กูเกิลเปิดตัว DiffusionGemma โมเดลภาษาแบบเปิดรุ่นทดลอง ที่ใช้เทคนิค text diffusion (ปิดบางส่วนของข้อความแล้วคาดเดาผลลัพธ์ ลักษณะเดียวกับโมเดลสร้างภาพ) แทนการทำนายคำตอบทีละโทเค็นแบบโมเดลตระกูล Transformer แบบดั้งเดิม
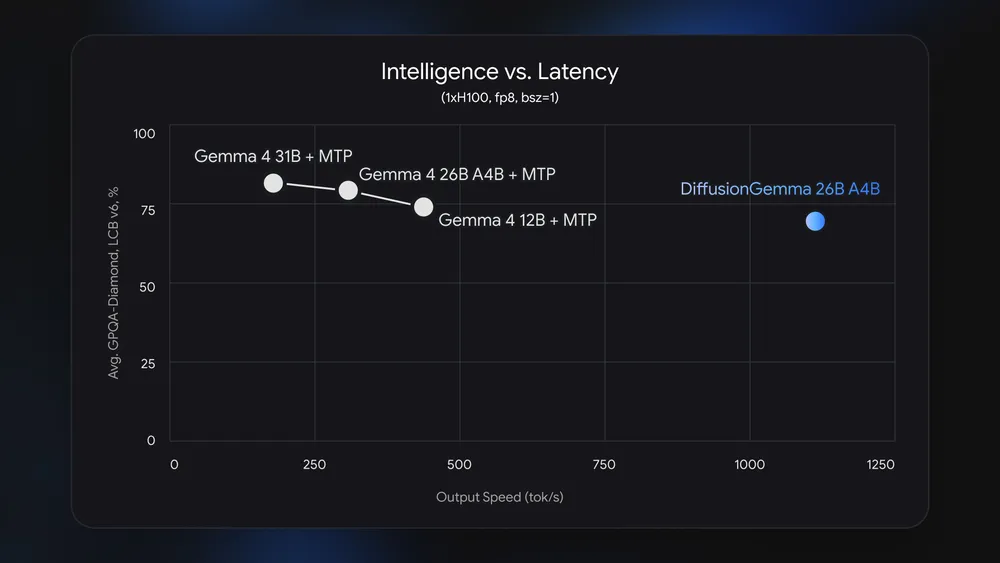
ข้อดีของโมเดลตระกูล diffusion คือทำงานได้เร็วกว่ามาก เพราะสร้างข้อความผลลัพธ์ทีเดียวทั้งบล็อค ตัวเลขของกูเกิลที่รองรันโมเดลบนจีพียูพบว่า เร็วขึ้นสูงสุด 4 เท่าเมื่อเทียบกับโมเดลตระกูล Gemma รุ่นมาตรฐาน ที่ระดับคุณภาพของผลลัพธ์ใกล้เคียงกัน (ผลลัพธ์บน H100 ออกมาได้มากกว่า 1,000 โทเค็นต่อวินาที)
DiffusionGemma เป็นการต่อยอดจาก Gemini Diffusion ที่เปิดตัวในปี 2025 แต่เป็นการทดสอบในวงปิด คราวนี้มาเป็นโมเดลเปิดให้นำไปใช้งานกันได้เลย โมเดลสร้างโทเค็นครั้งละ 256 โทเค็น และมีความสามารถวัดผลคุณภาพผลลัพธ์ และปรับปรุงแก้ไขผลลัพธ์ให้คุณภาพดีขึ้นได้แบบเรียลไทม์
โมเดลที่ปล่อยออกมามีขนาดพารามิเตอร์ 26B แบบสถาปัตยกรรม Mixture of Experts (MoE) โดยตอนรันจะใช้พารามิเตอร์เพียง 3.8B สามารถรันในจีพียูขนาด VRAM 18GB ได้ กูเกิลยังจับมือกับ NVIDIA ปรับแต่งโมเดลให้ทำงานบนจีพียูคอนซูเมอร์อย่าง RTX 5090 และ 4090 ได้ดีขึ้นด้วย
กูเกิลบอกว่าคุณภาพของผลลัพธ์ DiffusionGemma ยังด้อยกว่า Gemma 4 รุ่นมาตรฐาน เพราะเน้นความเร็วเป็นหลัก หากต้องการคุณภาพเป็นหลัก ก็แนะนำให้ยังใช้ Gemma 4 รุ่นมาตรฐานดีกว่า
ที่มา - Google