Alibaba Cloud เปิดตัวโมเดล Qwen3 Embedding และ Qwen3 Reranking สำหรับการค้นหาเอกสารตามความหมายในเนื้อความ โดยชูจุดเด่นว่าโมเดลเหล่านี้ค้นหาเอกสารได้แม่นยำ
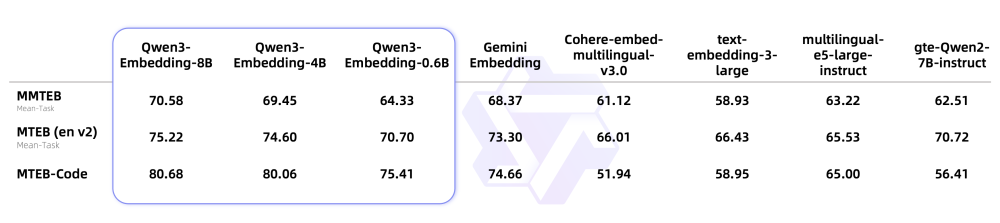
Qwen3 Embedding มี 3 ขนาด ได้แก่ 0.6B, 4B, และ 8B แม้แต่ตัวเล็กที่สุดคือ 0.6B นั้นก็ยังได้คะแนน MMTEB (ทดสอบการค้นหาเอกสารจากเอกสาร 500 ชุด กระจาย 250 ภาษา) สูงกว่า text-embedding-3-large ของ OpenAI ที่น่าจะได้รับความนิยมสูงมาก ขณะที่โมเดลขนาดใหญ่ก็สามารถเอาชนะโมเดลรุ่นใหม่ๆ ได้
ทั้ง Embedding และ Reranking ฝึกจาก Qwen3 ทั้งคู่มาฝึกต่ออีก 3 ขั้น ได้แก่ การฝึกแบบ weakly supervised ด้วยข้อมูลที่สร้างขึ้นมา, จากนั้นฝึกด้วยข้อมูลคุณภาพสูง, และนั้นสุดท้ายนำโมเดลหลายๆ เวอร์ชั่นจากการฝึกขั้นที่สองมารวมกัน
ตัว Embedding นั้นจะรับเอกสารทั้งก้อนแล้วคืนค่าเป็น vector อย่างเดียว ขณะที่ Reranking นั้นจะรับค่าเป็นคำสั่งและตัวเอกสารเข้าไปพร้อมกัน จากนั้นจะคืนค่าเป็นคะแนนว่าเอกสารนั้นเกี่ยวกับคำสั่งหรือไม่
โมเดลทุกรุ่นเปิดให้ดาวน์โหลดไปใช้ด้วยไลเซนส์ Apache 2.0
ที่มา - QwenLM


























เวรี่กู๊ด
Fzo Fri, 06/06/2025 - 14:15
เวรี่กู๊ด
8B นี่มันใหญ่มากเลยนะ…
mr_tawan Fri, 06/06/2025 - 14:55
8B นี่มันใหญ่มากเลยนะ หรือว่า embedding ตอนนี้เค้าไซส์ประมาณนี้กันครับ?
ผมใช้กลางๆ 4b q4_K-M…
Fzo Fri, 06/06/2025 - 15:26
In reply to 8B นี่มันใหญ่มากเลยนะ… by mr_tawan
ผมใช้กลางๆ 4B Q4_K-M ได้ผลดีน่าพอใจมาก ถูกใจกว่าของ google เสียอีกครับ
ใหญ่ครับ พวก embeding นี่ต่ำ…
lew Fri, 06/06/2025 - 15:31
In reply to 8B นี่มันใหญ่มากเลยนะ… by mr_tawan
ใหญ่ครับ พวก embeding นี่ต่ำ 1B กัน เช่น Snowflake
ผมน่าจะลืมแก้หัวข่าวแฮะ ปรับแล้วครับ