เมื่อวันที่ 4 มกราคมที่ผ่านมา Slack เกิดเหตุล่มนานนับชั่วโมง และไม่เสถียรนานเกือบ 5 ชั่วโมง หลังจากสอบสวนสาเหตุจนเรียบร้อยทาง Slack ก็ออกรายงานสาเหตุของการล่มครั้งนี้ โดยระบุว่าเกิดจาก AWS Transit Gateways (TGW) ที่ไม่สามารถขยายตามโหลดที่ใช้งานจริงได้ทัน และระบุถึงกระบวนการแก้ปัญหาที่ระหว่างทางทีมงานยังไม่ทราบสาเหตุที่แท้จริง
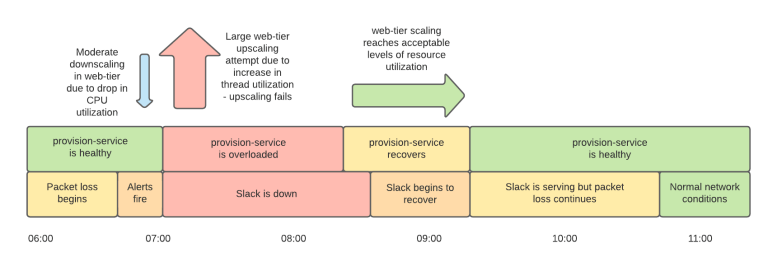
Slack ระบุว่าเริ่มเห็นว่าเน็ตเวิร์คมีปัญหามาระยะหนึ่ง อัตราการส่งข้อความสำเร็จลดลงจาก 99.999% เหลือ 99% แต่เน็ตเวิร์คที่มีปัญหากลับทำให้ระบบมอนิเตอร์คิดว่าเซิร์ฟเวอร์มีปัญหาและไล่ปิดเครื่องทิ้ง ขณะที่ระบบ autoscaling ตรวจดูการใช้งานซีพียูแล้วพบว่ามีโหลดน้อยลง (เนื่องจากรอเน็ตเวิร์คตอบกลับ) ทำให้ระบบ autoscaling เริ่มปิดเครื่องทิ้ง แต่หลังจากนั้นเธรดเน็ตเวิร์คก็รันเต็มเซิร์ฟเวอร์ที่เหลืออยู่จนระบบ autoscaling พยายามขยายคลัสเตอร์อย่างหนักจนระบบตายเนื่องจากซอฟต์แวร์เองและโควต้าของ AWS
สาเหตุสำคัญของเหตุครั้งนี้คือรูปแบบโหลดของ Slack เองที่จะมีโหลดหนักทุกต้นชั่วโมงจาก bot ต่างๆ และยิ่งในวันจันทร์หลังหยุดยาวปีใหม่ โหลดจำนวนมากก็กลับมา ระหว่างที่วิศวกรของ Slack กำลังไล่แก้ปัญหานี้ วิศวกรของ AWS ก็แก้ปัญหาเน็ตเวิร์คให้ไปพร้อมกัน
ทาง Slack ระบุว่า AWS กำลังรีวิวอัลกอริทึมสำหรับการขยายแบนวิดท์ให้ TGW เพื่อให้ไม่เกิดปัญหาเช่นนี้อีก และทาง Slack เตรียมการแจ้งขยายแบนวิดท์ล่วงหน้าหลังวันหยุดยาว
ที่มา - Slack Engineering