ทีมวิจัยของแอปเปิลรายงานถึงแนวทางการฝึกโมเดลปัญญาประดิษฐ์แบบ LLM ด้วยเทคนิค simple self-distillation (SSD) ที่เป็นการนำเอาคำตอบเดิมของโมเดลเอง มาฝึกกับตัวเอง ทำให้ไม่จำเป็นต้องใช้ข้อมูลฝึกจากโมเดลขนาดใหญ่กว่า หรือฝึกแบบตรวจคำตอบไปด้วย (เช่น การรันผลทดสอบโปรแกรมที่ได้)
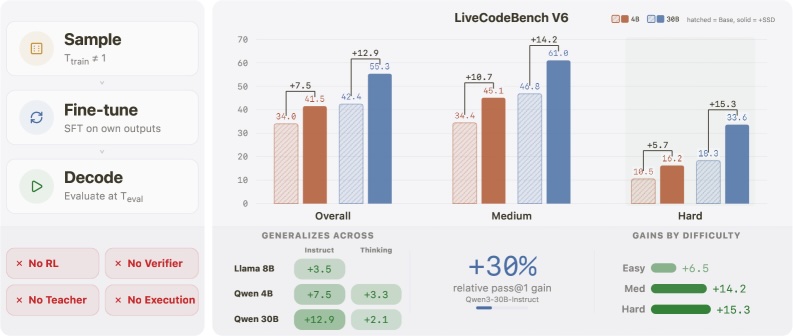
รายงานทดลองแนวคิดด้วยการฝึกโมเดล Qwen3-4B และ Qwen3-30B มาทำโจทย์จากชุดทดสอบ rSTARcoder จำนวน 10,000 ข้อ กรองคำตอบผิดพลาดอย่างง่าย เช่น คำตอบสั้นมากๆ หรือไม่มีคำตอบเลย จากนั้นนำเอาต์พุตมาฝึกย้อนเข้าไปในตัวโมเดลเอง แล้วนำโมเดลที่ฝึกแล้วไปวัดผลด้วย LiveCodeBench v6 ผลพบว่าโมเดลที่ฝึกทำคะแนนได้ดีขึ้นอย่างชัดเจน เช่น Qwen3-30B-Instruct ทำคะแนนดีขึ้นถึง 13%
แนวคิดการฝึกด้วยผลลัพธ์ของตัวเองแต่ยังได้ผลการทำงานที่ดีขึ้นเช่นนี้เป็นเรื่องค่อนข้างแปลก เพราะโมเดลถูกย้ำให้ตอบคำตอบเดิมที่เคยตอบได้อยู่แล้ว
ทีมวิจัยระบุว่าที่ SSD ช่วยปรับปรุงคุณภาพโมเดลได้เพราะในการสร้างโทเค็นจริง แต่ละโทเค็นทำหน้าที่ต่างกัน กระบวนการสร้างโทเค็นบางอันต้องการคำตอบที่ถูกต้องหนึ่งเดียว ขณะที่บางโทเค็นต้องการทางเลือกที่หลากหลาย เรียกว่า Precision-Exploration Conflict การฝึกแบบ SSD ช่วยย้ำตัวเลือกที่ต้องการความหลากหลายให้มีน้ำหนักสูงขึ้น ขณะที่โทเค็นที่ต้องการความแม่นยำก็ไปลดน้ำหนักของตัวเลือกอื่นๆ ลง
แนวทางนี้แสดงให้เห็นว่ากระบวนการฝึกโมเดลปัญญาประดิษฐ์ LLM ยังรีดประสิทธิภาพโมเดลออกมาได้อีกแม้ไม่มีข้อมูลฝึกเพิ่มเติม ในอนาคตเราอาจจะเห็นการฝึกแนวนี้เป็นขั้นตอนมาตรฐานต่อไป
ที่มา - ArXiv: Embarrassingly Simple Self-Distillation Improves Code Generation


























คล้าย ๆ…
big50000 Mon, 06/04/2026 - 15:05
คล้าย ๆ กับที่ให้เด็กทบทวนแบบฝึกหัดหรือเปล่านะ
แล้วมันจะรู้ไหมว่าอะไรผิดอะไ…
Aize Mon, 06/04/2026 - 15:52
แล้วมันจะรู้ไหมว่าอะไรผิดอะไรถูก หรือเขามีแบบฝึกหัดไว้ทดสอบเรื่อยๆ
ความประหลาดของงานนี้คือไม่รู…
lew Mon, 06/04/2026 - 16:15
In reply to แล้วมันจะรู้ไหมว่าอะไรผิดอะไ… by Aize
ความประหลาดของงานนี้คือไม่รู้ครับ ไม่มีแบบทดสอบเรื่อยๆ
งานก่อนหน้านี้มีประเภทให้ทำงานที่ตรวจคำตอบได้แล้วเอาผลมาฝึกอยู่ก่อนแล้ว แต่อันนี้คือไม่สนใจเลย ตอบมายังไงฝึกซ้ำอย่างนั้น
ยังไงหล่ะเนี่ย…
orchidkit Mon, 06/04/2026 - 18:36
ยังไงหล่ะเนี่ย เหตุผลเกิดจากอะไรน้อ
เรายังจะใช้คำว่า garbage in garbage out ได้อยู่รึเปล่าเนี่ย ในเมื่อคำตอบเดิมมันดีขึ้นได้่
งงว่าเป็นไปได้ไง อาจจะ Pseudo เฉพาะเคสบางประเภทรึเปล่า
จากที่จะมองว่าซ้ำๆ…
tg-thaigamer Mon, 06/04/2026 - 18:39
จากที่จะมองว่าซ้ำๆ ทำให้มันจำและ overfit กลับกลายทำให้ดีจึ้นเฉย น่าสนใจๆ
ถ้าเป็นจริงมันก็เก่งได้ไม่รู…
gosol Mon, 06/04/2026 - 22:54
ถ้าเป็นจริงมันก็เก่งได้ไม่รู้จบสิ
AGI รึยัง??
"น่าจะ"…
lew Mon, 06/04/2026 - 23:50
In reply to ถ้าเป็นจริงมันก็เก่งได้ไม่รู… by gosol
"น่าจะ" ดีขึ้นได้ค่าหนึ่งเท่านั้นครับ อารมณ์ +10% ทำเกินนั้นแล้วแย่ลง
กลัวว่า creativity…
nununu Tue, 07/04/2026 - 08:18
กลัวว่า creativity มันจะลดลงน่ะสิ
จากประสบการณ์เอา AI…
iqsk131 Tue, 07/04/2026 - 13:11
จากประสบการณ์เอา AI มาแปลนิยาย (ไว้อ่านเอง)
เคยลองสั่งให้มันแก้ไขตัวเองเวลาแปลแล้วได้จำนวนบรรทัดไม่เท่ากันใน session เดียวกัน (ก็คือ Context Window เดียวกัน)
ผลลัพท์คือ... มันแก้ตัวเองไม่ได้ ขนาดเขียนโค้ดเช็คให้แล้วว่าบรรทัดไหนน่าจะหายไป (เช็คบรรทัดที่เป็นบทพูดกับไม่ใช่บทพูด) ก็ยังแก้ไม่ได้
ลูปไปเรื่อยๆจนจบที่ เพิ่มบรรทัดเปล่าหรือก๊อปบรรทัดก่อนหน้าเติมแทน ไปจนกระทั่งไปอ่านโค้ดที่ใช้เช็คและหาวิธี "โกง" เพื่อให้มันผ่านด้วย...
ทำ blog หรือ repo…
orchidkit Tue, 07/04/2026 - 17:53
In reply to จากประสบการณ์เอา AI… by iqsk131
ทำ blog หรือ repo เรื่องนี้มั้ยครับ อยากศึกษาด้วยครับ เพราะทำไว้อ่านเองเหมือนกัน
พอดีผมกำลัง custom งูๆปลาๆเรื่องนี้เหมือนกัน ติดปัญหา context เนี่ยแหละ 5555
มี repo อยู่ครับ…
iqsk131 Wed, 08/04/2026 - 11:18
In reply to ทำ blog หรือ repo… by orchidkit
มี repo อยู่ครับ แต่ไม่ได้ทำไว้เผยแพร่มันก็เลยจะลวกๆหน่อย ยังลองผิดลองถูกอยู่เหมือนกัน หลายๆอย่างในนี้ก็ใช้ AI นี่แหละช่วยเขียนครับ 😅
ส่วนหลักๆที่มีก็
ส่วนตัวตอนนี้ก็อยู่ในระดับที่พอจะรันทิ้งไว้ไม่ต้องเฝ้าดูได้อยู่ครับ แต่พอมาทำเรื่องนี้แล้วรู้สึกได้เลยว่าการเอา AI มาแปลนิยายเนี่ย มันแอบยากกว่าเขียนโค้ดอีก อย่างที่หลายๆความเห็นข้างบนว่าไว้คือ AI มันไม่รู้ว่าผิดหรือถูกต่างจากงานเขียนโค้ด มันก็เลยยากที่จะทำออกมาได้สมบูรณ์
ขอบคุณมากครับ…
orchidkit Thu, 09/04/2026 - 23:03
In reply to มี repo อยู่ครับ… by iqsk131
ขอบคุณมากครับ ดีใจที่เจอคนสนใจในเรื่องเดียวกัน