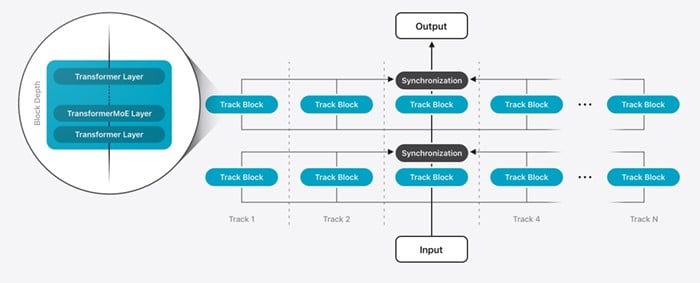
แอปเปิลรายงานถึงความคืบหน้าของการพัฒนา Apple Foundation Model (AFM) ที่เป็นโมเดลปัญญาประดิษฐ์แบบ LLM สำหรับการใช้งานใน Apple Intelligence แบ่งเป็นโมเดลสำหรับรับบนเครื่องโดยตรงและโมเดลรันบนเซิร์ฟเวอร์ (ที่แอปเปิลสร้าง private cloud compute เตรียมไว้รอ)
โมเดลทั้งสองรุ่นถูกย่อให้เหลือขนาดเล็กมาก ด้วยเทคนิค Quantization-Aware-Training (QAT) เพื่อให้คงคุณภาพเอาไว้แม้จะย่อโมเดลบนเครื่องขนาดเล็กเหลือ 2-bit และโมเดลบนเซิร์ฟเวอร์เหลือ 3.56 bit ส่วน embedding ย่อเหลือ 4 bit และส่วน KV-cache ย่อเหลือ 8 บิต
ตัวโมเดลบนโทรศัพท์มีขนาด 3B ขณะที่โมเดลบนเซิร์ฟเวอร์นั้นแอปเปิลเปิดเผยว่าขนาดพอๆ กับ LLaMa 4 Scout ซึ่งมีขนาด 17B/109B และส่วนเข้าใจภาพที่ขนาดใกล้กับ Qwen-2.5-VL
ผลการทดสอบของแอปเปิลแสดงให้เห็นว่าคะแนนทดสอบต่างๆ ของโมเดลบนโทรศัพท์อยู่ระดับเดียวโมเดลขนาดใกล้เคียงกัน แต่โมเดลของแอปเปิลนั้นความเร็วสูงกว่ามาก และกินแรมน้อยกว่าเนื่องจากใช้โมเดลรุ่นย่อแล้วมาทดสอบกับโมเดลเต็ม แต่เมื่อวัดคะแนนของโมเดลบนเซิร์ฟเวอร์ก็จะพบว่าคะแนนต่ำกว่าโมเดลคู่แข่งค่อนข้างชัด
อย่างไรก็ดี จุดขายสำคัญของ AFM คือโมเดลเหล่านี้เปิดให้นักพัฒนาบนแพลตฟอร์มแอปเปิลใช้งานได้ฟรี ทำให้เราน่าจะเห็นการใช้งานมากยิ่งขึ้นไปในอนาคต
ที่มา - Apple


























ขอให้เล็กๆ แต่ฉลาดมากๆ มาไวๆ…
tg-thaigamer Fri, 18/07/2025 - 16:27
ขอให้เล็กๆ แต่ฉลาดมากๆ มาไวๆ เถอะ 0
Benchmark…
tontan Fri, 18/07/2025 - 16:37
ต้องรอคนรีวิวเวลาใช้จริง เพราะ Benchmark พวกนี้สู้เวลาเอาไปวัดตอนนำไปใช้งานจริงไม่ได้อยู่ดี
อีกประเด็นที่ต้องรอดูคือแอปเ…
lew Sat, 19/07/2025 - 10:26
In reply to Benchmark… by tontan
อีกประเด็นที่ต้องรอดูคือแอปเปิลจะใจดีกับ server model ขนาดไหนด้วยครับ เพราะมันใช้งานผ่าน API ได้
ที่ผ่านมาแอปเปิลใจดีกับ local model แต่ยังไงลูกค้าก็เป็นคนจ่ายค่าเครื่องค่าไฟ เจอ server model ถ้าคนเอาไปทำ internal service นี่รับได้ไหมก็เป็นคำถาม