Ollama โครงการซอฟต์แวร์รัน LLM บนพีซียอดนิยมออกเวอร์ชั่น 0.19 มีความเปลี่ยนแปลงสำคัญคือรองรับเฟรมเวิร์ค MLX ที่ใช้สำหรับการรันปัญญาประดิษฐ์บนชิป Apple Silicon อย่างเป็นทางการ ทำให้ความเร็วในการรันสูงขึ้นมาก นอกจากนี้ยังรองรับโมเดลที่ quantize แบบ NVFP4 ที่เร่งความเร็วโดยเสียความแม่นยำน้อยลงด้วย
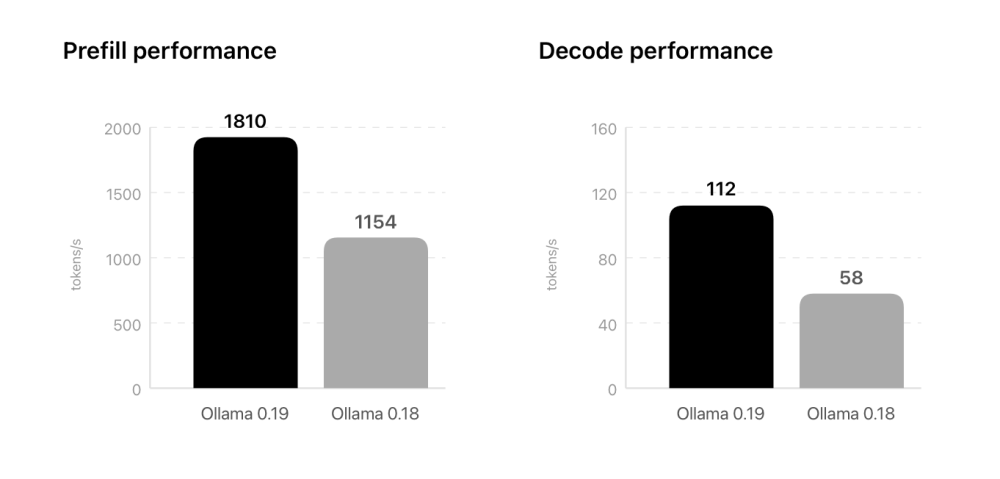
ทางโครงการทดสอบ Qwen3.5-35B-A3B แบบ NVFP4 บนชิป M5 พบว่ารัน prefill (ประมวลผลพรอมพ์) ได้ 1810 โทเค็นต่อวินาที เร็วขึ้น 57% ขณะที่การรัน decode ได้ 112 โทเค็นต่อวินาทีเร็วขึ้น 93% หรือเกือบเท่าตัว ทีมงานระบุว่าหากรันแบบ INT4 จะเร็วกว่านี้ขึ้นอีก
NVFP4 เป็นฟอร์แมตเลขทศนิยมแบบ 4-bit ของ NVIDIA โดยออกแบบให้ใช้เลขเพียง 4 บิตแต่มีเลข FP8 อีกหนึ่งค่าเพื่อ scale ค่าออกมาให้ตัวเลข 4-bit ใช้แสดงค่าได้ตรงมากขึ้น
ที่มา - Ollama


























แล้วได้ทุก Models…
comdevx Wed, 01/04/2026 - 16:38
แล้วได้ทุก Models เลยหรือเปล่า หรือว่าเฉพาะที่ปรับแต่งมาเฉพาะ MLX อีก
จากใจ M4 เร็วมาก…
Sephanov Wed, 01/04/2026 - 19:55
จากใจ M4 เร็วมาก ตอนนี้จบโปรเจคง่ายๆได้สบาย อยากได้ M5 เพราะ NLP in gpu ขึ้นมาเลย
Intel NPU ก็คื้อ
hisoft Thu, 02/04/2026 - 04:10
Intel NPU ก็คื้อ
เอาเข้าจริง NPU…
lew Thu, 02/04/2026 - 08:16
In reply to Intel NPU ก็คื้อ by hisoft
เอาเข้าจริง NPU แยกนี่แทบไม่มีใครรอดเลยครับแม้แต่แอปเปิลเอง M5 นี่รวมเข้าไปใน GPU แล้ว
เป็นโครงการแข่งกันมีแต่ไม่ได…
hisoft Fri, 03/04/2026 - 06:28
In reply to เอาเข้าจริง NPU… by lew
เป็นโครงการแข่งกันมีแต่ไม่ได้ใช้สินะครับ orz
M5 ไม่โปรสินะ ถ้าโปรจะขนาดไหน
tg-thaigamer Thu, 02/04/2026 - 08:38
M5 ไม่โปรสินะ ถ้าโปรจะขนาดไหน
ผมที่รอ Mac mini M5…
Fzo Thu, 02/04/2026 - 09:40
ผมที่รอ Mac mini M5 ต้องทำใจว่า เปิดตัวมาขาดตลาดแน่ๆ