กูเกิลอธิบายการทำงานของแอป Recorder ใน Pixel ที่ปีนี้เพิ่มฟีเจอร์แยกเสียงคนพูดให้ด้วย นอกจากการแปลงเสียงเป็นข้อความตามปกติ จุดสำคัญคือฟีเจอร์นี้รันบนโทรศัพท์ทั้งหมดโดยไม่ต้องส่งข้อมูลเสียงกลับเซิร์ฟเวอร์
เทคนิคที่กูเกิลใช้ คือการสร้างโมเดลปัญญาประดิษฐ์สำหรับหาจุด “เปลี่ยนคนพูด” (speaker turn detection) ทำให้ได้ข้อมูลเสียงในช่วงที่ผู้พูดแต่ละคนพูด จากนั้นใช้โมเดล speaker encoder วิเคราะห์หารูปแบบการพูดของผู้พูดแต่ละคนออกมาเป็นเวคเตอร์ สุดท้ายคือการจับกลุ่มข้อมูลเสียงพูดช่วงต่างๆ ที่มีค่าเวคเตอร์ลักษณะเสียงต่างกัน ให้ออกมาเป็นกลุ่มข้อมูลแยกตามผู้พูด โดยกระบวนการแยกกลุ่มข้อมูลนี้จะเปลี่ยนอัลกอริทึมตามความยาวของเสียงพูดที่บันทึกไว้ เนื่องจากกรณีที่บันทึกเสียงยาวมากๆ ต้องประหยัดพลังประมวลผลด้วยการจัดกลุ่มข้อมูลเสียงไว้ช่วงแรกแล้วข้อมูลที่เหลือใช้ข้อมูลชุดเดิมดูว่าตรงกันหรือไม่
ในกรณีที่มีช่วงเสียงพูดที่โมเดลแยกผู้พูดไม่แน่ใจนักว่าเป็นผู้พูดคนใด ระบบจะอัพเดตโมเดลใหม่โดยอัตโนมัติ
ระบบทั้งหมดนี้ยังรันอยู่ในซีพียูแทบทั้งหมด โดยทีมงานระบุว่ากำลังย้ายงานไปรันในส่วน TPU มากขึ้นเพื่อให้กินพลังงานน้อยลง และอนาคตก็จะเพิ่มภาษาที่รองรับมากขึ้นเรื่อยๆ
ที่มา - Google
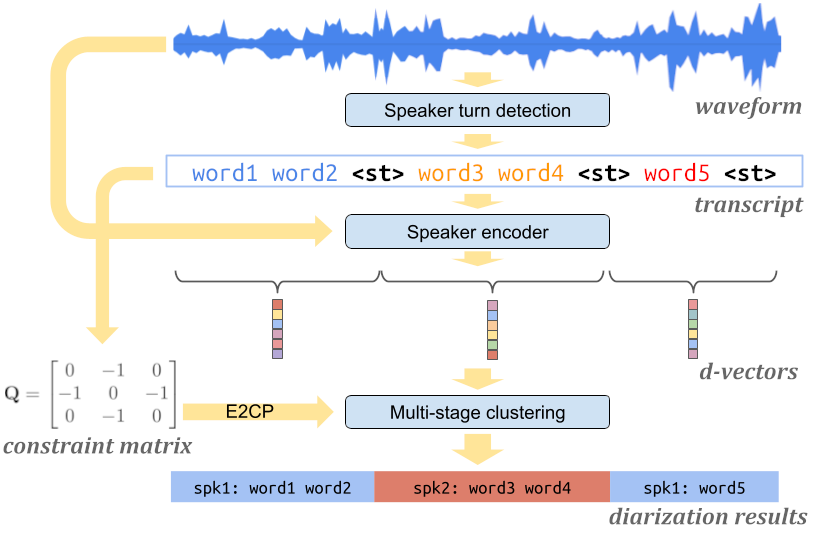


























กูเกิลย้ำค่อนข้างมากว่าส่วน
lew Tue, 03/01/2023 - 10:11
กูเกิลย้ำค่อนข้างมากว่าส่วน encoder (วิเคราะห์ลักษณะเสียง) ใช้เสร็จแล้วลบเลยทันที น่าจะกังวลความเป็นส่วนตัวเดี๋ยวโดนว่าติดตามผู้ใช้ด้วยเสียงอีก