
EleutherAI หน่วยงานวิจัย AI แบบไม่หวังผลกำไร ร่วมกับสถาบันวิจัยและสถาบันการศึกษาหลายแห่ง เปิดตัว The Common Pile คลังข้อมูลขนาดใหญ่ 8TB (อ่านไม่ผิด) สำหรับเทรน AI ที่เป็นข้อมูลสาธารณะ (public domain) และข้อมูลที่ใช้ไลเซนส์แบบเปิดทั้งหมด
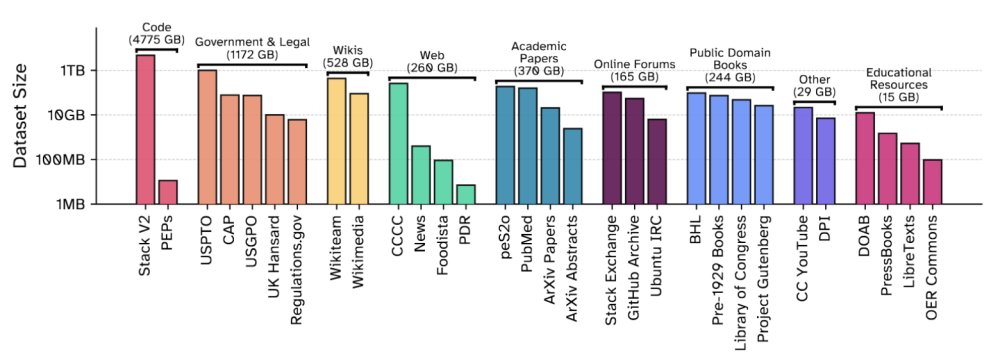
ชุดข้อมูลใน The Common Pile ประกอบด้วยชุดข้อมูลย่อย 30 ชุด ครอบคลุมข้อมูลหลากหลายประเภท เช่น โค้ดโปรแกรม, เปเปอร์วิชาการ, หนังสือที่เป็น public domain, เว็บ วิกิ กระทู้เว็บบอร์ดต่างๆ, เอกสารราชการ, กฎหมาย ฯลฯ
EleutherAI ยังออกโมเดล Comma v0.1-1T และ Comma v0.1-2T ที่เทรนด้วยข้อมูลเปิดเหล่านี้ เพื่อพิสูจน์ว่าโมเดลที่เทรนด้วยข้อมูลเปิด สามารถให้ประสิทธิภาพทัดเทียมกับโมเดลที่เทรนด้วยข้อมูลเชิงพาณิชย์ หรือข้อมูลเฉพาะขององค์กรได้ ประสิทธิภาพของโมเดล Comma ออกมาใกล้เคียงหรือดีกว่าโมเดล LlaMa 2 และ DeepSeek แปลว่าการออกชุดข้อมูลนี้มา น่าจะถูกนำไปใช้อย่างแพร่หลายในวงการ AI ที่เผชิญกับปัญหาละเมิดลิขสิทธิ์และคดีฟ้องร้องกันมากมาย
The Common Pile ยังมีสถานะเป็นเวอร์ชัน 0.1 และจะปรับปรุงเพิ่มเติมเรื่อยๆ ในอนาคต ข้อมูลชุดนี้สามารถดาวน์โหลดได้จาก Hugging Face และ GitHub
ที่มา - EleutherAI, TechCrunch
Can you train a performant language models without using unlicensed text?We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1&2 pic.twitter.com/wHQ4cquqlo
— EleutherAI (@AiEleuther) June 6, 2025


























ใช้เล็กแค่นี้ก็มีประสิทธิภาพ…
orchidkit Mon, 09/06/2025 - 01:16
ใช้เล็กแค่นี้ก็มีประสิทธิภาพ
แปลว่าเป็นข้อมูลที่คัดกรองมาอย่างดีรึเปล่า