หลังการสาธิตชิประดับ 80 คอร์จากอินเทลด้วยกระแสที่ออกมาเกี่ยวกับการออกแบบ Tiled CPU อย่างต่อเนื่อง ทำให้มีความเป็นไปได้เป็นอย่างยิ่งกว่าเราจะได้เห็นชิปเช่นนี้ในตลาดหลักกันในไม่ช้า ด้วยแนวคิดใหม่ที่ต่างจากการออกแบบชิปแบบมัลติคอร์แบบเดิมๆ ที่ใช้คอร์ความเร็วสูงหลายชุดมาต่อกัน ทำให้ได้ความเร็วที่ดีไม่ว่าจะเป็นการรันโปรแกรมแบบเธรดเดียวในแบบเดิมๆ หรือจะเป็นการรันโปรแกรมแบบหลายเธรดที่ทำให้สามารถใช้งานทุกคอร์ได้อย่างเต็มประสิทธิภาพ แต่การออกแบบ Tiled CPU จะเป็นการออกแบบเพื่อการใช้งานโปรแกรมหลายเธรดโดยเฉพาะ แม้จะทำให้การรันโปรแกรมแบบเธรดเดียวช้าลงไป แต่ประสิทธิภาพในหลายๆ ด้านที่ได้กลับมากลับน่าสนใจเป็นอย่างยิ่ง ก่อนที่ซีพียูในรูปแบบสถาปัตยกรรมเช่นนี้จะมีขายตามห้างไอที เรามาดูกันก่อนดีกว่าว่าการออกแบบชิปแบบใหม่นี้แตกต่างและดีกว่าแบบเดิมๆ อย่างไร
หลังการเปิดตัวชิปแบบมัลติคอร์ไปไม่นาน เป็นที่รู้กันดีว่าการเพิ่มจำนวนคอร์เข้าไปในซีพียูเพื่อเร่งความเร็วเครื่องนั้นจะพบกับขีดจำกัดที่ประมาณ 16 คอร์เนื่องจากคอขวดอื่นๆ เช่น การสื่อสารระหว่างคอร์ การอ่านหน่วยความจำ ตลอดจนข้อจำกัดอื่นๆ เช่นการใช้พลังงานที่สูงขึ้นเรื่อยๆ เพื่อการก้าวข้ามขีดจำกัดเหล่านี้ งานวิจัยใหม่ๆ ตั้งแต่ปี 2004 ถึงปี 2006 ที่ผ่านมาจึงมีการเสนอถึงการออกแบบ Tiled Processor (TP)
ก่อนอื่นเราควรรู้ว่าเทคโนโลยีซีพียูนั้นพยายามประมวลผลแบบขนานโดยโปรแกรมเมอร์ไม่รู้ตัวมาก่อนหน้าที่การออกแบบแบบมัลติคอร์จะได้รับความนิยมเป็นอย่างสูง เช่น Superscalar ที่ตัวซีพียูสามารถตัดสินใจทำงานหลายๆ อย่างพร้อมกันได้โดยผลลัพธ์ไม่แตกต่างจากการทำงานปรกติ หรือจะเป็นเทคโนโลยี VLIW ที่สร้างการทำงานแบบขนานด้วยการให้คอมไพล์เลอร์จัดเรียงคำสั่งให้ซีพียูสามารถดึงเข้าไปทำงานได้ทีละหลายคำสั่งโดยไม่มีผลต่อผลลัพธ์อีกเช่นกัน ปัญหาหลักคือการเพิ่มความเร็วในการทำงานด้วยเทคโนโลยีเหล่านี้มีข้อจำกัดที่ไม่สามารถขยายความเร็วระบบได้อย่างอิสระ และที่แย่กว่านั้นคือการออกแบบเช่นนี้ลดประสิทธิภาพการใช้พลังงานลงเป็นอย่างมาก
การแก้ปัญหาในตอนนี้จึงมีการเสนอการใช้งานซีพียูหลายคอร์ขึ้นมาเพื่อให้ระบบสามารถขยายได้โดยง่าย เช่นการใช้ซีพียูดูอัลคอร์ในทุกวันนี้ ปัญหาคือการเขียนโปรแกรมที่ทำงานแบบเธรดนั้นค่อนข้างยาก และการใช้งานจริงจะมีข้อจำกัดเช่นคอขวดของการส่งผ่านข้อมูลระหว่างคอร์ เนื่องจากทุกคอร์นั้นต้องส่งข้อมูลผ่านบัสร่วมกัน
Tiled Processor แก้ปัญหาทั้งหมดด้วยการออกแบบคอร์ขนาดเล็กจำนวนมาก โดยแต่ละคอร์นั้นมีการเชื่อมต่อกับคอร์ข้างเคียงในรูปแบบตาราง ทำให้ทุกคอร์สามารถส่งข้อมูลไปยังคอร์ข้างเคียงได้ค่อนข้างเร็วมาก
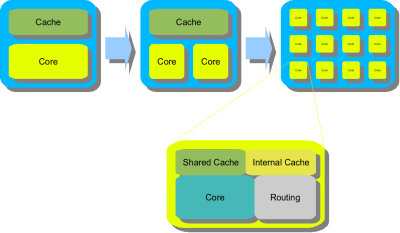
พัฒนาการจากคอร์เดี่ยวมาถึง Tiled Processor
ข้อดีของการออกแบบซีพียูแบบนี้คือการที่ตัวซีพียูแต่ละคอร์สามารถทำงานเฉพาะอย่างได้โดยยังสามารถส่งข้อมูลไปยังซีพียูที่ต้องการประมวลผลอื่นๆ ต่อไปได้อย่างมีประสิทธิภาพ เนื่องจากเส้นทางการส่งข้อมูลที่สามารถออกแบบให้สั้นเข้าด้วยการวางคอร์ที่ต้องทำงานต่อเนื่องกันให้อยู่ติดกัน โดยแบ่งการทำงานออกเป็นกลุ่มๆ ได้ตามความต้องการของซอฟต์แวร์ที่รันอยู่ในเครื่องขณะนั้นๆ นอกจากการแบ่งการทำงานเป็นกลุ่มแล้ว การแบ่งส่วนของซีพียูออกเป็นตารางยังทำให้เมื่อเกิดปัญหาขึ้นกับบางคอร์ในกระบวนการผลิต ผู้ผลิตยังมีโอกาสที่จะปิดการทำงานของคอร์นั้นโดยยังคงส่งชิปตัวนั้นสู่ตลาดได้ ตรงนี้เป็นกระบวนการแบบเดียวกับชิป Cell ของ PS3 ที่มี SPE ทำงานอยู่ 7 ชุดทั้งที่ผลิตไว้บนตัวชิปถึง 8 ชุด เพื่อลดการคิดทิ้งในกระบวนการผลิต

การจัดกลุ่มการทำงานของคอร์ใน Tiled Processor
ที่น่าสนใจอีกประการหนึ่งคือการเข้าถึงหน่วยความจำแบบ NUMA ของชิป Terascale ที่ทางอินเทลได้ออกแบบนี้ เป็นการเชื่อมต่อระหว่างหน่วยความจำกับซีพียูแต่ละคอร์โดยตรง จากการผลิตที่เป็นแผ่นเวเฟอร์ประกบกัน ทำให้แต่ละคอร์ของ Terascale สามารถส่งข้อมูลเข้าสู่หน่วยความจำได้ด้วยความเร็ว 40 กิกะไบต์ต่อวินาทีในแต่ละคอร์ เมื่อรวมกันแล้วทำให้ชิป Terascale มีการส่งข้อมูลกับหน่วยความจำด้วยแบนวิดท์สูงสุดถึง 3 เทราไบต์ต่อวินาทีเลยดีเดียว
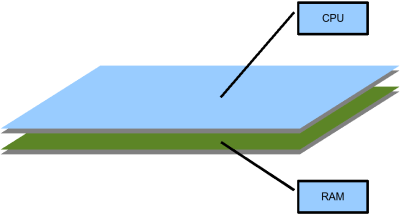
การผลิตที่วาง DRAM ไว้ใต้ซีพียูโดยตรงทำให้แต่ละคอร์สามารถติดต่อกับแรมได้ด้วยตัวเอง
ถ้าสังเกตุดูสถาปัตยกรรมของ Terascale แล้วเราอาจจะเห็นความหคล้ายคลึงกับชิป Cell ของ PS3 อยู่หลายประการ โดยความแตกต่างหลักๆ นั้นคือ Cell มีหน่วยประมวลผล PPE ที่เป็นชิปหลักไว้จัดการระบบโดยรวม และการสื่อสาร์ระหว่างคอร์ย่อยๆ นั้นก็เป็นการติดต่อผ่าน Element Interconnection ที่อยู่ตรงกลาง แต่ชิปอย่าง Terascale นั้นกลับมีการกระจายการทำงานออกจากกันทุกอย่างไม่ว่าจะเป็นการที่ชิปไม่มีคอร์ศูนย์กลางโดยแท้จริง หรือจะเป็นการสื่อสารระหว่างคอร์ที่แยกอิสระ
การออกแบบอย่างอิสระเช่นนี้ ทางอินเทลอ้างว่าจะทำให้เครื่องคอมพิวเตอร์ในยุคต่อไปสามารถทำงานแบบขนานได้อย่างสมบูรณ์แบบ ไม่ว่าจะเป็นการรันระบบปฏิบัติการขนานกัน หรือแม้กระทั่งการแตกงานจากเธรดเดียวกันออกไปประมวลผลในหลายๆ คอร์ด้วยความช่วยเหลือของคอมไพล์เลอร์ก็ตาม
การเดโมของทางอินเทลให้ผลลัพธ์ที่ค่อนข้างหน้าตื่นตาตื่นใจ ด้วยการทำความเร็วสูงสุดถึง 1.28 เทราฟลอป แต่กินพลังงานเพียง 62 วัตต์ ทำให้เราหลายๆ คนอาจจะหวังได้ว่าจะมีการพัฒนาความเร็วพีซีในระดับก้าวกระโดดในอีกไม่กี่ปีข้างหน้า แต่ด้วยการเปลี่ยนรูปแบบไปโดยสิ้นเชิง ทำให้ชิปไม่เข้ากับสถาปัตยกรรม x86 ในทุกวันนี้ และอาจจะทำงานร่วมกับสถาปัตยกรรม x86 ไม่ได้แม้ในวันที่วางจำหน่าย จึงน่าสงสัยว่านวัตกรรมที่หลุดจากกรอบในแบบเดิมๆ ไปมากๆ เช่นนี้จะได้รับการยอมรับรึเปล่า แต่ก็ไม่แน่...
มันอาจจะไปอยู่ใน PS5 ก็ได้ใครจะรู้..... (อย่าลืมเตรียมเก็บเงินนะ ท่าจะแพง :P )


























ถ้าไม่ compat.
Kerberos Tue, 13/02/2007 - 01:39
ถ้าไม่ compat. กับ x86 ยังงี้ก็หวั่นๆ ว่ามันจะซ้ำรอยกับ Itanium ไหมนะ
จากที่พี่
ipats Tue, 13/02/2007 - 07:47
จากที่พี่ลิ่วเขียน เข้าใจว่าน่าจะใช้ VM เข้ามาช่วยเรื่อง x86 ได้มั๊ง (หรือเปล่า?)
---------- iPAtS
เท่าที่ดู
tong053 Tue, 13/02/2007 - 10:18
เท่าที่ดูแล้วเป็น idea ในการแก้ปัญหาเท่านั้นครับ ถ้าออกเป็น product จริงผมว่าการที่ผลักภาระทุกอย่างให้ compiler, programmer ทั้งหมดอย่างนี้น่าจะไม่ไหวนะ น่าจะมีอะไรที่เป็นตัวกลางระหว่าง cpu กับ programmer อีกที อย่าง cell ที่มี core หลักนี่ผมว่าก็น่าจะทำให้เขียน program ได้ง่ายขึ้นนะ
อีกอย่างคือความ compatible กับ x86 ดังจะเห็นได้จาก itanium (เขียนถูกป่าวหว่า) ที่สุดท้ายก็ไม่รุ่ง
ผู้ผลิตยั
pt Tue, 13/02/2007 - 10:39
ผู้ผลิตยังมีโอกาสที่จะเปิดการทำงานของคอร์นั้นโดยยังคงส่งชิปตัวนั้นสู่ตลาดได้ ?
tong053 -
lew Tue, 13/02/2007 - 10:48
tong053 - คงไม่ใช่แค่คอมไพล์เลอร์ล่ะครับ เห็นว่าต้องการ "ภาษา" เขียนโปรแกรมแบบใหม่ พร้อมๆ กับโมเดลการเขียนโปรแกรมแบบใหม่กันเลย งานนี้เรียกว่ายกเครื่องทันทั้งชุด เรียกว่าเตรียมอ่านหนังสือโมเดลการเขียนโปรแกรมใหม่ได้เลยถ้าสถาปัตยกรรมนี้มันได้รับความนิยม
เรื่องของความ compatible นั้น ผมไม่แน่ใจว่าพอถึงเวลาที่วางจำหน่ายจริงๆ แล้วอินเทลจะออกชิปเป็น x86 หรือไม่ แต่โดยส่วนตัวแล้วผมเชื่อว่าไม่ เพราะความแตกต่างจากสถาปัตยกรรมเดิมๆ ค่อนข้างห่างไกล
pt - แก้ไขแล้วครับ ------ LewCPE
กลับสู่ยุ
deaw Tue, 13/02/2007 - 12:37
กลับสู่ยุค machine language อีกรึเปล่า ตามมาด้วยยุค assembly & C & Tile compiler พัฒนาไปสู่ OS สำหรับ Tile จากนั้น ก็ High-level Language :) วู้.......... เพ้อเจ้อ แต่คงไม่ต้องยุ่งยากขนาดนั้นมั้ง เพราะเดี๋ยวนี้มัน cross compile กันได้ ต้องให้พวกเซียน software's porting มาอธิบาย
ผมว่านะถ้
john_leter Wed, 14/02/2007 - 10:10
ผมว่านะถ้าออกมาจริง คงจะทำให้ต้องเปลี่ยนซอฟต์แวร์เกือบทุกตัวเลยล่ะ ต่อไปอเราอาจจะใช้ power6 ก็ใด้ครับ ผมว่าดีกว่าแต่ก็แพงกว่า ไม่งั้นก็ VIA ครับ
ลินุกซ์จะ
kamthorn Wed, 14/02/2007 - 18:47
ลินุกซ์จะเป็นระบบปฏิบัติการตัวแรก ที่สามารถรันได้บนชิป 80 คอร์ (หรือเปล่า?)
แต่ก็เป็นไปได้ เพราะการพอร์ตลินุกซ์ไปรันน่าจะง่ายกว่าตัวอื่นๆ
และแอพลิเคชันแรกๆ น่าจะเป็นทางด้านการประมวลผลความเร็วสูง เฉพาะทาง มากกว่าจะเป็นเดสก์ท็อป (แหงละ) หรือแม้แต่เว็บเซิร์ฟเวอร์ อันหลังนี้คิดว่าเพราะการจะพัฒนาเว็บเซิร์ฟเวอร์ให้ optimize กับชิปนี้ได้ คงจะใช้เวลาพอสมควร
--
เห็นด้วยก
Conductor Wed, 14/02/2007 - 22:02
เห็นด้วยกับคุณ tong053 ครับ: เชื่อว่าคงจะไม่ใช่ SMP kernel แต่น่าจะเป็น concept ที่นำมาจาก tiled DSP เหมือน picochip เหมือน Cell-BE เหมือน GeForge 8800 มากกว่าครับ เพราะ SMP กิน external memory bandwidth สูงทำให้ไม่สามารถ scale ไปถึง 80 core ได้แม้จำนวน core ใน kernel เป็นเพียง sysgen parameter ผมอยากเดาผิด-จะสะใจมากหากมี 80-core SMP จริงๆ ในปัจจุบัน speed-up เริ่มไม่คุ้มหลังจาก 8-core (16-core มีคนทำ แต่เรามักไม่ค่อยเห็นแบบ 32-core หรือเกินกว่านั้น-แต่ก็มีเหมือนกัน ซึ่งมักจะแยก memory bus ทำให้แพงหนักเข้าไปอีก)
แม้ L1 cache จะเร็วมาก แต่การเชื่อมต่อกับภายนอกก็ยังจะเป็นคอขวดอยู่ดี ดังนั้นหากจะได้ผลการคำนวณเร็วๆ ก็ควรจะหลีกเลี่ยงถ่ายข้อมูลเข้าออก cache โดยจัดการคำนวณเป็น pipeline ขอ compiler เก่งๆมาจัด pipeline ให้ดี ก็จะได้ผลการคำนวณสูงมาก ผลการคำนวณของ stage หนึ่ง ยังอยู่ใน L1 cache และเป็น input ของ stage ต่อไป