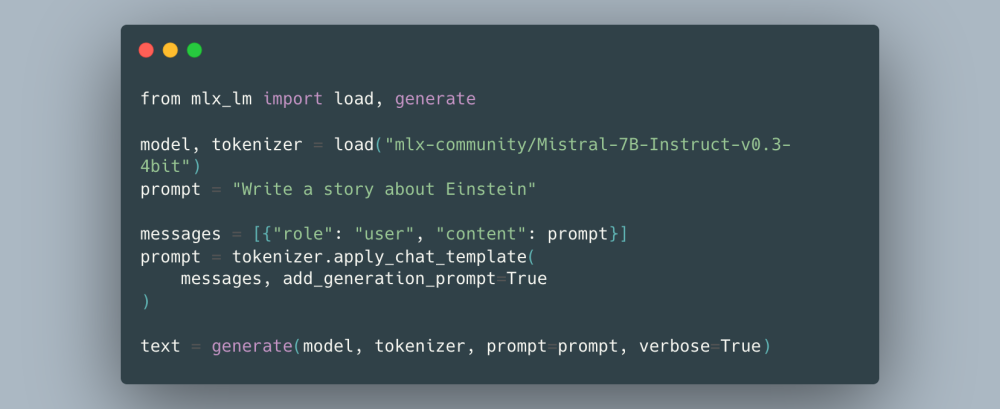
แอปเปิลเปิดตัวไลบรารี MLX-LM ที่มาพร้อมชุดคำสั่งที่เปิดให้ผู้ใช้สามารถรันโมเดลปัญญาประดิษฐ์แบบ LLM โดยมีความสามารถครบถ้วนตลอดกระบวนการใช้งาน LLM ตั้งแต่การรัน, การแคช, จนถึงการฝึกโมเดลเพิ่มเติม
กระบวนการรัน LLM ของ MLX-LM นั้นรองรับการ KV cache ทำให้โมเดลรันเร็วขึ้น ผู้ใช้สามารถเลือกขนาดหน่วยความจำที่จะใช้แคชได้
คำสั่ง quantization เปิดให้ผู้ใช้สามารถย่อโมเดลได้ด้วยตัวเอง และยังคอนฟิกได้อย่างละเอียด เช่น ย่อบางชั้นเล็กน้อยและย่อบางชั้นให้เล็กเป็นพิเศษ ส่วนกระบวนการ fine-tuning นั้น MLX-LM รองรับทั้งแบบเต็มโมเดลและแบบ LoRA ซึ่งฝึกได้เร็วกว่า
โมเดลที่ใช้งานกับ MLX-LM นั้นยังมีจำกัด แต่รองรับโมเดลยอดนิยม เช่น Mistral, Mixtral, Phi-2, Qwen ตลอดจน DeepSeek และไลบรารีนี้รองรับ macOS 15 ไม่ต้องรอ macOS 26 แต่อย่างใด
ที่มา - MLX-LM


























mlx ตัวนี้ ที่ใช้กันมาใน lm…
Fzo Wed, 11/06/2025 - 22:36
mlx ตัวนี้ ที่ใช้กันมาใน lm studio สักพักนึงแล้ว ตัวเดียวกันไหมครับ
น่าจะหมายถึง MLX เฉยๆ…
lew Wed, 11/06/2025 - 22:45
In reply to mlx ตัวนี้ ที่ใช้กันมาใน lm… by Fzo
น่าจะหมายถึง MLX เฉยๆ ที่ออกมาตั้งแต่ปี 2023 ใช้เร่งความเร็ว LLM หลายโปรแกรม โดยเฉพาะฝั่งพวก Ollama / LM Studio
รอบนี้ Apple ทำโปรแกรมเองครับ ไม่ต้องพึ่งบริษัทภายนอก
อ้อ ขอบคุณครับ
Fzo Wed, 11/06/2025 - 23:00
In reply to น่าจะหมายถึง MLX เฉยๆ… by lew
อ้อ ขอบคุณครับ
นี่คือสิ่งที่อยากเห็นจาก…
tontan Thu, 12/06/2025 - 12:05
นี่คือสิ่งที่อยากเห็นจาก Microsoft เครื่องมือ fine-tune local llm แต่กลับไม่ทำ ไปเน้น Copilot อะไรแล้วบอกตัวเองเป็น AI PC ทั้ง ๆ ที่มีแค่เครื่องมือ run llm ขณะที่ Apple ทำได้หมด ทั้งรันหรือเทรนและทำได้ยอดเยี่ยม
AI Toolkit for VS Code ?…
tontpong Mon, 16/06/2025 - 14:45
In reply to นี่คือสิ่งที่อยากเห็นจาก… by tontan
AI Toolkit for VS Code ?
ทำผ่าน wsl ?
แล้วส่วน local พึ่งปรับไปใช้ brand เป็น AI Foundry , ก็คงอยู่ระหว่างปรับ experience ให้เป็นแบบ hybrid ไปเลย .. ตอนนี้น่าจะเน้นทยอยปรับเอาจาก azure ลงมาใช้กับ local ( ขาขึ้นก็คงมี , แต่ตอนนี้ส่วนระดับ end user ข้างบนมีเยอะกว่า ) , https://devblogs.microsoft.com/foundry/wp-content/uploads/sites/89/2025/05/foundry_local.png
ระหว่างนี้ , ฟาก local ก็ทำกับ ecosystem ของ ollama ไปพลางๆ .. เห็น toolchain ของ ms หลายตัว , เริ่ม support แบบ native ละ
ปล. อันนี้เป็นข้อมูลแบบเท่าที่เห็น , ไม่ได้ลงไปจับจิงจัง .. ยังไม่ค่อยได้ลงกับฟาก local , กะว่าจะขอรอดูผลจาก ram/storage/interconnect ที่เป็น gen ใหม่
ขอบพระคุณมากกก ว่าแต่ spec…
tg-thaigamer Thu, 12/06/2025 - 15:28
ขอบพระคุณมากกก ว่าแต่ spec ขั้นต่ำที่ใช้เทรนแรมขนาดไหน T_T