มีประเด็นเล็ก ๆ จากงานเปิดตัวโมเดล GPT-5 ของ OpenAI เมื่อคืนนี้ เมื่อทีมงานพูดถึงผลการทดสอบความสามารถโมเดล AI ในด้านต่าง ๆ และเปรียบเทียบกับโมเดลรุ่นก่อนหน้า ด้วยกราฟแท่งของคะแนนเปรียบเทียบกัน แต่มีอะไรให้เอ๊ะอยู่บ้าง
กราฟแรกเป็นอัตราการสร้างผลลัพธ์ลวงที่ไม่สามารถทำได้จริง (Deception Rate) ซึ่งระบุว่า GPT-5 ทำได้ที่ 50% แต่กราฟที่แสดงนั้นดูเพี้ยนไปเมื่อเทียบกับ o3 ที่ 47.4% ทั้งนี้ในรายงานฉบับเต็มของ OpenAI ตัวเลขจริงอยู่ที่ 16.5% ด้วย

กราฟอีกอันเป็นผลทดสอบ SWE-bench เรื่อง Software Engineering ซึ่ง GPT-5 ทำคะแนนได้ 74.9% ดีกว่า o3 ที่ 69.1% แต่กราฟที่แสดงดูผิดสัดส่วนไปมาก โดยเฉพาะเมื่อเทียบกับ GPT-4o ที่ 30.8%
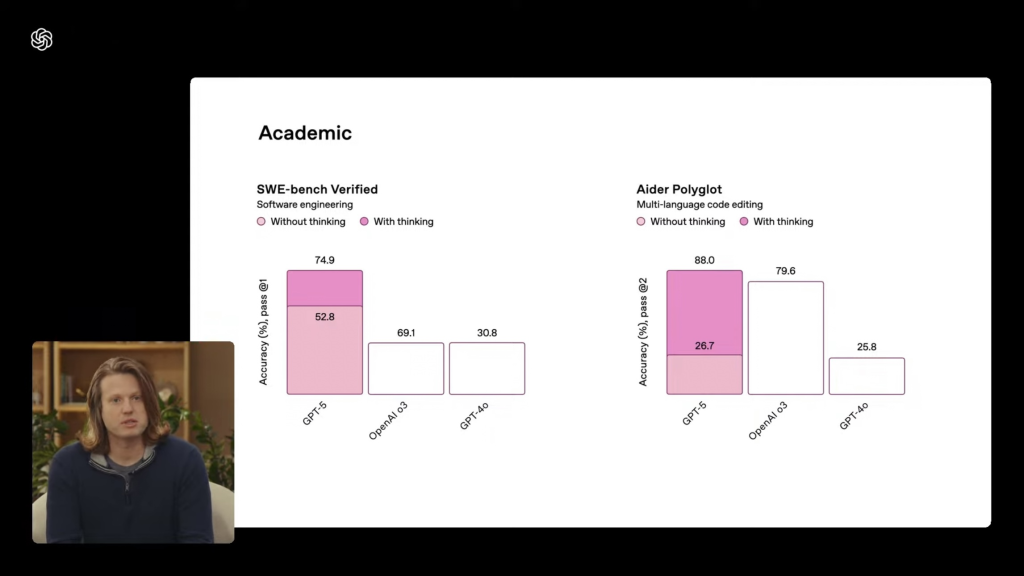
Sam Altman ซีอีโอ OpenAI ตอบประเด็นนี้ใน X ว่าเป็นการสร้างกราฟที่ผิดพลาดมาก อย่างไรก็ตามในโพสต์ทางการบนเว็บ OpenAI กราฟทั้งหมดแสดงผลอย่างถูกต้องแล้ว เช่นเดียวกับตัวแทนฝ่ายการตลาดของ OpenAI ออกมาชี้แจงว่าได้แก้ไขตารางนี้แบบทางการไปแล้ว
ที่มา: The Verge



























คีย์พร้อมต์ให้เอไอสร้าง…
pit Fri, 08/08/2025 - 22:08
คีย์พร้อมต์ให้เอไอสร้าง แล้วมั่นใจมากจนไม่ตรวจปรู๊ฟก่อน?