งานวิจัยจาก Sandia National Laboratories พบว่าการเพิ่มจำนวนคอร์ของซีพียูอย่างรวดเร็ว จนไม่ทันกับแบนด์วิธของหน่วยความจำ กลับทำให้ประสิทธิภาพโดยรวมของระบบช้าลง
ปัญหานี้เป็นปัญหาที่รู้จักกันมาในวงการซีพียูมานานแล้ว มันคือ "memory wall" ซึ่งหลักการง่ายๆ มีอยู่ว่า แบนด์วิธรวมในการประมวลผลของซีพียู (นับทุกคอร์ หรือทุกเธร็ด) จะต้องมีขนาดได้ดุลกับแบนด์วิธการส่งข้อมูลจากหน่วยความจำด้วย ระบบจึงจะทำงานได้อย่างมีประสิทธิภาพ
ปัญหาคือแบนด์วิธการคำนวณของซีพียูนั้นเติบโตตามกฎของมัวร์ แต่แบนด์วิธของหน่วยความจำนั้นกลับโตขึ้นปีละประมาณ 10% เท่านั้น ซึ่งในท้ายที่สุดจะทำให้ถึงจุดที่เกิดคอขวดที่หน่วยความจำ
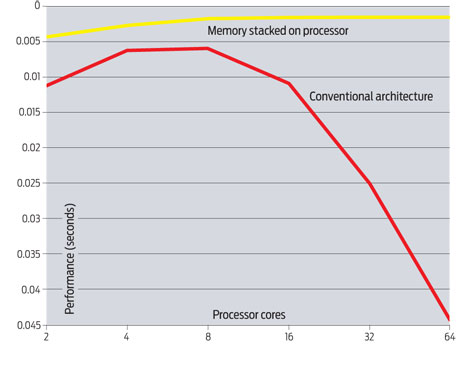
ในโลกยุคมัลติคอร์แบบปัจจุบัน ที่จำนวนคอร์ของซีพียูเพิ่มขึ้นอย่างรวดเร็ว การวิจัยของ Sandia National Laboratories พบว่าจุดสมดุลที่ดีที่สุดในขณะนี้อยู่ที่ 8 คอร์เท่านั้น ถ้าเพิ่มจำนวนคอร์เป็น 16 คอร์ (โดยใช้สถาปัตยกรรมหน่วยความจำแบบในปัจจุบัน) ประสิทธิภาพรวมจะลดลงเหลือเท่ากับระบบที่ใช้ 2 คอร์ แต่ถ้าเพิ่มคอร์มากขึ้นไปอีกเป็น 32 หรือ 64 คอร์ ประสิทธิภาพรวมจะลดลงไปอีกมาก (ดูกราฟง่ายกว่า อยู่ด้านใน)
ทางแก้ก็ต้องปรับปรุงวิธีการเชื่อมต่อหน่วยความจำให้ดีกว่านี้ ซึ่งทาง Sandia เสนอให้วางทับไปบนซีพียูเลย เพื่อลดปัญหา interconnect
ที่มา - IEEE Spectrum ผ่าน Ars Technica


























เห็น Intel
Thaina Mon, 08/12/2008 - 14:58
เห็น Intel ทำเป็นว่า ทุก Core มีหน่วยความจำในตัว ตั้งแต่แรกแล้วนี่ครับ??
ที่มาโชว์ 128 คอร์เมื่อช่วงก่อนๆน่ะ
ที่บ้านยั
jirayu Mon, 08/12/2008 - 15:14
ที่บ้านยังใช้ P4 อยู่เลยครับ เหอๆ
เป็นงั้นไ
wklk Mon, 08/12/2008 - 15:21
เป็นงั้นไป...
ดูจากกราฟ
7ingN0ngN0i Mon, 08/12/2008 - 15:24
ดูจากกราฟ 4 คอร์ กับ 8 คอร์ ก็แทบจะไม่แตกต่าง
ผมเคยเจอ
javaboom Mon, 08/12/2008 - 15:40
ผมเคยเจอ paper ที่กล่าวประมาณนี้แล้ว และเขาก็สรุปว่าซีพียูไม่ควรมีเกิน 16 คอร์ แต่ถ้าเรามองไปที่ HPC บน cluster แบบดั่้งเดิมก็ประสบปัญหาเช่นนี้เหมือนกัน เขาเลยต้องเพิ่มแบนด์วิธของเครือข่าย แต่วิธีแก้อีกอย่างคือการออกแบบซอฟต์แวร์ด้วยครับ เพราะซอฟต์แวร์จะต้องจูนให้พอเหมาะกับจำนวนคอร์ อีกวิธีคือลดการเกิด page fault โดยการจัดการ cache ให้มีประสิทธิภาพ
ผมคิดว่าการทดลองที่แสดงด้านบน เขาเอาโปรแกรมที่เป็นงานประเภทเน้นเขียนหรือปรับปรุงข้อมูลบนแรมบ่อยๆ หรือไม่ก็ทุกๆ process ก็ต้องเข้าถึงแรมพร้อมๆกันและก็ถี่ ... ถ้าหากสถาปัตยกรรมโปรเซสเซอร์ไม่ยัดเมมหรือแคชที่พอเหมาะให้แต่ละคอร์ จะเป็นปัญหาใหญ่ที่โปรแกรมเมอร์ต้องมานั่งจ้ดการวิธี synchronization และที่สำคัญประสิทธิภาพการประมวลผล (สัดส่วนคำนวณอนุกรมต่อคำนวณขนาน) จะไม่ได้เต็มที่หรือห่างจาก 100% พอประมาณ แต่ถ้าไม่ทำ synchronization ก็ต้องแลกกับคอขวด ซึ่งผลเสียจะมีมากขึ้น และอาจจะเกิดปัญหา traffic congestion ที่เป็นปัญหาปวดหัวบนระบบเครือข่าย แต่อันนี้เกิดคอขวดบนระดับซีพียูเลย
JavaBoom (Boom is not Java, but Java was boom)
http://javaboom.wordpress.com
ถูกต้องนะ
mk Mon, 08/12/2008 - 19:13
In reply to ผมเคยเจอ by javaboom
ถูกต้องนะครับ ในกราฟจะเห็นชัดว่า มีตัวหนังสือระบุชัดเป็น conventional architecture
อืม
pawinpawin Mon, 08/12/2008 - 16:00
อืม อาจมีอะไรดีๆ อยู่ในแล็บอินเทลที่แก้ปัญหานี้แล้วก็ได้
___________pawinpawin
core i7 architect ?
baggio Mon, 08/12/2008 - 16:01
core i7 architect ?
คงไม่ได้ช
polaromonas Mon, 08/12/2008 - 19:11
In reply to core i7 architect ? by baggio
คงไม่ได้ช่วยหรอกครับ
ในเมื่อ Core i7 microarchitecture ก็คือ K10 ของ intel ดีๆนี่เอง -*-
น่าจะรวมท
azx Mon, 08/12/2008 - 16:08
น่าจะรวมทั้งหมดอยู่ทุกอย่างอยู่ใน chip เดียวเลย(cpu gpu ram hdd)
ระวังชิบห
zyenite Mon, 08/12/2008 - 16:24
In reply to น่าจะรวมท by azx
ระวังชิบหายนะครับ :P (ชิบ + หาย)
อื้ม ..
khajochi Mon, 08/12/2008 - 16:25
อื้ม .. คงต้องเพิ่มหน่วยความจำตามจำนวนของคอร์สิเนี่ย
---
Khajochi Blog : It's not a Bug ... It's a Feature
เค้าหมายถ
winggundamth Mon, 08/12/2008 - 16:54
In reply to อื้ม .. by khajochi
เค้าหมายถึงแบนด์วิธของหน่วยความจำ ไม่ใช่ขนาดของหน่วยความจำไม่ใช่เหรอครับ หรือว่าผมเข้าใจผิด??
I will change the world, to the better day.
ใน Terascale
lew Mon, 08/12/2008 - 17:45
In reply to อื้ม .. by khajochi
ใน Terascale ของอินเทล เองถึงเสนอทางออกเป็นการเชื่อมต่อแรมแบบสามมิติ ให้ทุกคอร์ต่อกับแรมที่วางอยู่ข้างใต้ได้โดยตรงน่ะครับ
ปัญหาสำคัญคือ ไอ้สถาปัตยกรรมแบบนี้จะมาถึงซีพียูในตลาดเมื่อใหร่กัน
LewCPE
มันก็เหมื
rattananen Mon, 08/12/2008 - 17:06
มันก็เหมือนโรงปะปาที่มีเครื่องกรองน้ำอยู่ 2-3เครื่อง แล้วอยู่ดีๆเพิ่มเป็น 16เครื่อง
คุณจะเอาท่อน้ำที่ไหนจ่ายน้ำให้มันทั้ง 16เครื่องล่ะ?
แล้วอีกอย่างผมว่าคิดว่า CPU ไม่จำเป็นต่อเครื่องที่ใช้ในชีวิตประจำวันเท่าไร
RAM, bus, VGA card จำเป็นกว่าอีกครับไม่เชื่อลองดูได้
เครื่องไหนที่เล่นเกมส์แล้วกระตุกลองเพิ่ม RAM, UP VGA card ดู
ส่วนมากหายกระตุก
ดูจากกราฟ 4 core ก็พอแฮะสำหรับตอนนี้และอนาคตอันใกล้
celeron ต่อไป
lnwbleach Mon, 08/12/2008 - 17:47
celeron ต่อไป อิอิ
อาจจะแก้เ
AdmOd Mon, 08/12/2008 - 18:03
อาจจะแก้เป็นเสมือนมีเมนบอร์ด 2 ตัวในตัวเดียว เป็น Dual Chipsets, Dual Memory Controllers, Dual บลาๆๆๆ
เป็น Home Cloud ไป
แก้โดยให้
DoraeMew Mon, 08/12/2008 - 18:26
แก้โดยให้แต่ละคอร์มี memory controller และ memory ของตัวเองไม่ได้เหรอ - -?
เจอปัญหาแ
7 Mon, 08/12/2008 - 21:34
เจอปัญหาแล้ว ก็หาทางแก้กันไป อย่างเราๆทั่นๆ ก็คอยฟังข่าวแล้วซื้อมาใช้ให้เหมาะกับงาน เหมาะกับกระเป๋าสตางค์ ก็พอใจแระ
7blogger.com
ผมเข้าใจว
somsak_sr Mon, 08/12/2008 - 21:39
ผมเข้าใจว่าถ้าไปเพิ่มให้มี memory ในแต่ละ core เอง มันแก้ปัญหาได้ระดับนึง แต่ผมว่ามันเป็นกึ่งๆการ "เลี่ยงปัญหา" คือ ผลักภาระให้ software ไปหาทางจัดการ processor เอาเองให้มีประสิทธิภาพในการจัดการ ram
ตรงนี้ผมเข้าใจว่ามันแก้ไปบ้างแล้ว คือใน kernel มักจะมีการ schedule และมีการ set พวก affinity ทำให้การจอง memory มันมักจะใช้ตัวที่อยู่กับ CPU เองไว้ก่อน ซึ่งวิธีง่ายๆนี้ก็ได้ผลกับ app ทั่วๆไปตอนนี้ที่รันกัน 1 thread แล้วก็ใช้ ram พอประมาณ แต่ถ้าเกิด app หันกันมาเขียนแบบ multi thread กันมากๆ การคุยกันข้าม cpu ก็จะเกิดอยู่ดี
ปัญหาคือ thread model ในปัจจุบันผมเข้าใจว่ายังมีวิธีการทำ communication ง่ายๆคือคุยกันผ่าน global/heap ของโปรแกรม เพราะงั้นถ้าเจอ app ประเภทหลาย thread ที่จำเป็นต้องใช้ cpu หลายๆ core ช่วยให้รันได้เร็วขึ้นจริงๆ มันจะกลายเป็นว่ารันแล้วไม่ค่อยเร็วขึ้นเท่าไหร่เพราะมันก็ต้องคุยกันผ่าน bus ที่เป็นคอขวดอยู่ดี
ผมจำได้เลาๆว่าตอนคลัสเตอร์ ปัญหานี้ถูกแก้ไปพร้อมๆกับการมาของ infiniband โดยระหว่างนั้นก็มีพวก elan, myrinet ขัดตาทัพไปก่อน แล้วพวก app ก็หันมาขยันทำ parallelize กันซะจนปัจจุบันแทบหา HPC app ที่ไม่เป็น parallel ไม่เจอ แต่ถ้ามาเกิดในระดับ multi core ซึ่งไม่มี programming language พิเศษ การแก้ในระดับซอฟต์แวร์น่าจะลำบาก เพราะแม้กระทั่งในปัจจุบัน พวกภาษาหรือคอมไพเลอร์ที่ทำ parallelize อัตโนมัติก็ยังทำได้ไม่ค่อยดี ผมเข้าใจว่าพวกภาษากึ่งๆอย่าง OpenMP ประสิทธิภาพก็ยังด้อยกว่าเขียนเป็น MPI แต่แรก อันนี้ผมสังเกตจากที่ว่า App ส่วนใหญ่หันมาเขียนเป็น MPI กันหมดนะครับ
พอไปอ่าน lew's blog เรื่อง terascale ก็พบว่าดูเหมือนเขาจะคิดแบบนี้เหมือนกัน เลยแก้ปัญหาโดยการเพิ่ม bandwidth แบบมหาศาลและเปลี่ยนรูปแบบการเชื่อมต่อแต่ละ core ไปเลย
ปีที่แล้ว
sugree Tue, 09/12/2008 - 00:47
ปีที่แล้วเห็นว่าเชื่อมโปรเซสเซอร์กับหน่วยความจำด้วยไฟเบอร์ เร็วปรู๊ด
วิธีอ่ะผม
zda98 Tue, 09/12/2008 - 09:03
วิธีอ่ะผมว่ามีแล้วแต่มันแพงเลยยังไม่สามารถนำมาใช้งานกับเครื่องตามบ้านได้เช่น Switch แบบ Infiniband ที่ใช้ในระบบ Cluster ก็น่าจะแก้ไขได้บ้างนะครับ
infiniband
somsak_sr Tue, 09/12/2008 - 22:59
In reply to วิธีอ่ะผม by zda98
infiniband ถ้าเทียบกับ bandwidth ใน CPU ยังช้านะครับ ได้แค่หลัก 20Gbps เอง อย่างใน terascale นี่ซัดไประดับ TB ครับ