Alibaba Cloud เปิดตัวโมเดล Qwen3-Coder-Next ปัญญาประดิษฐ์แบบ LLM พัฒนาต่อจาก Qwen3-Next-80B-A3B-Base แล้วนำไปฝึกการเขียนโปรแกรมมาโดยเฉพาะ
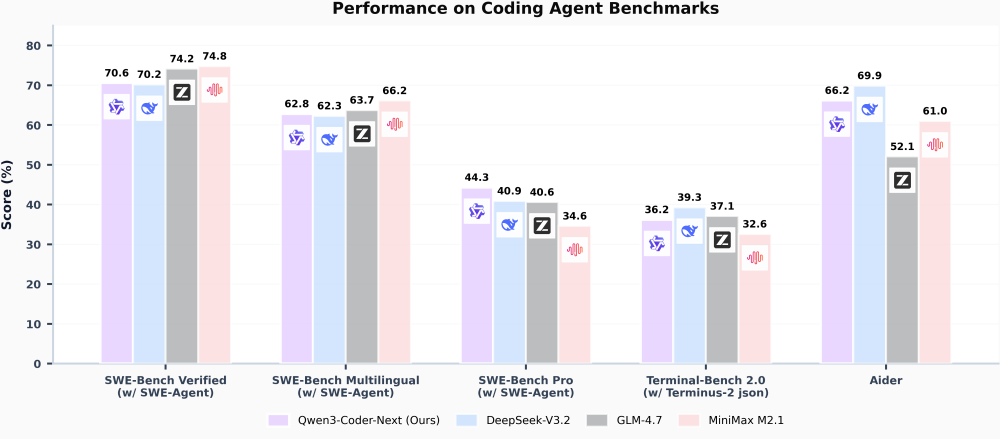
กระบวนการฝึก Qwen3-Coder-Next อาศัยฝึกจากข้อมูลโค้ดเดิม และปัญหาการเขียนโปรแกรมที่ตรวจสอบได้ ทำให้โมเดลสามารถฝึกเขียนและดูผลลัพธ์ไปได้เรื่อยๆ ว่าทำงานถูกต้องหรือยัง ผลที่ได้ทำให้โมเดลนี้เกาะกลุ่มอยู่กับโมเดลปัญญาประดิษฐ์เขียนโปรแกรมแบบเปิดหลายตัว เช่น DeepSeek V3.2, GLM-4.7, Kimi-K2.5 แต่ความได้เปรียบคือโมเดล Qwen3-Coder-Next มีขนาดเพียง 80B และรันจริงเพียง 3B ทำให้สามารถรันในเซิร์ฟเวอร์ขนาดเล็กกว่ามาก ที่สำคัญโมเดลเป็นแบบ non-thinking ทำให้คำตอบทันทีไม่ต้องรอให้โมเดลคิดให้เสร็จก่อน
ขนาดที่เล็กกว่ามากน่าจะทำให้ต้นทุนการให้บริการ Qwen3-Coder-Next ต่ำกว่าคู่แข่งอย่างมากเช่นกัน แต่ผู้ให้บริการอย่าง Together.AI กลับให้บริการราคาอินพุตพอๆ กันที่ 0.5 ดอลลาร์ต่อล้านโทเค็น ไปแตกต่างที่เอาท์พุตโดย Qwen3-Coder-Next อยู่ที่ 1.2 ดอลลาร์ต่อล้านโทเค็น ขณะที่ Kimi-K2.5 อยู่ที่ 2.8 ดอลลาร์ และ GLM-4.7 อยู่ที่ 2.0 ดอลลาร์
ทาง Qwen แจกโมเดลรุ่นนี้ตั้งแต่แบบ 4-bit ไปจนถึง 16-bit
ที่มา - Qwen


























ฉัน: model ai ขนาด 80b…
paween_a Thu, 05/02/2026 - 11:06
ปุจฉา: model ai ขนาด 80b แปลว่าอะไร
วิสัชนา: คำว่า 80B ในทาง AI ย่อมาจาก 80 Billion Parameters หรือแปลเป็นไทยคือ Model นั้นมี "พารามิเตอร์" จำนวน 8 พันล้านตัว ครับ
เพื่อให้เห็นภาพชัดเจนขึ้น ผมขอสรุปประเด็นสำคัญดังนี้ครับ:
ในเชิง Programming และ Machine Learning พารามิเตอร์เปรียบเสมือน "เซลล์ประสาท" หรือ "ปุ่มปรับจูน" ภายในโครงข่ายประสาทเทียม (Neural Network)
ยิ่งมี Parameter มาก Model ก็ยิ่งมีความสามารถในการจดจำ Pattern, เข้าใจบริบทที่ซับซ้อน และมีความรู้ที่กว้างขวางมากขึ้น
เปรียบเทียบง่ายๆ เหมือน Model คือสมอง ยิ่งจำนวน B (Billion) สูง สมองนั้นก็ยิ่งมีขนาดใหญ่และซับซ้อน
ในปัจจุบัน (ปี 2026) เรามักแบ่งขนาด Model ออกเป็นกลุ่มกว้างๆ ดังนี้:
Small (7B - 14B): ขนาดเล็ก รันบนคอมพิวเตอร์ทั่วไปหรือ Mobile Device ได้ เหมาะกับงานเฉพาะทางที่ไม่ซับซ้อนมาก
Medium (30B - 80B): ขนาด 80B ตกอยู่ในกลุ่มนี้ครับ ถือเป็นจุดที่สมดุลมาก (Sweet Spot) เพราะเก่งใกล้เคียงกับ Model ตัวท็อปๆ แต่ยังสามารถรันบน Server ทั่วไปหรือ Workstation แรงๆ ได้โดยไม่ต้องใช้ Supercomputer
Large (100B - 1T+): เช่น GPT-4 หรือ Llama ตัวท็อปสุด กลุ่มนี้จะฉลาดมากแต่กินทรัพยากรสูงมหาศาล
การที่ Model มีขนาดถึง 80B หมายความว่า:
กิน RAM/VRAM สูง: ในการใช้งาน (Inference) คุณอาจต้องใช้ GPU ที่มี VRAM สูง (เช่น A100 หรือ H100) หรือต้องทำ Quantization (การบีบอัด Model) เพื่อให้รันบนการ์ดจอผู้บริโภคทั่วไปได้
ความเร็ว (Latency): ยิ่งพารามิเตอร์เยอะ การประมวลผลต่อคำ (Token) ก็จะช้าลงกว่ารุ่นเล็กๆ อย่าง 7B หรือ 8B
สรุป: 80B คือ AI ที่มีความซับซ้อนสูงระดับกลาง-บน ซึ่งเก่งพอที่จะทำหน้าที่เป็นผู้ช่วยอัจฉริยะ เขียน Code หรือวิเคราะห์ข้อมูลยากๆ ได้ดีมากครับ
ปุจฉา:…
paween_a Thu, 05/02/2026 - 11:13
In reply to ฉัน: model ai ขนาด 80b… by paween_a
ปุจฉา: โมเดลรุ่นนี้ตั้งแต่แบบ 4-bit ไปจนถึง 16-bit หมายถึงอะไร
วิสัชนา: คำนี้หมายถึง "ความละเอียด" หรือ "ความแม่นยำ" ของตัวเลขที่ใช้เก็บค่า Parameter ใน Model ครับ ซึ่งภาษาเทคนิคเรียกว่า Quantization
ให้นึกภาพว่า Parameter แต่ละตัวคือ "ค่าน้ำหนัก" (Weight) ที่ต้องถูกจัดเก็บไว้ในหน่วยความจำ (VRAM ของการ์ดจอ) ครับ
Precision,พื้นที่ VRAM ที่ต้องการ (ประมาณ),คุณภาพของคำตอบ,ความเหมาะสม
16-bit,~160 GB,สูงสุด (100%),ใช้ใน Data Center / การทำ Fine-tuning
8-bit,~85-90 GB,ดีมาก (99%),ใช้ในงาน Production ที่ต้องการความแม่นยำ
4-bit,~45-50 GB,ดี (95-97%),ยอดนิยมที่สุด สำหรับรันบนคอมส่วนตัว (Local LLM)
อยากใช้มั่งจัง…
NOーSYSTEMS Fri, 06/02/2026 - 06:35
อยากใช้มั่งจัง แต่Aiมันทำcodeแบบผมไม่เป็น TT เป็นแค่ตรวจสอบว่าเสียหรือเปล่า