DeepMind เปิดตัว Gemini Diffustion โมเดลปัญญาประดิษฐ์ภาษารุ่นพิเศษที่ใช้เทคนิคการสร้างคำตอบต่างจากเดิมที่เป็นการตอบทีละโทเค็น กลายเป็นการสร้างคำตอบออกมาทั้งหมดแม้จะผิดบ้าง แล้วค่อยๆ ปรับให้ตรงขึ้นเรื่อยๆ แบบเดียวกับปัญญาประดิษฐ์สร้างภาพที่มักสร้างจากภาพเบลอๆ แล้วค่อยๆ ชัดขึ้นเรื่อยๆ
จุดเด่นสำคัญของเทคนิคนี้ คือความเร็วในการตอบสูงมาก ตอนนี้ทำได้ 1,479 โทเค็นต่อวินาที ตัวโมเดลมีขนาดเล็ก แม้ว่าทาง DeepMind ไม่ได้เปิดเผยว่าโมเดลจริงๆ มีขนาดเท่าไหร่
กระบวนกรทดสอบ DeepMind เทียบกับ Gemini 2.0 Flash Lite ที่เน้นความเร็วเหมือนกัน พบว่า Gemini Diffusion มีประสิทธิภาพเทียบเคียงกัน ผลทดสอบผลัดกันแพ้ชนะในแต่ละการทดสอบ
ตอนนี้โมเดลเปิดทดสอบวงปิด ต้องลงชื่อขอใช้งานล่วงหน้าเท่านั้น
ที่มา - DeepMind
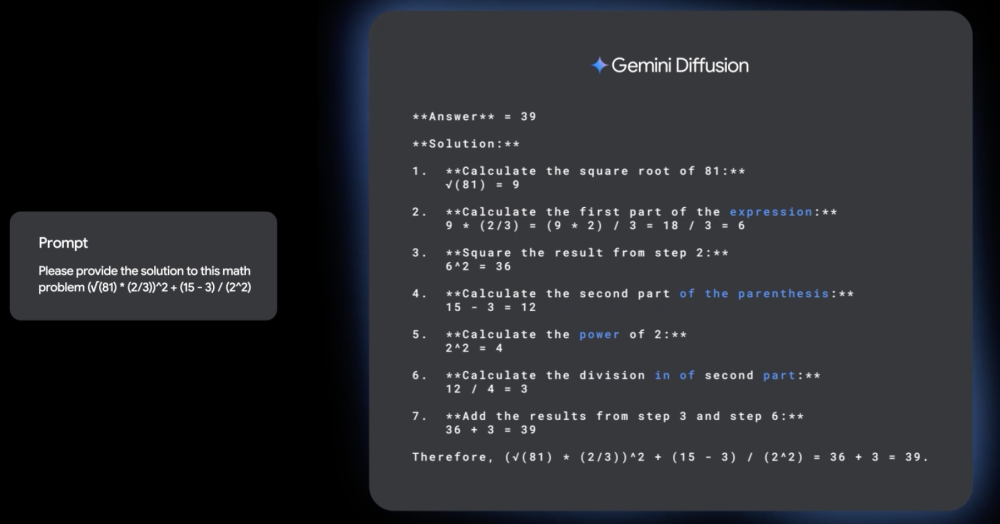


























อันนี้โหดแบบนรกมากๆ…
incredibles Wed, 21/05/2025 - 19:27
อันนี้โหดแบบนรกมากๆ ถ้าพัฒนาไปเรื่อยๆจนประสิทธิภาพสูงขึ้นมาได้ เผลอจะกินพวก Auto regressive ได้เลยนะเนี่ย
อันนี้ พฤติกรรมที่แสดงออก…
tontpong Fri, 23/05/2025 - 02:02
อันนี้ พฤติกรรมที่แสดงออก เหมือน ตอนที่มนุษย์คิดหรือดราฟงาน ? .. โดยเฉพาะคนที่อ่านแบบ skimming , ความเป้ะน่าจะไม่ใช่ปัจจัยแรกที่ต้องการ น่าจะอยากได้เค้าโครงมาดูแบบผ่านๆ ก่อน
พวกฟีเจอร์ deep research , ถ้าทำแบบนี้ ก็น่าจะดี .. final จะใช้เวลาหลายวันเลยก้อได้ , แต่ขออัพเดทมาเรื่อยๆ ช่วงแรกขอแค่ไม่กี่วินาที แล้วค่อยยืดเป็นหลักสิบวินาที ยืดเป็นหลักนาที เป็นชั่วโมง , หรือกดขอ current draft ได้ และก็ comment แล้วไปปรับได้เลย