หากต้องการวิเคราะห์เทรนด์กฎหมายโดยไม่ต้องการเนื้อหาไฟล์ สามารถสั่งโหลดเฉพาะโฟลเดอร์ meta ทั้งหมดได้ ซึ่งใช้พื้นที่น้อยและรวดเร็ว:
hf download open-law-data-thailand/soc-ratchakitcha --repo-type dataset --include "meta/*/*" --local-dir "downloads"
3. สำหรับสาย Archivist (ต้องการไฟล์ต้นฉบับ)
สามารถเลือกโหลดไฟล์ PDF ล่าสุด หรือไฟล์ ZIP ย้อนหลังได้ตามต้องการ:
# Hot Data (3 เดือนล่าสุด)
hf download open-law-data-thailand/soc-ratchakitcha --repo-type dataset --include "pdf/*/*/*" --local-dir "downloads"
# Cold Data (ย้อนหลัง 100 ปี)
hf download open-law-data-thailand/soc-ratchakitcha --repo-type dataset --include "zip/*/*" --local-dir "downloads"
แนวทางนี้ทำให้ Open Law Data Thailand ทำหน้าที่เป็นเสมือน File System บน Cloud ที่ยืดหยุ่น นักพัฒนาสามารถเลือกหยิบจับส่วนประกอบ (Modular) ที่ต้องการไปใช้งานได้ทันทีโดยไม่ต้องเขียนสคริปต์ที่ซับซ้อน

การพัฒนาเว็บไซต์หน้าบ้าน, พันธมิตร DGA และปรากฏการณ์วันเปิดตัว
สถาปัตยกรรมเว็บไซต์แบบ Stateless และ Real-time Update
แม้ข้อมูลบน Hugging Face จะพร้อมสำหรับนักพัฒนา แต่เพื่อขยายการเข้าถึงไปยังนักวิจัย สื่อมวลชน และประชาชนทั่วไป ทีมงานจึงพัฒนาเว็บไซต์ www.openlawdatathailand.org ให้เป็น User Interface กลาง โดยเลือกใช้สถาปัตยกรรมแบบ Stateless ที่เรียบง่ายแต่ทรงประสิทธิภาพเพื่อลดภาระการดูแลรักษา:
- Status File Trigger: เมื่อ Data Pipeline บน NAS ประมวลผลเสร็จสิ้น (Fetch -> OCR -> Upload) ระบบจะสร้างไฟล์สรุปสถานะ และ Commit ทับไฟล์เดิมบน Repository
- Raw File Fetching: ตัวเว็บไซต์ถูกเขียนให้ดึงข้อมูลจากไฟล์ Status ดังกล่าวมาแสดงผลโดยตรง
วิธีนี้ทำให้หน้าเว็บแสดงสถานะล่าสุดแบบ Real-time ได้ทันทีโดยไม่ต้องพึ่งพา Database แยก และในอนาคตยังสามารถขยายผลทำ Dashboard ติดตาม SLA (Service Level Agreement) ของแต่ละแหล่งข้อมูลได้ง่ายเพียงแค่แยกไฟล์สถานะ
ความยั่งยืนบนโครงสร้างพื้นฐานของ DGA
ในส่วนของ Web Hosting โครงการได้รับความอนุเคราะห์จาก สำนักงานพัฒนารัฐบาลดิจิทัล (องค์การมหาชน) หรือ สพร. (DGA) โดยอนุญาตให้นำ Source Code ขึ้นไปวางบน GitHub Organization ของ DGA-Thailand และใช้บริการ GitHub Pages เป็นโฮสต์หลัก ซึ่งสร้างผลลัพธ์สำคัญ 3 ประการ:
- Credibility: การอยู่ภายใต้ GitHub Organization ของหน่วยงานรัฐ สร้างความมั่นใจให้ผู้ใช้งานว่าเป็นแหล่งข้อมูลที่เชื่อถือได้
- Transparency: การเปิดเผย Source Code เป็น Open Source ช่วยให้ภาคประชาชนสามารถตรวจสอบหรือเข้ามาร่วมพัฒนาได้
- Sustainability: การใช้ GitHub Pages ไม่มีค่าเช่า Server ให้เป็นศูนย์ ทำให้โครงการดำเนินต่อไปได้อย่างยั่งยืน
ปรากฏการณ์วันเปิดตัว: เมื่อ Share มากกว่า Like
เมื่อระบบพร้อมสมบูรณ์ ทีมงานได้ประกาศเปิดตัว (Beta Launch) ผ่านช่องทาง Facebook Post เพื่อแจ้งข่าวสารแก่ Community นักพัฒนา ผลปรากฏว่าได้รับความสนใจอย่างรวดเร็ว โดยสถิติที่น่าสนใจภายใน 24 ชั่วโมงแรกคือ ยอดการแชร์ สูงกว่ายอดกดถูกใจ ถึงกว่า 2 เท่า (900 Shares vs 400 Likes)
ในมุมมองการวิเคราะห์ข้อมูล ตัวเลขนี้บ่งชี้ว่าสังคมไม่ได้มองเนื้อหานี้เป็นเพียง Content ทั่วไป แต่มองเป็น "Resource" ที่มีคุณค่าและต้องเก็บรักษาไว้ใช้งาน สะท้อนให้เห็นถึงความต้องการของนักพัฒนาไทยที่รอคอยโครงสร้างพื้นฐานทางข้อมูลที่มีคุณภาพมาอย่างยาวนาน
ความสำเร็จจากความร่วมมือ
ความสำเร็จของโครงการ Open Law Data Thailand เกิดจากการผนึกกำลังของภาครัฐ ภาคเอกชน และภาคประชาสังคม ที่มีวิสัยทัศน์ร่วมกัน คณะทำงานขอขอบพระคุณ คณะกรรมาธิการการพาณิชย์และการอุตสาหกรรม วุฒิสภา โดย สว.ตวงคุณ ทรงธรรมวัฒน์ ผู้ริเริ่มและผลักดันโครงการ, สำนักเลขาธิการคณะรัฐมนตรี (สลค.) ผู้สนับสนุนข้อมูลราชกิจจานุเบกษา, และ สำนักงานพัฒนารัฐบาลดิจิทัล (สพร./DGA) ผู้สนับสนุนโครงสร้างพื้นฐานดิจิทัลและพื้นที่เว็บไซต์
นอกจากนี้ ขอขอบคุณภาคเอกชนที่สนับสนุนทรัพยากรด้านเทคโนโลยี ได้แก่ สภาอุตสาหกรรมจังหวัดสมุทรสงคราม (สนับสนุน Synology NAS สำหรับประมวลผล), UpPass (สนับสนุนองค์ความรู้ด้าน Data Engineering), iApp Technology (สนับสนุนระบบ AI OCR ภาษาไทย), และ StockRadars (สำหรับการประสานงานเครือข่ายความร่วมมือด้านเทคโนโลยี)

ก้าวต่อไปสู่ "มาตรฐานข้อมูลแห่งชาติ"
ความสำเร็จของ Dataset ชุดแรกเป็นเพียง Proof of Concept ที่พิสูจน์แล้วว่าความร่วมมือระหว่างภาคประชาชนและภาครัฐนั้นเป็นไปได้ ขณะนี้ทีมงานกำลังเตรียมจัดตั้ง "คณะทำงานชุดที่ 2" เพื่อขยายผลไปยังหน่วยงานภาครัฐอื่นๆ โดยมีภารกิจหลักในการเฟ้นหาข้อมูลสาธารณะที่ยังติดขัดเรื่องรูปแบบการจัดเก็บ เพื่อนำมาเข้าสู่กระบวนการ Data Pipeline และปลดปล่อยข้อมูลเหล่านั้นให้เป็น Open Data ที่ใช้งานได้จริง
อย่างไรก็ตาม เป้าหมายสูงสุดของเราไม่ใช่การทำโครงการนี้ไปตลอดกาล แต่คือการผลักดันให้เกิด "Standard Protocol" ของภาครัฐ กฎหมายและเอกสารราชการทุกฉบับควรเป็น Machine-Readable ตั้งแต่วันแรก และมี API กลางที่เชื่อมต่อได้ทันที เมื่อถึงวันที่รัฐบาลดิจิทัลเกิดขึ้นอย่างสมบูรณ์ บทบาทของคนกลางอย่างเราอาจหมดไป ซึ่งนั่นคือความสำเร็จที่แท้จริงที่พวกเราอยากเห็น
สุดท้ายนี้ โครงการยังต้องการพลังอาสาเพื่อขับเคลื่อนต่อ ผมขอเชิญชวนนักพัฒนาเข้ามาร่วม Community ใน Discord เพื่อช่วยกันปรับปรุง Pipeline หรือแจ้งบั๊ก และที่สำคัญที่สุดคือขอเชิญชวนให้ "สร้างของที่ใช้ได้จริง" ไม่ว่าจะเป็น AI Legal Advisor, ระบบแจ้งเตือนกฎหมายใหม่ หรือเครื่องมือวิเคราะห์ Regulatory Guillotine เพื่อพิสูจน์ให้สังคมเห็นว่า Open Data สามารถสร้างมูลค่าทางเศรษฐกิจและสังคมได้จริง
Open Law Data Hackathon 2026
เพื่อให้ข้อมูลที่เปิดออกมาเกิดประโยชน์สูงสุด ทางคณะทำงานมีแผนจะจัดงาน "Open Law Data Hackathon" ในช่วง ต้น-กลาง ปี 2026
ขอเชิญชวนนักพัฒนา นิติกร Data Scientist และ นักเรียนนักศึกษา เตรียมตัวมาร่วมทีมกันสร้างนวัตกรรมจากข้อมูลกฎหมาย ไม่ว่าจะเป็น AI Lawyer Assistant, Regulatory Guillotine หรือเครื่องมืออื่นๆ ตามจินตนาการ
เตรียมพบกันเร็วๆ นี้ ท่านสามารถติดตามข่าวสารการรับสมัครได้ผ่านทาง Discord ของโครงการ
ช่องทางติดตามโครงการ
- Website: https://openlawdatathailand.org
- Discord: https://openlawdatathailand.org/discord/
โครงการ Open Law Data Thailand เป็น "สมบัติของทุกคน"... นี่คือพันธกิจที่เราจะร่วมกันผลักดันให้เกิดบรรทัดฐานใหม่ เพื่อให้ข้อมูลของภาครัฐเป็นสิ่งที่ทุกคนเข้าถึงได้ง่าย และนำไปต่อยอดให้เกิดประโยชน์ได้จริง


























มีปรับแก้สักหน่อยครับ …
lew Thu, 01/01/2026 - 12:44
มีปรับแก้สักหน่อยครับ
โดยรวมๆ บทความอาจจะสั้นลงกว่านี้ครับ ตัดส่วนซ้ำซ้อนออกบางส่วน ส่วนขอบคุณอาจจะเป็นย่อหน้าเดียวกันเพื่อลดพื้นที่ลง
ผมได้ปรับบทความตามคำแนะนำแล้…
spicydog Thu, 01/01/2026 - 23:00
In reply to มีปรับแก้สักหน่อยครับ … by lew
ผมได้ปรับบทความตามคำแนะนำแล้ว รบกวนคุณ Lew ช่วยรีวิวให้อีกครั้งครับ ขอบคุณครับ
เอาขึ้นเรียบร้อยครับ
lew Fri, 02/01/2026 - 16:11
In reply to ผมได้ปรับบทความตามคำแนะนำแล้… by spicydog
เอาขึ้นเรียบร้อยครับ
ขอบคุณครับ <3
spicydog Fri, 02/01/2026 - 16:16
In reply to เอาขึ้นเรียบร้อยครับ by lew
ขอบคุณครับ <3
มี ความเหน , ว่า …
tontpong Fri, 02/01/2026 - 19:33
มี ความเหน , ว่า ..
ชื่อโครงการ ลองตั้ง ให้มี , คำว่า 1) ai กับ 2) ภาครัฐ 🤓 .. ด้วยชื่อประมาณนี้ หน่วยงานที่จะไปติดต่อเพิ่ม , ช่วงนี้ คง คุยปุ้บติดปั้บ 😉 ( อาจจะคุยติด ทั้งที่เค้ายังไม่เข้าใจโครงการด้วยซ้ำ -- ไม่แน่ใจ ว่า ถือเป็นข้อดีหรือข้อเสีย 😅 )
front page / hot zone , มี 3 ส่วน ..
key founder & partner .. 1-2 line ( รวม logo / profile pic แล้ว ) , พร้อม link ไป timeline แบบที่ละเอียดขึ้นยาวขึ้น ( เพื่อเป็น พื้นที่ ให้ founder/partner ส่วนที่รองลงมา )
top5/top10 & more สำหรับ รายชื่อหน่วยงาน ที่ ส่งข้อมูลก้อนแรกเข้ามา ( ใส่ logo/profile pic ได้ด้วย ) .. เพื่อ กระตุ้น ให้ รีบตัดสินใจร่วม ( ครั้งแรก สำคัญเสมอ -- อกหักสิบครั้ง ครั้งแรกไม่เคยลืม 💔 #ผิด )
top5/top10 & more สำหรับ หน่วยงาน ที่ ส่งข้อมูลก้อนล่าสุดเข้ามา ( ใส่รุปได้เช่นกัน ) .. เพื่อ กระตุ้น ให้ หมั่นส่งข้อมูลใหม่ ( มี link ใป history สำหรับ batch ของ ก้อนข้อมูล ที่ ส่งแต่ละครั้ง ด้วย , เพื่อ สะท้อนและกระตุ้น ลักษณะของการมีปฏิสัมพันธ์ )
อาจจะเป็น โครงการคู่ขนาน ก็ได้ .. ใช้อันใหม่นี้เป็น ช่องทางประชาสัมพันธ์หลักกับสาธารณะวงกว้าง เช่น สนข/อินฟลู/social media ( ใช้เป็นส่วน pr -- public relation ) , ส่วนอันตอนนี้ ใช้กับ คนลงงาน/nerd/geek/maker ( event สายเทคหรือคนลงมือ อย่าง hackathon -- ก็ใช้ ทั้งสองชื่อ คุ่กัน )
ถ้าเผอิญ mass , คนที่แค่อยากออกแรงแต่ไม่อยากออกหน้า จะเบาตัวเบาหัว 🥹 .. ถ้าเผอิญ fail , ก็แค่ตั้งชื่อใหม่มาแทน แต่ว่าส่วนเนื้องานยังเหมือนเดิม 😎 ( หากต้องมีชื่อใหม่ในอนาคต -- จะใช้คำอื่นแทน หรือยังมีคำว่า ai กับ ภาครัฐ , ก็แล้วแต่ คำฮิต ใน ช่วงนั้น )
ขอบคุณสำหรับข้อเสนอครับ
spicydog Fri, 02/01/2026 - 23:54
In reply to มี ความเหน , ว่า … by tontpong
ขอบคุณสำหรับข้อเสนอครับ
ใช้ NAS ให้เป็น Server…
blackdoor Fri, 02/01/2026 - 19:49
บทความอย่างปั่น
โอเค ถ้าแยก NAS เอาไว้เก็บ object storage และใช้เครื่องอื่น ๆ เป็น compute node น่าจะเข้าท่ากว่า
ส่วน NAS ก็มีทั้งสำเร็จ และประกอบเอง ส่วน Software NAS ก็มีแบบ open source เช่นกัน
ใช้ NAS ให้เป็น Server ? …
spicydog Fri, 02/01/2026 - 23:51
In reply to ใช้ NAS ให้เป็น Server… by blackdoor
ใช้ NAS ให้เป็น Server ?
Synology NAS
กระจาย worker ให้ compute
ถ้าแยก NAS เอาไว้เก็บ object storage และใช้เครื่องอื่น ๆ เป็น compute node น่าจะเข้าท่ากว่า
โอเคข่าวนี้เขียนจาก AI
เข้าใจครับ …
blackdoor Sat, 03/01/2026 - 00:20
In reply to ใช้ NAS ให้เป็น Server ? … by spicydog
เข้าใจครับ (ตอนแรกก็คิดอยู่ว่า jobs run ไม่น่าเยอะ เลยคิดใช้ NAS เป็นหลัก)
แต่แนวคิด pipeline ส่วนใหญ่ ที่ต้องรอ เป็นแนวกระจาย worker ครับ ผมเลยพูดไปแบบนั้น แต่ก็ไม่แปลกใจ เพราะถ้าไม่ลงรายละเอียดเรื่องนี้เอง AI คงไม่แนะนำ
แต่นั่นไม่ใช่ประเด็นหลัก ของเม้น ที่บอกว่าประหยัดที่อยู่ในเนื้อหาครับ
ยังไงผมก็ว่าไม่ใช่ ถ้าเป็นเรื่องความสะดวกก็ว่าไปอย่าง
และ object storage ก็ไม่ใช่ประเด็นอะไร ไม่เกี่ยวกับเนื้อหาข่าวด้วย
เป็นแค่ที่วิธีผมเสนอ เพื่อประโยชน์ใช้สอยในอนาคต (จริง ๆ ต้องไปอ่าน object storage เพิ่มเติมคืออะไร หรือลองถาม AI ดูก็ได้)
ย่อยแปป
orchidkit Sat, 03/01/2026 - 02:59
ย่อยแปป
โอ้วว iApp อาจารย์ผมเอง
9rockky Sat, 03/01/2026 - 15:28
โอ้วว iApp อาจารย์ผมเอง
จะมีแผน ocr ราชกิจจายุคแรก ๆ…
vesinah Sat, 03/01/2026 - 18:06
จะมีแผน ocr ราชกิจจายุคแรก ๆ ไหมครับ หรือทำเฉพาะ metadata อย่างเดียว