From C++ to Python (2)
ใน blog ที่แล้ว ผมได้พูดถึงประเด็นต่าง ๆ ที่ผมสะดุดเมื่อเรียนภาษาไพธอนด้วยพื้นฐานความรู้ C/C++ ที่มี ซึ่งเป็นการปรับโหมดคิดพื้นฐานให้เพียงพอสำหรับใช้เขียนไพธอนได้ ใน blog นี้จะขอเขียนส่วนที่เป็น กำไร ที่ได้จากภาษาไพธอนบ้าง
Container สำเร็จรูปภาษาไพธอนมาตรฐานมาพร้อมกับ container สำเร็จรูป คือ list, dictionary และ set โดยสามารถเก็บข้อมูลหลายชนิดปนกันได้ตามธรรมชาติของภาษา dynamic type (heterogeneous list ที่ต้องอาศัย polymorphism หรือ generic programming ใน C++ กลายเป็นเรื่องที่แสนธรรมดาเมื่อมาเขียนไพธอน) การมี container สำเร็จรูปทำให้เขียนโปรแกรมได้สะดวกขึ้นมาก
list (และ tuple ที่เป็น immutable list) นั้น มีแนวคิดเหมือนลิสต์ของภาษา Lisp ที่สามารถบรรจุข้อมูลหลากชนิดคละกันได้ รวมทั้งเก็บลิสต์ในลิสต์ กลายเป็น tree ก็ยังได้ (ยังมีอิทธิพลของภาษา Lisp ในไพธอนอีกอย่าง คือ lambda expression) แต่ implement ด้วย dynamic array เพื่อรองรับ syntax ในการเข้าถึงสมาชิกในแบบแอร์เรย์อย่างมีประสิทธิภาพ แลกกับ cost ในการเพิ่ม/ลบสมาชิกเล็กน้อย list ของไพธอนจึงทำให้สามารถทำงานกับ collection ของข้อมูลได้สะดวกโดยไม่ต้องคิดเรื่องวิธีจองหน่วยความจำ
dictionary ทำให้การใช้งาน associative array ที่พบบ่อยในโปรแกรมต่าง ๆ กลายเป็นเรื่องง่าย (กลไกภายในคือ hash table) แม้แต่ตัว interpreter ของไพธอนเองก็ยังใช้ dictionary เป็นกลไกในการทำงานหลายส่วน เช่น ใช้ในการเก็บ attribute และ method ของออบเจกต์ต่าง ๆ แบบ dynamic, การทำ symbol table ของโปรแกรม ฯลฯ
set เป็นการ implement แนวคิดของ ทฤษฎีเซ็ต ในทางคณิตศาสตร์นั่นเอง การใช้เซ็ตในโปรแกรมได้ ทำให้สามารถเขียนโปรแกรมได้ใกล้เคียงกับนิพจน์คณิตศาสตร์มากขึ้น
การมีเครื่องมือแบบนี้ พร้อม syntax ที่เรียบง่ายในการเข้าถึงในระดับตัวภาษาเอง ทำให้เขียนโปรแกรมได้สั้นกระชับ
else ในที่ต่าง ๆนอกจาก else ใน if แล้ว ไพธอนยังมี else ในลูป while, for, และใน exception handling ด้วย ซึ่งคนที่เขียนโปรแกรม C/C++ มาเยอะหน่อยอาจเคยพบกรณีที่ else เหล่านี้ช่วยลดขั้นตอนลงได้
สมมุติว่ามีการค้นหาสมาชิกในลิสต์ที่สอดคล้องกับเงื่อนไขที่กำหนด
for (const Elm* p = students.first(); p; p = p->next()) { log_visited (p); if (p->id() == id) { report_matched (p); break; } mark_unmatched (p); } if (!p) { // search exhausted report_no_match(); }เราไม่จำเป็นต้องเช็กค่า p อีกครั้งหลังจบลูปถ้าเราใช้ else หลัง for แบบนี้ในไพธอน: for s in students: log_visited (s) if (s.id == id): report_matched (s) break mark_unmatched (s) else: # search exhausted report_no_match()
หรือจะเป็นโปรแกรมให้ผู้ใช้ทายตัวเลข โดยให้ผู้ใช้หยุดทายได้ด้วยการป้อนค่า 0 หรือเลขลบ:
guess = 0; while (guess != secret) { std::cout << "Guess the number: "; std::cin >> guess; if (guess <= 0) { std::cout << "Sorry that you're giving up!" << std::endl; break; } if (guess > secret) std::cout << "The number is too large." << std::endl; else if (guess < secret) std::cout << "The number is too small." << std::endl; } if (guess == secret) std::cout << "Congratulations. You made it!" << std::endl;ด้วย else ในไพธอน คุณก็ไม่ต้องเช็กค่า guess ซ้ำหลังจบลูป:
guess = 0 while guess != secret: guess = int (input ("Guess the number: ")) if guess <= 0: print ("Sorry that you're giving up!") break if guess > secret: print ("The number is too large.") elif guess < secret: print ("The number is too small.") else: print ("Congratulations. You made it!")โค้ดแบบนี้ผมเจอค่อนข้างบ่อยใน C/C++ บางทีคิด ๆ เหมือนกันว่าถ้าใช้ goto แทน break ซะก็อาจไม่ต้องมาเช็กซ้ำ พอมาเจอ else ของลูปในไพธอนก็เข้าใจได้ทันที
List Comprehensionlist comprehension เป็นสิ่งที่ pythonic เอามาก ๆ ทำให้โค้ดกระชับและดูคล้ายนิพจน์คณิตศาสตร์
เช่น ถ้าต้องการหารายการข้อมูลในลิสต์ data ที่สูงกว่าค่าเฉลี่ย:
avg = sum(data)/len(data) print([x for x in data if x > avg])หรือแม้กระทั่งจะหาจำนวนเฉพาะทั้งหมดที่น้อยกว่าจำนวนที่กำหนด:
from math import sqrt def primes(n): sqrt_n = int(sqrt(n)) no_primes = {j for i in range(2, sqrt_n) for j in range(i*2, n, i)} return [i for i in range(2, n) if i not in no_primes]พี่จะสั้นไปไหนครับ!
ในบทที่ว่าด้วย Lambda operator, map, filter, reduce บอกไว้ที่ส่วนต้นว่า Guido van Rossum ผู้สร้างและดูแลภาษาไพธอนได้แสดงความประสงค์ที่จะ ตัด lambda, map, filter, reduce ออกใน Python 3 เพราะ list comprehension ทำสิ่งเดียวกันได้ชัดเจนและเข้าใจง่ายกว่า แต่สุดท้ายก็ทนแรงต้านจากผู้นิยม Lisp, Scheme ไม่ไหว จำเป็นต้องคงไว้ ตัดออกเฉพาะ reduce() โดยย้ายไปไว้ในมอดูล functools
เทียบกันแล้ว list comprehension ถอดแบบมาจาก set-builder notation ในทฤษฎีเซ็ต ส่วน lambda นั้น ถอดแบบมาจาก lambda calculus เห็นได้ชัดว่าทฤษฎีเซ็ตเป็นที่คุ้นเคยและเข้าใจง่ายกว่า สิ่งที่ lambda ทำได้มากกว่า list comprehension ก็คือ reduce() ซึ่งในความเห็นของผู้สร้างไพธอนแล้ว ทำให้โค้ดซับซ้อนเกินไป ยอมเขียนเป็นลูปเพื่อความชัดเจนเสียจะดีกว่า
ไหนลองเขียนด้วย lambda ดูซิ:
หาข้อมูลที่สูงกว่าค่าเฉลี่ย:
avg = sum(data)/len(data) print(list(filter(lambda x : x > avg, data)))หาจำนวนเฉพาะ:
from math import sqrt from functools import reduce def primes(n): sqrt_n = int(sqrt(n)) np_series = list(map(lambda i : set(range(i*2, n, i)), list(range(2,sqrt_n)))) np_set = reduce(lambda a, b : a | b, np_series) return list(filter(lambda i : i not in np_set, list(range(2,n))))จะเห็นว่า lambda ยาวและเข้าใจยากกว่า list comprehension
Generatorลูป for ในไพธอนจะไม่มีรูปแบบการใช้ตัวนับเหมือนภาษาทั่วไป แต่จะใช้ iterator ล้วน ๆ คือเป็นลูป foreach นั่นเอง
เช่น ลูปหาผลรวมของกำลังสองของจำนวนเต็มบวก n ตัวแรกที่เขียนในภาษา C++ อาจเป็นแบบนี้:
int sum_sq (int n) { int sum = 0; for (int i = 1; i <= n; i++) sum += i*i; return sum; }แต่ลูป for ในไพธอนจะใช้ฟังก์ชัน range() สร้าง iterator สำหรับไล่เรียง:
def sum_sq (n): sum = 0 for i in range (1, n+1): sum += i*i return sumหรือจะให้ pythonic จริง ๆ ก็ใช้ list comprehension:
def sum_sq (n): return sum([i*i for i in range (1, n+1)])iterable object ต่าง ๆ เช่น list, tuple, dictionary, set สามารถใช้เป็น iterator ได้ทันที นอกจากนี้ ยังสามารถสร้าง iterator ขึ้นเองได้ โดยทำตามโพรโทคอลที่กำหนด (สร้างคลาสที่มีเมธอด __iter__(), next() โดย next() คืนค่าตัววิ่งแต่ละขั้น และ raise StopIteration exception เมื่อวิ่งสุดแล้ว) แต่เพื่ออำนวยความสะดวกยิ่งขึ้น ไพธอนได้บัญญัติสิ่งที่เรียกว่า generator ที่ใช้วิ่งลูปได้เหมือน iterator แต่เขียนง่ายกว่า
ตัวอย่างเช่น ถ้าจะเขียน generator สำหรับไล่ลำดับ Fibonacci:
def fibo (n): a, b = 0, 1 for i in range(n): yield a a, b = b, a + b(yield ทำหน้าที่คล้าย return สำหรับแต่ละรอบ และรอบต่อไปก็จะเริ่มทำงานต่อจากบรรทัดที่ yield ไว้)
จากนั้นก็สามารถไล่ลำดับ Fibonacci ได้ตามต้องการ:
>>> list(fibo(10)) [0, 1, 1, 2, 3, 5, 8, 13, 21, 34] >>> for x in fibo(5): ... print (x) ... 0 1 1 2 3 >>> [x for x in fibo(10) if x % 2 == 0] [0, 2, 8, 34]การมี construct แบบ generator ก็ทำให้มีความยืดหยุ่นของการเขียน iterator เช่น สามารถเขียน generator แบบ recursive ได้ หรือกระทั่งเขียน generator ซ้อน generator ได้ อ่านเพิ่มเติม
เมื่อมองย้อนกลับไปถึงตอนแรกที่เราพบว่าไพธอนมีแต่ลูป foreach เท่านั้น ก็ไม่ได้ทำให้ความสามารถด้อยไปกว่าภาษาที่มีลูปตัวนับแต่อย่างใด (ในเมื่อมีฟังก์ชัน range()) แต่กลับมีความยืดหยุ่นสูงมากในการวนลูปที่ซับซ้อน
Decoratorข้อนี้ไม่แน่ใจนักว่าชอบหรือเปล่า แต่ก็เป็นสิ่งที่น่าจะมีประโยชน์ในบางโอกาส คือสิ่งที่ไพธอนเรียกว่า decorator ซึ่งหลังจากที่ทำความเข้าใจแล้ว อยากจะเรียกว่า wrapper มากกว่า
สมมุติว่าเราต้องการนับจำนวนการเรียกฟังก์ชันต่าง ๆ ในโปรแกรมของเรา เราสามารถเขียน wrapper function มาดักการเรียกของผู้ใช้แล้วแอบเพิ่มตัวนับก่อนเรียกฟังก์ชันตัวจริง และไพธอนมีวิธีการสร้าง wrapper ที่ว่านี้อย่างแนบเนียน
def call_counter (func): def wrapper (*args, **kwargs): wrapper.calls += 1 return func (*args, **kwargs) wrapper.calls = 0 wrapper.__name__ = func.__name__ return wrapper @call_counter def square (x): return x*x print (square.calls) for i in range (10): print (square (i)) print (square.calls)บรรทัด @call_counter คือ syntax ของไพธอนในการ decorate ฟังก์ชัน โดยโค้ดนี้:
@call_counter def square (x): return x*xมีความหมายเทียบเท่ากับ:
def square (x): return x*x square = call_counter (square)กล่าวคือ เป็นการส่งออบเจกต์ของฟังก์ชัน square() ให้กับฟังก์ชัน call_counter() แล้ว call_counter() คืนค่า wrapper() ซึ่งเป็นฟังก์ชันภายในมา จากนั้น ก็ใช้ค่าที่คืนมานี้ assign ค่าทับลงไปใน symbol square() เสีย ทำให้การเรียก square() หลังจากนี้ไปจะเป็นการเรียกตัวฟังก์ชัน wrapper() ที่ได้แอบเพิ่มตัวนับก่อนเรียกฟังก์ชัน square() ตัวจริงที่ได้ส่งมาก่อนหน้านี้ในพารามิเตอร์ชื่อ func
(คำอธิบายค่อนข้างซับซ้อนวนเวียนสักหน่อย หากงงก็ขอแนะนำให้อ่านรายละเอียดจาก บทเรียน นอกจากนี้ยังมี blog ที่ artima และ blog ของ Simeon Franklin ที่ให้คำอธิบายอย่างละเอียด)
อีกวิธีหนึ่งคือเขียน wrapper เป็นคลาสที่ callable ซึ่งดูสะอาดกว่า:
class call_counter: def __init__ (self, func): self.func = func self.calls = 0 def __call__ (self, *args, **kwargs): self.calls += 1 return self.func (*args, **kwargs)ประโยชน์ที่พอมองเห็นได้คือ ไพธอนมีวิธีสร้าง wrapper ที่แนบเนียน wrapper มีประโยชน์ที่ไหนก็ใช้ได้ที่นั่น (เช่น การ cache ผลการคำนวณครั้งก่อน ๆ ของฟังก์ชัน, การเพิ่มการตรวจสอบอาร์กิวเมนต์ ฯลฯ)
Libraryนอกจากตัวภาษาเองแล้ว ไพธอนยังมาพร้อมกับไลบรารีมาตรฐานอีกเพียบ ซึ่งผมคงต้องศึกษาเพิ่มเติมไปเรื่อย ๆ เท่าที่ได้ผ่านมาก็คือเรื่องการใช้ regular expression
ดูยังมีอะไรอีกเยอะให้ศึกษาข้างหน้า ที่สำคัญคือการฝึกฝนให้เกิด pythonic way ในการเขียนโค้ด และการใช้แพกเกจต่าง ๆ ให้เหมาะกับงาน
Update (2016-05-04): แก้เนื้อหาเรื่อง implementation ของ list หลังจากที่คุณวีร์ทักท้วงมาใน facebook ว่า list ของไพธอน implement ด้วย array ไม่ใช่ linked list เหมือนใน Lisp
From C++ to Python (1)
ภาษาไพธอน เป็นภาษาที่ผมอยากหาโอกาสเรียนมานานแล้ว แต่ด้วยงานส่วนใหญ่ที่ผมทำยังวนเวียนอยู่แถว ๆ ระบบระดับล่างซึ่งใช้ C/C++ เป็นหลัก ก็เลยยังปล่อยมือมาเรียนภาษาอื่นไม่ถนัดถนี่ จนกระทั่งระบบภาษาไทยเริ่มจะอยู่ตัวแล้ว ถึงเริ่มเรียนภาษาอื่น ๆ เพื่อเพิ่มโอกาสในการทำงานแขนงอื่นบ้าง
ในการเรียนครั้งนี้ ผมได้อาศัยบทเรียนจาก python-course.eu (และไปอ่านทบทวนกับ บทเรียนที่ debianclub ที่คุณวิทยาเคยลงไว้)
บทเรียนที่ python-course.eu นับว่าเหมาะกับคนที่มีพื้นฐาน C/C++ มาแล้วมาก เพราะเขาอธิบายบนพื้นฐานของคนเคยเขียนโปรแกรมมาแล้ว ไม่ใช่เริ่มต้นจากศูนย์ ยกตัวอย่างเปรียบเทียบกับ C/C++ และเน้นประเด็นที่เป็นหลุมพรางของผู้ที่ย้ายมาจาก C/C++
เท่าที่ได้ตั้งโจทย์ฝึกหัดให้กับตัวเอง ด้วยการทดลองพอร์ตโค้ดภาษา C/C++ ของตัวเองที่เคยเขียนไว้ให้เป็นไพธอน พร้อมกับทำ unit test ไปด้วย ทำให้ได้พบเจอประเด็นต่าง ๆ ที่โปรแกรมเมอร์ภาษา C/C++ จะสะดุด ผมเองก็พบว่าต้องก้าวข้ามสิ่งเหล่านี้ถึงจะเริ่มจับทางไพธอนได้ จึงเขียนบันทึกไว้สักหน่อย
Indentationข้อนี้ดูเหมือนเป็นเรื่องเล็ก แต่กลับเป็นสาเหตุหลักข้อหนึ่งที่ทำให้ผมยี้ไพธอนก่อนหน้านี้ เพราะโปรแกรมเมอร์ภาษา C/C++ จะคุ้นกับ free-form syntax และพบเจอการ indent แบบตามใจฉันมาแล้วมากมาย บางคนใช้ tab บางคนใช้ space 2, 4 หรือ 8 ช่อง บางคนใช้ปนกันทั้ง tab ทั้ง space ซึ่งซอร์สจะเละทันทีเมื่อมีการเปลี่ยนขนาดของ tab stop นี่ยังไม่นับคนที่ไม่สนใจ style ใด ๆ ทั้งสิ้นอีกนะ แต่ไม่ว่าอย่างไรโปรแกรมก็ยังคอมไพล์ผ่าน แล้วถ้ามันกลายเป็นการกำหนด syntax ของภาษา มันจะเละเทะขนาดไหน
เมื่อพยายามนึกถึงตัวอย่างอื่นที่กำหนดอะไรทำนองนี้ ผมก็นึกถึง Makefile ที่ใช้ tab ในการกำหนดขอบเขตของ rule แต่มันก็แค่ระดับเดียว ไม่ได้ซ้อนกันหลายชั้น จึงดูไม่มีอะไรมาก และอีกตัวอย่างหนึ่งคือ Fortran 77 ที่เคยเขียนในสมัยเรียน ซึ่งอาศัยตำแหน่งคอลัมน์เป็นส่วนหนึ่งของ syntax อันเป็นมรดกตกทอดมาจากสมัยใช้บัตรเจาะรู (ตอนที่เรียน Fortran 77 รู้สึกอึดอัดตรงนี้มาก เพราะตอนนั้นผ่านภาษา Pascal มาแล้ว แม้แต่ภาษา BASIC [AppleSoft, GW] ที่ว่าไม่ค่อยมีโครงสร้างก็ยังไม่ทำอะไรโลว์เทคเยี่ยงนี้) แต่ละอย่างที่นึกถึงก็ไม่ได้ชวนพิสมัยเอาเสียเลย
นั่นคือ mindset ของผมก่อนเรียน แต่ คำอธิบาย ในบทเรียนก็ทำให้ผมเข้าใจและยอมรับ ทำให้เรียนไพธอนต่อไปได้อย่างผ่อนคลาย มันคือการกำหนดขอบเขตของบล็อคคำสั่งโดยเปลี่ยนจาก style ให้เป็น syntax เสีย คนที่เขียนโปรแกรมภาษา C/C++ โดยเคร่งครัดกับ style อยู่แล้วจึงยอมรับตรงนี้ได้ไม่ยาก ส่วนประเด็นเรื่องการใช้ tab กับ space ปนกัน ไพธอนก็มีข้อกำหนดที่ชัดเจนที่ทำให้แยกแยะออกจากกันได้ คือถือเป็น indentation คนละระดับไปเลย ไม่นับปนกัน
มันคือการกำจัดวิจิกิจฉานิวรณ์ครับ ผ่านตรงนี้ไปได้ก็ลื่นไหลขึ้นเยอะ
Public, Protected, Privateภาษา C++ จะมีการกำหนด access specifier สำหรับ member ต่าง ๆ ของคลาสเป็น public, protected, private จากนั้น โปรแกรมเมอร์แต่ละคนก็จะมีวิธีการต่าง ๆ ในการตั้งชื่อ member ให้สามารถแยกแยะ access ได้ บางคนใช้ตัวพิมพ์เล็ก-พิมพ์ใหญ่ต้นชื่อ บางคนใช้ prefix บางคนใช้ suffix บางคนไม่แยกเลย (อันนี้ยุ่ง)
แต่ไพธอนไม่มี access specifier แต่จะใช้การตั้งชื่อแยกแยะทันที โดยชื่อปกติจะถือเป็น public ชื่อที่ขึ้นต้นด้วย _ ถือเป็น protected และชื่อที่ขึ้นต้นด้วย __ ถือเป็น private นับว่าเป็นการเปลี่ยน style ให้เป็น syntax อีกหนึ่งเรื่อง
Dynamic Type & Scopeการย้ายจากภาษาที่เป็น static typing มาเป็น dynamic typing จะต้องปรับโหมดความคิดสักหน่อย ซึ่งพื้นฐานภาษา BASIC สมัยเก่า บวกกับความรู้จากวิชา Compilers & Programming Languages พอช่วยได้ ไม่เป็นปัญหาสำหรับผมนัก สิ่งที่ต้องปรับเปลี่ยนแนวคิดก็เช่น:
- ชนิดของตัวแปรเป็น dynamic ไม่ใช่ตายตัวเปลี่ยนชนิดไม่ได้เหมือนในภาษา static type ทั้งหลาย ถึงตัวแปรหนึ่งจะเก็บค่า integer อยู่ คุณจะ assign สตริงหรือลิสต์ให้มันใหม่ก็ยังได้ >>> x = 1 >>> print(x) 1 >>> x = "Hello!" >>> print(x) Hello!
- scope ของตัวแปรเป็นแบบ dynamic ฟังก์ชันหนึ่ง ๆ ทำงานแต่ละครั้งอาจเข้าถึงตัวแปรได้ไม่เหมือนกัน ขึ้นอยู่กับ state ของทั้งโปรแกรมในขณะนั้น >>> def f(): ... print(s) ... >>> s = "Hello" >>> f() Hello >>> s = 2 >>> f() 2 แต่ dynamic scope นี้ก็ถูกขี่ทับด้วย block scope ได้ ถ้ามีการกำหนดตัวแปรโลคอลในชื่อเดียวกัน >>> def g(): ... s = "Bye" ... print(s) ... >>> s = "Hello" >>> g() Bye >>> print(s) Hello อ่านเพิ่มเติม
ภาษาไพธอนไม่มีพอยน์เตอร์เหมือน C/C++ แต่กลไกภายในกลับใช้พอยน์เตอร์เต็มไปหมด แม้แต่ตัวแปรกับค่าของมันก็เชื่อมกันด้วยพอยน์เตอร์ การ assign ตัวแปรก็เป็นการ assign พอยน์เตอร์ไปยังออบเจกต์ที่เป็นค่า ดังสามารถตรวจสอบได้ดังนี้:
>>> x = 1 >>> y = x >>> id(x) 10861696 >>> id(y) 10861696จะเห็นว่า หลัง assignment แล้ว x กับ y ชี้ไปยังออบเจกต์เดียวกัน ไม่ใช่แค่มีค่าเท่ากัน! อย่างไรก็ดี ถ้าเรา assign ค่าใหม่ให้กับ y จะไม่ได้ทำให้ค่าของ x เปลี่ยน แต่เป็นการกำหนดให้ y ชี้ไปยังออบเจกต์ใหม่:
>>> y = 2 >>> id(y) 10861728 >>> x 1ก็น่าจะปลอดภัยดี แถมยังเป็นการประหยัดหน่วยความจำด้วยถ้าค่าเป็นออบเจกต์ใหญ่ ๆ ที่ไม่ใช่ integer เรื่องประหยัดน่ะใช่ แต่แน่ใจหรือเรื่องความปลอดภัย?
>>> p = [1, 2, 3] >>> q = p >>> q[1] = 'x' >>> p [1, 'x', 3]จะเห็นว่าลิสต์ p เปลี่ยนตาม q หลัง assignment ทั้งนี้เพราะทั้ง p และ q ชี้ไปยังออบเจกต์เดียวกันตลอดเวลา และการ assign q[1] ก็เป็นการเปลี่ยนพอยน์เตอร์ q[1] จากที่ชี้ไปยัง integer 2 ให้ชี้ไปยัง string 'x' แทน แต่ในเมื่อ q ชี้ไปยังออบเจกต์เดียวกันกับ p การเปลี่ยนพอยน์เตอร์ q[1] จึงเป็นการเปลี่ยนพอยน์เตอร์ p[1] ด้วย!
พฤติกรรมแบบนี้ เกิดกับออบเจกต์ที่เป็น complex data structure ทั้งหมด ไม่ว่าจะเป็น list, dictionary หรือ class instance ซึ่งหากอธิบายในภาษาของ C/C++ ด้วยคำว่า พอยน์เตอร์ (จากชื่อตัวแปรไปยังค่า) ก็จะสามารถทำความเข้าใจได้ รวมถึงประโยชน์ของ deepcopy ด้วย
ความสนุกเกิดขึ้นเมื่อเราส่งอาร์กิวเมนต์ให้กับฟังก์ชัน
แบบนี้พฤติกรรมจะเหมือน call by value:
>>> def f(x): ... x = x + [1] ... >>> p = [1, 2, 3] >>> f(p) >>> p [1, 2, 3]แต่แบบนี้กลับเหมือน call by reference:
>>> def g(x): ... x += [1] ... >>> p = [1, 2, 3] >>> g(p) >>> p [1, 2, 3, 1]คำอธิบายก็คือ x ซึ่งเป็นพารามิเตอร์ของ f() และ g() นั้น จะก็อปปี้พอยน์เตอร์ไปยังค่าของ p มาทั้งคู่ จากนั้น x ใน f() ถูก assign ให้ชี้ไปยังออบเจกต์ใหม่ที่เป็นผลลัพธ์ของการบวก x กับลิสต์ [1] ในขณะที่ x ใน g() ถูกเพิ่มอิลิเมนต์ใหม่ต่อท้ายโดยตรงในออบเจกต์เดิม ซึ่งเป็นออบเจกต์เดียวกับที่ p ของผู้เรียกชี้อยู่ ผลจึงเป็นการเปลี่ยนค่าของ p ของผู้เรียกไปด้วย
คำถามที่ว่า การเรียกฟังก์ชันของไพธอนเป็น call by value หรือ call by reference จึงตอบได้แค่ว่า ไม่ใช่ทั้งสองอย่าง ผู้ที่ย้ายมากจากภาษา C/C++ ต้องระวังให้ดี ภาษาไพธอนไม่มีพอยน์เตอร์ก็จริง แต่เวลาเขียนไพธอนให้นึกถึงพอยน์เตอร์เข้าไว้
Function Overloading?ฟังก์ชันในภาษา C++ สามารถโอเวอร์โหลดเพื่อรับพารามิเตอร์หลายแบบได้ ถึงแม้มันจะเพิ่มความยุ่งยากในการลิงก์จากโค้ดภายนอกอันเนื่องมาจาก symbol mangling แต่มันก็ไม่ได้สร้างขึ้นมาเท่ ๆ มี use case ที่ได้ประโยชน์จากการโอเวอร์โหลดฟังก์ชัน เช่น:
- ช่วยให้สร้าง constructor หลายแบบได้
- ช่วยในการ overload operator เพื่อรับ operand หลายชนิดได้
แต่ไพธอนไม่สามารถโอเวอร์โหลดฟังก์ชันได้ มีให้อย่างมากก็แค่การใช้ default argument แต่ถ้ากำหนดฟังก์ชันชื่อเดียวกันหลายครั้ง มันก็จะเอาอันหลังสุดเท่านั้น ถือว่าทับอันแรก ๆ ไป
ด้วยความเป็น dynamic typing ของภาษาไพธอน ทำให้พอเข้าใจได้ว่าการโอเวอร์โหลดฟังก์ชันสามารถทำให้เกิดความยุ่งยากได้ กรณีทั่วไปเราอาจเลี่ยงได้ด้วยการตั้งชื่อฟังก์ชันหลบกันเสีย แต่สำหรับกรณีของ magic methods ทั้งหลายของคลาส เราไม่สามารถตั้งชื่อหลบได้ ซึ่งกรณีของ constructor และ operator overloading ก็เข้าข่าย magic methods ทั้งสิ้น
แล้วจะจัดการกับ use case ข้างต้นได้อย่างไร?
การโอเวอร์โหลด constructorกรณีที่สามารถใช้ default argument ได้ ก็ใช้ default argument เช่น:
class Time: def __init__ (self, h=0, m=0, s=0): self.h, self.m, self.s = h, m, s t1 = Time() t2 = Time(8) t3 = Time(8, 20) t4 = Time(8, 20, 45)หากโอเวอร์โหลดโดยใช้อาร์กิวเมนต์ต่างชนิดกัน ก็ไม่สามารถใช้ default argument ได้ ก็อาจใช้วิธีพิเศษ เช่น การใช้ argument tuple หรือ argument dict:
class Time: def __init__ (self, *args): if len (args) == 1 and type (args[0]) == str: h, m, s = args[0].split(":") self.h, self.m, self.s = int(h), int(m), int(s) else: self.h, self.m, self.s = 0, 0, 0 if len (args) >= 1: self.h = int(args[0]) if len (args) >= 2: self.m = int(args[1]) if len (args) >= 3: self.s = int(args[2]) t1 = Time() t2 = Time(8) t3 = Time(8, 20) t4 = Time(8, 20, 45) t5 = Time("8:20:50")หรือใช้ factory method ซะเลย:
class Time: @classmethod def from_str (cls, s): h, m, s = s.split(":") return cls (int(h), int(m), int(s)) @classmethod def from_hms (cls, h=0, m=0, s=0): return cls (h, m, s) def __init__ (self, h, m, s): self.h, self.m, self.s = h, m, s t1 = Time.from_hms() t2 = Time.from_hms(8) t3 = Time.from_hms(8, 20) t4 = Time.from_hms(8, 20, 45) t5 = Time.from_str("8:20:50")(ดัดแปลงจาก กระทู้ Stack Overflow)
การโอเวอร์โหลด operatorสมมุติว่าเรามีคลาส Date (วันที่) ซึ่งต้องการโอเวอร์โหลดเครื่องหมายลบดังนี้:
d1 = Date("2016-04-26") d2 = Date("2016-05-03") assert d2 - d1 == 7 assert d2 - 7 == d1กล่าวคือ:
- ถ้าตัวลบเป็นชนิด Date ให้หาจำนวนวันระหว่างวันที่ทั้งสอง
- ถ้าตัวลบเป็นชนิด int ให้หาวันที่ถอยหลังเป็นจำนวนวันที่ลบ
กรณีนี้ดูจะไม่มีทางอื่น นอกจากตรวจสอบชนิดของตัวลบเอา:
class Date: # ... def __sub__ (self, other): if type (other) == int: # ... subtract days from self ... elif type (other) == Date: # ... subtract two Dates ... else: raise TypeError ("Invalid operand type")ซึ่งออกจะดูอัปลักษณ์ถ้าเป็นโค้ด C++ แต่นี่คือไพธอนมาตรฐาน
อย่างไรก็ดี เท่าที่ลองค้นดู ดูเหมือนจะมีแพกเกจ overload และ multimethod เพื่อการนี้ และดูจะมี PEP 3124 เพื่อเพิ่มการรองรับการโอเวอร์โหลดฟังก์ชันอย่างเป็นทางการ แต่ยังอยู่ในสถานะ Deferred อยู่
Polymorphism?หนึ่งในเครื่องมือที่ใช้กันมากของ OOP ก้คือ polymorphism ซึ่งในภาษา C++ จะใช้ virtual function ประกอบกันกับ class hierarchy ซึ่ง implementation ภายในคือ pointer to function ใน v-table ของคลาส
แต่พอมาเขียนไพธอน คุณจะหา keyword หรือ naming convention ที่เทียบเคียงกับ virtual function ไม่ได้เลย ทั้งนี้เพราะไพธอนเป็น polymorphic โดยธรรมชาติอยู่แล้ว!
เวลาที่เขียนฟังก์ชันแบบนี้ใน C++:
inline int max (int x, int y) { return (x > y) ? x : y; } inline int max (double x, double y) { return (x > y) ? x : y; }หรือจะใช้ generic programming ด้วย template ซึ่ง implementation ภายในเทียบเท่ากัน แต่ใช้กับชนิดใดก็ได้ที่รองรับ operator > :
template <class T> inline int max (T x, T y) { return (x > y) ? x : y; }แต่ในไพธอนคุณเขียนแค่นี้ก็ทำงานได้กับทุกชนิดแล้ว:
def max (x, y): return x if x > y else yเพราะ dynamic typing นั่นเอง ทำให้สามารถส่งออบเจกต์ชนิดไหนก็ได้ แล้วไปว่ากันที่ run-time ถ้าชนิดนั้น ๆ รองรับ operation ที่เรียกใช้ ก็เป็นอันใช้ได้ ตามแนวคิดที่เรียกว่า duck-typing ซึ่งกล่าวว่า If it looks like a duck and quacks like a duck, it must be a duck.
คุณจึงสามารถใช้ polymorphism ได้ ไม่ว่าจะเขียนโค้ดแบบนี้:
class Animal: def cry (self): pass class Cat (Animal): def cry (self): print ("Meow!") class Duck (Animal): def cry (self): print ("Quack!") farm = [] farm.append (Cat()) farm.append (Duck()) for i in farm: i.cry()หรือแบบนี้:
class Cat: def cry (self): print ("Meow!") class Duck: def cry (self): print ("Quack!") farm = [] farm.append (Cat()) farm.append (Duck()) for i in farm: i.cry()คงพอเห็นภาพนะครับ
blog นี้เขียนถึงสิ่งที่สะดุด ก็ชักจะยาวแล้ว เดี๋ยว blog หน้าค่อยเขียนถึงสิ่งที่ผมชอบในไพธอนต่อนะครับ
หมายเหตุ: ด้วยความที่ผมยังเตาะแตะกับไพธอนอยู่ ที่เขียนไปอาจมีข้อผิดพลาดจากความไม่เข้าใจ ก็ยินดีรับข้อชี้แนะจากผู้รู้ครับ
Thai Font Metrics
ประเด็นเล็ก ๆ ประเด็นหนึ่งที่ถูกอภิปรายกันในหลายโอกาสในหมู่คนทำฟอนต์ไทย หรือกระทั่งในหมู่ผู้ใช้ที่ต้องเตรียมเอกสารให้เข้ากับข้อกำหนด คือเรื่องขนาดของฟอนต์ไทยที่จะเล็กกว่าฟอนต์ตะวันตกที่ point size เดียวกัน เช่น บทความภาษาอังกฤษอาจกำหนดขนาดฟอนต์เป็น 10 หรือ 11 point แต่ถ้าใช้ฟอนต์ไทยขนาดเดียวกันจะเล็กจนอ่านไม่ออก ต้องปรับขนาดเพิ่มเป็น 14 หรือ 16 point ถึงจะเทียบเคียงกันได้ เรื่องนี้คุณเนยสดได้ เขียนอธิบายไว้แล้วเป็นอย่างดี
ฟอนต์จาก TLWGสำหรับฟอนต์ชุดต่าง ๆ ที่ TLWG ผมได้ปรับขนาดตัวอักษรให้ใหญ่ขึ้น เพื่อให้เข้ากันกับฟอนต์ตะวันตกทั้งหมด ไม่ว่าจะเป็น Fonts-TLWG, Fonts-SIPA-Arundina หรือ ThaiFonts-Siampradesh ทำให้เกิดความไม่เข้ากันกับฟอนต์ไทยอื่น ๆ ที่มีอยู่ในตลาด
สำหรับที่มาที่ไป ผมตัดสินใจใช้ font metrics ที่เข้ากันกับฟอนต์ตะวันตกหลังจากที่ได้พูดคุยกับผู้ใช้และนักพัฒนาใน thread หนึ่งใน gtk-i18n list เมื่อปี 2547 โดยในขณะนั้น ฟอนต์ต่าง ๆ ที่พัฒนา ปรับปรุง และเผยแพร่โดย TLWG ยังใช้ขนาดเหมือนฟอนต์ไทยในตลาด และมีฝรั่งที่พยายามเรียนภาษาไทยบ่นเข้ามาว่าฟอนต์ไทยตัวเล็กมาก อ่านไม่ออก มีฟอนต์ที่ตัวใหญ่กว่านี้แนะนำไหม ผมพยายามอธิบายเหตุผลที่ฟอนต์ไทยต้องตัวเล็ก ว่าเราต้องเผื่อเนื้อที่ให้กับสระบน-ล่างและวรรณยุกต์ ก็ปรากฏว่านักพัฒนา Pango (Owen Taylor) ได้ แนะนำ ว่าสามารถใช้ขนาดตัวอักษรที่เท่ากับฟอนต์ตะวันตกได้ โดยเพียงแต่ขยายระยะระหว่างบรรทัดให้สูงขึ้น และได้รับการ สำทับ จาก Javier Sola นักพัฒนา Khmer OS ว่าฟอนต์ภาษาเขมรก็ใช้วิธีนี้ และได้ผลดี
ในขณะนั้น เรามีฟอนต์ Loma จาก NECTEC ที่เริ่มบุกเบิกทำฟอนต์ UI โดยใช้ metrics ที่สอดคล้องกับฟอนต์ตะวันตกเป็นตัวอย่างอยู่แล้ว หลังจากที่ในวินโดวส์มีฟอนต์ Tahoma ที่ทำงานในลักษณะนี้มาแล้วระยะหนึ่ง เมื่อนำมาประกอบกับข้อมูลที่ได้จากชุมชน GTK+ ดังกล่าว ผมจึงตัดสินใจปรับขนาดฟอนต์ไทยทั้งหมดในแหล่งของ TLWG ตามฟอนต์ตะวันตกตั้งแต่นั้นมา
Font Metrics แบบไทยย้อนกลับไปที่ที่มาของ font metrics แบบไทยที่มีการย่อส่วนลงมา เหตุผลเป็นที่เข้าใจได้ไม่ยาก ว่ามาจากการเผื่อเนื้อที่ให้กับสระบน-ล่างและวรรณยุกต์ ทำให้ต้องย่อขนาดของพยัญชนะลง และเพื่อให้เข้ากันกับตัวโรมัน ก็จำเป็นต้องย่อขนาดของตัวโรมันลงตามด้วย ทำให้ตัวโรมันของฟอนต์ไทยมีขนาดเหลือเพียงประมาณ 70% ของฟอนต์ตะวันตกที่มี point size เท่ากัน
เรื่องนี้มีตัวอย่างอย่างละเอียดในหนังสือ แบบตัวพิมพ์ไทย ที่จัดพิมพ์โดยโครงการฟอนต์แห่งชาติของ NECTEC เมื่อ พ.ศ. 2543

การใช้ font metrics แบบไทยดูจะทำงานได้ดี และเราก็ใช้งานแบบนี้กันมานาน ตั้งแต่ยุค Windows 3.1 ที่ยังใช้รหัส สมอ. และมี Windows Thai Edition ใช้งานกันอยู่ มาจนถึงยุคเปลี่ยนผ่านสู่ I18N และ Unicode ใน Windows 95, Windows XP แล้วเราก็เริ่มเจออะไรทำนองนี้ในเว็บไซต์:

ภาพนี้ผมจำลองขึ้นใหม่ เนื่องจากไม่มีระบบรุ่นเก่าให้จับภาพแล้ว แต่คงจะพอจำความรู้สึกนี้ได้ ที่เวลาอ่านเว็บไซต์ต่าง ๆ แล้ว เจอข้อความที่ภาษาไทยเล็กเท่ามด ภาษาอังกฤษใหญ่เท่าหม้อข้าว เพราะ text rendering engine แบบ multilingual ยุคแรก ๆ พยายามแสดงข้อความโดยแยกฟอนต์ตามภาษาเขียน แต่มันไม่แยกแยะว่าภาษาไทยต้องขยาย หรือภาษาอังกฤษต้องย่อ ส่วนข้อความภาษาเขมรนั้น ผมจำลองใส่เข้าไปด้วยเพื่อเปรียบเทียบให้ดูว่าเขา implement แบบไหน
rendering engine ยุคหลัง ๆ เริ่มฉลาดขึ้น โดยพยายามเลือกฟอนต์ตามภาษาหลักหรือตามโลแคล ถ้าฟอนต์นั้นมีอักษรโรมันให้ก็นำมาใช้เลย ถ้าไม่มีจึงจะไปหาจากฟอนต์อื่น ช่วยบรรเทาปัญหาข้อความผสมภาษาไทย-อังกฤษลงได้
แล้วโลกก็หมุนต่อไป สังคมไทยเริ่มเข้าสู่ยุคที่มีภาษาที่สามที่สี่ เด็ก ๆ เริ่มเรียนภาษาจีน ญี่ปุ่น เกาหลี ฯลฯ กันมากขึ้น ประชาคมเศรษฐกิจอาเซียนเริ่มรวมตัวกัน เริ่มมีข้อความภาษาลาว เขมร พม่า เข้ามามากขึ้น การใช้งานแบบ multilingual เริ่มเข้มข้นขึ้นกว่าแต่ก่อนที่เคยมีแค่ไทย-อังกฤษ
คำถามคือ เราจะจัดการระบบ multilingual นี้อย่างไร? เดิมมีแค่สองภาษา ฟอนต์อังกฤษมันโตเกินไป เราก็เพิ่มอักษรอังกฤษย่อส่วนลงในฟอนต์ไทยเสียก็สิ้นเรื่อง แต่เมื่อมีภาษาจีน ญี่ปุ่น เกาหลี ลาว เขมร พม่า เข้ามาร่วมด้วย เราจะเพิ่มอักษรของภาษาเหล่านั้นลงในฟอนต์ไทยหมดไหม? เอาแค่อักษรจีนอย่างต่ำ 5,000 ตัวก็อ่วมอรไทแล้ว ไหนจะอักษรเขมรที่มีอักษรตัวเชิง ทำให้ต้องเผื่อเนื้อที่บน-ล่างกว้างกว่าอักษรไทยเสียอีก เราจะได้ฟอนต์ตัวเล็กลงไปอีก และถ้าสักวันเราจะเพิ่ม อักษรทิเบต (ไม่แน่นะครับ ก็เราชอบประเทศภูฏานกันมากไม่ใช่หรือ) ที่ซ้อนกันสนุกสนานกว่าอักษรเขมรเสียอีก เราจะยิ่งได้ฟอนต์ที่เล็กกระจิ๋วหลิวเลยทีเดียว
เริ่มเห็นภาพกันไหมครับ ว่าการเผื่อช่องว่างสำหรับการซ้อนอักขระมันไม่ scale ในระบบ multilingual
หรือหากผลักภาระไปให้ rendering engine ที่จะต้องจดจำว่าภาษาแต่ละภาษาต้องย่อ-ขยายด้วยอัตราเท่าไรแล้วปรับขนาดฟอนต์เอา มันก็เป็น workaround ที่ไปเพิ่มความยุ่งยากให้กับการออกแบบฟอนต์คู่สองภาษาอื่น ๆ เช่น การสร้างฟอนต์ที่มีอักษรไทย-ลาว, ไทย-เขมร, ไทย-พม่า, ไทย-ยาวี เพื่อใช้ในบริบทของกลุ่มผู้ใช้ทวิภาษา จะต้องออกแบบฟอนต์ให้อักษรแต่ละภาษามีขนาดไม่เท่ากันในฟอนต์เดียวกัน และถ้าเกิดว่า rendering engine ของแต่ละระบบใช้อัตราย่อ-ขยายของแต่ละภาษาต่างกันอีกล่ะ? คงจะพอจินตนาการถึงความยุ่งยากกันได้ และโชคดีที่ไม่มี rendering engine ไหนคิดทำอะไรทำนองนี้
ถ้าเช่นนั้น แบบไหนล่ะถึงจะ scale?
ทางออกระบบที่ดูสมเหตุสมผลกว่าก็คือ ทุกภาษาควรอิงบรรทัดฐานเดียวกัน กล่าวคือ
กำหนดให้ point size คือความสูงของตัวอักษร ไม่ใช่ความสูงของบรรทัดเมื่อกำหนดอย่างนี้ แล้วไปขยายขนาดตัวอักษรไทยทั้งหมดให้สูงเท่า point size ซึ่งจะทำให้วรรณยุกต์เขยิบขึ้นสูงจนตกขอบด้านบนของ em-box นักพัฒนาฟอนต์ก็อาจเกิดประเด็นคำถามต่อไปนี้:
- จะกำหนดความสูงของบรรทัดให้สูงกว่า em-box ได้อย่างไร?
- การที่ glyph ของวรรณยุกต์ตกขอบ em-box ซึ่งเป็น bounding box ออกไป จะไม่ผิดหลักการหรือ?
- font metrics แบบใหม่ จะขัดกันกับแบบเดิมที่ใช้ในเอกสารต่าง ๆ ไหม?
ก็จะตอบทีละประเด็นนะครับ
การกำหนดความสูงของบรรทัดโดยปกติที่ผ่านมา ฟอนต์ไทยเคร่งครัดกับเรื่องความสูงของบรรทัดที่จะไม่ให้เกิน em-box ทำให้เราต้องย่อขนาดตัวอักษรทั้งหมดให้เล็กลงเพื่อให้สามารถบรรจุสระบน-ล่างและวรรณยุกต์ลงไปใน em-box ได้
แต่ในการคำนวณระยะระหว่างบรรทัดของโปรแกรมต่าง ๆ ที่ใช้ฟอนต์ TrueType หรือ OpenType จะไม่ได้ใช้ ascender/descender จาก em-box นี้โดยตรง แต่จะใช้ค่า sTypoAscender, sTypoDescender และ sTypoLineGap จาก ตาราง OS/2 & Windows Metrics ในตัวฟอนต์ ซึ่งเราสามารถกำหนดค่า sTypoAscender และ sTypoDescender ให้เลย em-box ออกไปได้ และอาจกำหนดค่า usWinAscent และ usWinDescent ด้วย เพื่อไม่ให้บิตแม็ปของตัวอักษรที่วาดถูกขลิบออก
อย่างไรก็ดี ในทางปฏิบัติแล้ว ค่า usWinAscent และ usWinDescent กลับเป็นค่าที่มีผลต่อการคำนวณระยะระหว่างบรรทัดมากกว่า (app ต่าง ๆ ไม่ได้ทำตาม spec ของไมโครซอฟท์นัก แม้ใน spec ของไมโครซอฟท์จะเขียนไว้ว่า This is strongly discouraged. ก็ตาม
โดยสรุปก็คือ ควรกำหนดค่าทั้ง sTypoAscender, sTypoDescender, usWinAscent, usWinDescent ทั้งหมดไว้ก่อน
หากใช้ Fontforge ก็กำหนดได้ในแท็บ OS/2 Metrics (Element > Font Info > OS/2 > Metrics)

ในยุคก่อน เรามีการจัดตำแหน่งสระบน-ล่างและวรรณยุกต์เพื่อหลบหางพยัญชนะโดยใช้วิธีสร้าง glyph ชุดพิเศษที่มีการเลื่อนตำแหน่งรอไว้ แล้ว rendering engine จะเลือกใช้ glyph ชุดพิเศษเหล่านั้นตามความเหมาะสม เป็นเทคนิคที่เขาเรียกกันว่า positioning by substitution
glyph ชุดพิเศษต่าง ๆ เหล่านี้ จะเลื่อนระยะไว้เรียบร้อยเพื่อให้นำไปวางซ้อนได้พอดีโดยไม่มีการเลื่อนที่อีก ดังนั้น หากจะใช้เทคนิคนี้กับฟอนต์ที่ขยายขนาดขึ้น glyph ของวรรณยุกต์ที่เลื่อนระยะรอไว้ก็จะต้องตกขอบ em-box อย่างเลี่ยงไม่ได้ (แต่ยังอยู่ภายในความสูงของบรรทัด)
แต่นั่นเป็นข้อจำกัดของระบบเก่าก่อนที่จะมี OpenType
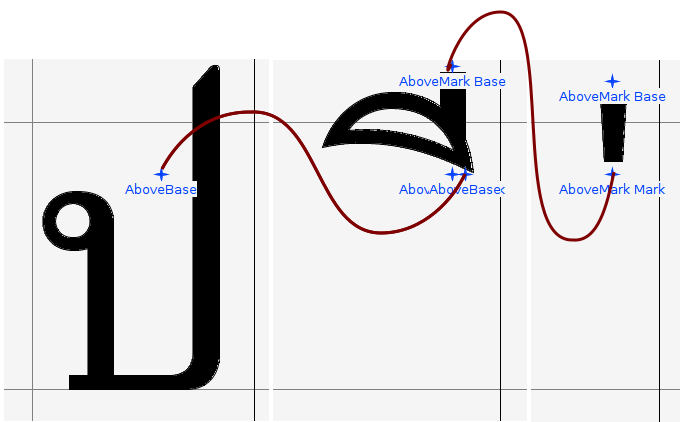
ด้วยเทคโนโลยี OpenType เรามีเครื่องมือจัดตำแหน่งการวางซ้อนอักขระ โดยใช้ข้อมูล GPOS ซึ่งอาศัยการกำหนด anchor สำหรับวาง glyph ซ้อนกันเหมือนการต่อชิ้นส่วนเลโก้ โดย glyph ที่เป็นฐานจะมี base anchor เป็นเหมือนเบ้าเสียบรอไว้ ส่วน glyph ที่จะมาวางซ้อนก็จะมี mark anchor เป็นเหมือนเดือยสำหรับเสียบเข้ากับเบ้า
ในการวาง glyph ที่มาซ้อนนั้น ตำแหน่ง glyph ตัวสวมจะถูกเลื่อนที่ด้วยเวกเตอร์ระหว่าง anchor เสียบกับ anchor เบ้า เพื่อให้ anchor สวมกันได้พอดี ดังนั้น ตำแหน่งเดิมของ glyph จะอยู่ที่ไหนก็ไม่สำคัญ เพราะยังไงก็สามารถคำนวณเวกเตอร์ดังกล่าวได้อยู่แล้ว ทำให้เราสามารถวาง glyph ของวรรณยุกต์ไว้ภายใน em-box ก็ได้ถ้าต้องการ นักพัฒนาฟอนต์ที่เคร่งครัดกับ em-box จึงวางใจได้
สำหรับผู้ที่สนใจ ไมโครซอฟท์มีเอกสารแนะนำ การสร้างฟอนต์ OpenType สำหรับอักษรไทย โดยเฉพาะ
ความเข้ากันได้กับฟอนต์เดิมประเด็นนี้ ตอบได้สั้น ๆ ว่า ไม่เข้ากันแน่นอน หากจะเปลี่ยนมาใช้ metrics ใหม่ จะต้องมีการจัดการกับความเปลี่ยนแปลง และคงไม่ใช่เรื่องที่จะทำได้ชั่วข้ามคืน ผมเองก็ไม่เคยคิดว่ามันจะเกิดในอนาคตอันใกล้ จนกระทั่งเริ่มสังเกตเห็นแนวโน้มความเปลี่ยนแปลงบางอย่าง กล่าวคือ
- ฟอนต์นานาภาษา ที่มีอักษรของภาษาต่าง ๆ ทั่วโลกเริ่มมีมากขึ้น หลังจากเทคโนโลยี multilingual เริ่มอยู่ตัวและใช้กันเป็นปกติ เช่น
- Freefont จาก GNU Project (มีอักษรไทย)
- Noto Fonts จาก Google (มีอักษรไทย)
- DejaVu fork จาก Bitstream Vera (ยังไม่มีอักษรไทย)
- web font ไทย
- คัดสรร ดีมาก (Cadson Demak) เท่าที่ตรวจสอบเฉพาะ 3 ฟอนต์ใน Google Fonts พบว่าใช้ font metrics ที่ point size = ขนาดตัวอักษร และใช้ GPOS ในการเลื่อนวรรณยุกต์ขึ้นสูงจาก em-box
หากแนวโน้มการสร้างฟอนต์นานาภาษาเพื่อใช้ในระบบต่าง ๆ มีมากขึ้น (ผมยังไม่ได้ตรวจสอบฟอนต์ที่ใช้ในสมาร์ทโฟนต่าง ๆ) และการใช้ฟอนต์ในเว็บไซต์ต่าง ๆ ก็มีมากขึ้น จึงน่าสนใจว่าแนวโน้มเหล่านี้จะมีผลเปลี่ยนแปลงการใช้ฟอนต์ในเดสก์ท็อปปัจจุบันมากน้อยแค่ไหน คงต้องรอดูกันต่อไป โดยเฉพาะบนวินโดวส์ที่มีฟอนต์ Tahoma ให้ใช้กันเป็นตัวอย่างมานานแล้ว
และสุดท้ายก็อยู่ที่ผู้พัฒนาฟอนต์ทั้งหลายนั่นแหละครับ ว่าจะขยับไปสู่แนวทางนี้กันมากน้อยแค่ไหน
Thanks
ขอขอบคุณย้อนหลัง สำหรับผู้สนับสนุนงานพัฒนาซอฟต์แวร์เสรีของผมในช่วงตุลาคม 2558 ถึงมกราคม 2559 ที่ผ่านมาครับ คือ:
- เดือนตุลาคม 2558
- อ.พฤษภ์ บุญมา
- ผู้ไม่ประสงค์จะออกนาม
- คุณธนาธิป ศรีวิรุฬห์ชัย
- ผู้ไม่แสดงตน 1 ท่าน
- เดือนพฤศจิกายน 2558
- อ.พฤษภ์ บุญมา
- คุณธนาธิป ศรีวิรุฬห์ชัย
- ผู้ไม่ประสงค์จะออกนาม
- เดือนธันวาคม 2558
- คุณธนาธิป ศรีวิรุฬห์ชัย
- คุณปฏิพัทธ์ สุสำเภา
- เดือนมกราคม 2559
- อ.พฤษภ์ บุญมา
- คุณธนาธิป ศรีวิรุฬห์ชัย
- คุณ RERNG-RIT
- ผู้ไม่ประสงค์จะออกนาม
ขอให้ทุกท่านเจริญด้วยอายุ วรรณะ สุขะ พละ การงานเจริญก้าวหน้า คิดหวังสิ่งใดก็ขอให้สมดังปรารถนาครับ
สี่เดือนผ่านไป งานที่ได้ทำไปในช่วงนี้ก็คือ:
- ทำ libthai ให้ thread-safe พร้อมทั้ง optimize libthai อีกนิดหน่อย ได้เป็น libthai 0.1.23 ตามด้วยการแก้บั๊กใน libthai 0.1.24
- เตรียม libthai udeb เพื่อใช้ใน debian-installer
- พัฒนา Fonts-TLWG ให้รองรับการเขียนภาษามลายูปาตานี และออกรุ่น Fonts-TLWG 0.6.2
- เตรียมแพกเกจ OTF และ WOFF สำหรับ Fonts-TLWG บน Debian
- งานแปล: Xfce, GNOME, Debian Installer ตามปกติ
- ปรับแก้ Debian package ของ libdatrie และ libthai โดยประเด็นหลักคือ:
- แก้ให้ libdatrie-doc และ libthai-doc ใช้ไฟล์ jquery.js ของระบบ (จากแพกเกจ libjs-jquery) แทนฉบับที่ doxygen embed ให้ ช่วยประหยัดเนื้อที่ได้ถึง 146 KB และการใช้สคริปต์ร่วมกันยังช่วยให้สามารถปรับรุ่นทั้งระบบได้สะดวก
- เขียน debian/rules ใหม่ จากการเรียก dh_* ตรง ๆ มาเป็นการใช้ dh ซึ่งทำให้กฎกระชับลงอย่างมาก และยังได้แพกเกจ -dbgsym สำหรับการดีบั๊กโดยอัตโนมัติอีกด้วย
- แก้ปัญหา FTBFS ด้วย GCC 6 ที่เกิดจาก libthai (หลังจากย้ายมา GCC 5 ใน Jessie ครั้งหนึ่งแล้ว Debian Stretch กำลังจะใช้ GCC 6 เป็นรุ่น default)
ช่วงเทอมที่ผ่านมา (ส.ค. - ธ.ค. 2558) ผมรับงานสอน เป็นอาจารย์พิเศษที่มหาวิทยาลัยแห่งหนึ่ง ต้องบริหารเวลาอย่างหนัก ทั้งกิจกรรมของครอบครัวเล็ก ครอบครัวใหญ่ ทั้งงานสอนที่ต้องเตรียมสอน ออกข้อสอบ วัดผล แล้วก็สลับมาทำงานซอฟต์แวร์เสรีไปด้วย ทำให้หายไปจาก social network พักใหญ่ บางช่วงไม่ได้เข้าไปเช็กอะไรเลยเกือบทั้งอาทิตย์ บางช่วงได้แต่เช็กอะไรในช่วงสั้น ๆ ไม่สามารถโต้ตอบได้ ตอนนี้ก็พยายามกลับมาทำงานต่อ กลับมาคุยกับชาวบ้านได้มากขึ้น (นิดหน่อย) ล่ะครับ ^_^'
ภาษีสรรพสามิตช่วยลดก๊าซคาร์บอนไดออกไซด์จริงหรือ
Blog นี้จำกัดวงที่เกี่ยวกับการใช้รถยนต์ และภาษีสรรพสามิตรรถยนต์ใหม่ ที่เริ่มบังคับใช้ในปี 1 มกราคม พ.ศ.2559 นี้ สำหรับ 2 ประเด็นคือ ผู้เกี่ยวข้องกับรถยนต์ และเชื้อเพลิงรถยนต์
หลักการการกำหนดผู้รับผิดชอบ Pollutionใช้หลักการของ Polluter Pays Principle: PPP คือ ผู้ที่มีอำนาจควบคุมสั่งการการเดินเครื่องควร (should) รับผิดชอบความเสียหายและค่าใช้จ่ายอันเกิดจากมลสารที่ปล่อยออกซึ่งมีผลกระทบต่อสังคม หลักการนี้ได้ถูกกำหนดมาจากประเทศพัฒนาแล้ว (OECD: The Organisation for Economic Co-operation and Development) แล้วตั้งแต่ปี ค.ศ. 1972 (พ.ศ.2515)
จากหลักการนี้ผู้เกี่ยวข้องกับรถยนต์ ประกอบไปด้วย ผู้ผลิต ผู้ขับรถยนต์ทั้งเจ้าของรถและไม่ใช่เจ้าของรถ สำหรับผู้ผลิตจะต้องรับผิดชอบต่อ Pollution ในการสั่งผลิตของโรงงาน แต่เมื่อรถยนต์คันใหม่ถูกซื้อโดยผู้ใช้งาน จะถือการครอบครองของผู้จ่ายเงินซื้อรถยนต์คันนั้นมาใช้งาน นั่นคือ ซื้อเทคโนโลยีและซื้อเครื่องที่ใช้เชื้อเพลิงนั้นมาเป็นของเรา ซึ่งเจ้าของรถควรรับผิดชอบ Pollution ที่เกิดจากการปล่อยด้วย อย่างไรก็ตาม ประเด็นนี้มีช่องโหว่ คือ ทำไมไม่เป็น Consumer Pays Principle เช่น ผู้โดยสารเลือกที่จะไปรถแบบใดก็ได้ รถเมล์ รถตู้(ดีเซล/NGV) รถแท๊กซี่(Gasoline/NGV) และยังเป็นผู้ตัดสินใจเลือกคือสั่งการเองด้วย แท้จริงแล้วมีความรับผิดชอบร่วมกัน แต่อย่างไรก็ตาม สัดส่วนที่เหมาะสมต่อการแบ่งความรับผิดชอบนี่สิ ที่ยังหาหลักการไม่ได้ อีกอย่างการประกาศใช้หลักการนี้เริ่มจากประเทศพัฒนาแล้ว ดังนั้นแนวคิดที่จะไปยัง Consumer ย่อมห่างไกลและไม่แสดงความเป็นประเทศผู้นำ อีกทั้งเรื่องแบบนี้ถ้าวางความรับผิดชอบไว้กับผู้ที่มีศักยภาพน้อยทั้งเงินลงทุน เทคโนโลยี องค์ความรู้สะสม ย่อมทำให้ระบบในเชิงปฏิบัติเกิดได้ยาก แถมอาจเกิดการต่อต้านระดับประเทศขึ้นอีก
เป็นที่รู้กันโดยทั่วไปว่า เชื้อเพลิงที่ปล่อยก๊าซคาร์บอนไดออกไซด์เทียบเท่า (CO2eq) มีอัตราการปล่อยต่อหน่วย ตามประกาศขององค์การบริหารจัดการก๊าซเรือนกระจก ดังนี้
เมื่อคำนวณตามอัตราการใช้งานรถแบบปกติในเมืองเปรียบเทียบกับอัตราภาษีขั้นต่ำของรถแต่ละแบบตามการบังคับใช้ แสดงดังภาพ
 เปรียบเทียบปริมาณการปล่อยก๊าซคาร์บอนไดออกไซด์(เทียบเท่า) ต่อกิโลเมตร กับ อัตราการเก็บภาษีสรรพสามิตรถยนต์ใหม่
เปรียบเทียบปริมาณการปล่อยก๊าซคาร์บอนไดออกไซด์(เทียบเท่า) ต่อกิโลเมตร กับ อัตราการเก็บภาษีสรรพสามิตรถยนต์ใหม่
จากการเปรียบเทียบเห็นทิศทางที่สวนทางกันซึ่งถ้าไม่ได้รับคำอธิบาย ประชาชนอาจเข้าใจไปได้ว่า อัตราการเก็บภาษีมากไปน้อยเรียงจากเชื้อเพลิงสกปรกมากกว่าและลดหลั่นกันไปตามการเก็บฯ
ทิศทางการบังคับใช้ภาษีรถยนต์
หมายเหตุ: ก๊าซคาร์บอนไดออกไซด์ ในพระราชบัญญัติส่งเสริมและรักษาคุณภาพสิ่งแวดล้อมแห่งชาติ พ.ศ. 2535 ยังไม่มีการระบุว่าเป็นมลพิษ จึงใช้คำว่า Pollution แทน
The post ภาษีสรรพสามิตช่วยลดก๊าซคาร์บอนไดออกไซด์จริงหรือ appeared first on EnergyThai.
ภาษีสรรพสามิตช่วยลดก๊าซคาร์บอนไดออกไซด์จริงหรือ
Blog นี้จำกัดวงที่เกี่ยวกับการใช้รถยนต์ และภาษีสรรพสามิตรรถยนต์ใหม่ ที่เริ่มบังคับใช้ในปี 1 มกราคม พ.ศ.2559 นี้ สำหรับ 2 ประเด็นคือ ผู้เกี่ยวข้องกับรถยนต์ และเชื้อเพลิงรถยนต์
หลักการการกำหนดผู้รับผิดชอบ Pollutionใช้หลักการของ Polluter Pays Principle: PPP คือ ผู้ที่มีอำนาจควบคุมสั่งการการเดินเครื่องควร (should) รับผิดชอบความเสียหายและค่าใช้จ่ายอันเกิดจากมลสารที่ปล่อยออกซึ่งมีผลกระทบต่อสังคม หลักการนี้ได้ถูกกำหนดมาจากประเทศพัฒนาแล้ว (OECD: The Organisation for Economic Co-operation and Development) แล้วตั้งแต่ปี ค.ศ. 1972 (พ.ศ.2515)
จากหลักการนี้ผู้เกี่ยวข้องกับรถยนต์ ประกอบไปด้วย ผู้ผลิต ผู้ขับรถยนต์ทั้งเจ้าของรถและไม่ใช่เจ้าของรถ สำหรับผู้ผลิตจะต้องรับผิดชอบต่อ Pollution ในการสั่งผลิตของโรงงาน แต่เมื่อรถยนต์คันใหม่ถูกซื้อโดยผู้ใช้งาน จะถือการครอบครองของผู้จ่ายเงินซื้อรถยนต์คันนั้นมาใช้งาน นั่นคือ ซื้อเทคโนโลยีและซื้อเครื่องที่ใช้เชื้อเพลิงนั้นมาเป็นของเรา ซึ่งเจ้าของรถควรรับผิดชอบ Pollution ที่เกิดจากการปล่อยด้วย อย่างไรก็ตาม ประเด็นนี้มีช่องโหว่ คือ ทำไมไม่เป็น Consumer Pays Principle เช่น ผู้โดยสารเลือกที่จะไปรถแบบใดก็ได้ รถเมล์ รถตู้(ดีเซล/NGV) รถแท๊กซี่(Gasoline/NGV) และยังเป็นผู้ตัดสินใจเลือกคือสั่งการเองด้วย แท้จริงแล้วมีความรับผิดชอบร่วมกัน แต่อย่างไรก็ตาม สัดส่วนที่เหมาะสมต่อการแบ่งความรับผิดชอบนี่สิ ที่ยังหาหลักการไม่ได้ อีกอย่างการประกาศใช้หลักการนี้เริ่มจากประเทศพัฒนาแล้ว ดังนั้นแนวคิดที่จะไปยัง Consumer ย่อมห่างไกลและไม่แสดงความเป็นประเทศผู้นำ อีกทั้งเรื่องแบบนี้ถ้าวางความรับผิดชอบไว้กับผู้ที่มีศักยภาพน้อยทั้งเงินลงทุน เทคโนโลยี องค์ความรู้สะสม ย่อมทำให้ระบบในเชิงปฏิบัติเกิดได้ยาก แถมอาจเกิดการต่อต้านระดับประเทศขึ้นอีก
เป็นที่รู้กันโดยทั่วไปว่า เชื้อเพลิงที่ปล่อยก๊าซคาร์บอนไดออกไซด์เทียบเท่า (CO2eq) มีอัตราการปล่อยต่อหน่วย ตามประกาศขององค์การบริหารจัดการก๊าซเรือนกระจก ดังนี้

เมื่อคำนวณตามอัตราการใช้งานรถแบบปกติในเมืองเปรียบเทียบกับอัตราภาษีขั้นต่ำของรถแต่ละแบบตามการบังคับใช้ แสดงดังภาพ
 เปรียบเทียบปริมาณการปล่อยก๊าซคาร์บอนไดออกไซด์(เทียบเท่า) ต่อกิโลเมตร กับ อัตราการเก็บภาษีสรรพสามิตรถยนต์ใหม่
เปรียบเทียบปริมาณการปล่อยก๊าซคาร์บอนไดออกไซด์(เทียบเท่า) ต่อกิโลเมตร กับ อัตราการเก็บภาษีสรรพสามิตรถยนต์ใหม่
จากการเปรียบเทียบเห็นทิศทางที่สวนทางกันซึ่งถ้าไม่ได้รับคำอธิบาย ประชาชนอาจเข้าใจไปได้ว่า อัตราการเก็บภาษีมากไปน้อยเรียงจากเชื้อเพลิงสกปรกมากกว่าและลดหลั่นกันไปตามการเก็บฯ
ทิศทางการบังคับใช้ภาษีรถยนต์
หมายเหตุ: ก๊าซคาร์บอนไดออกไซด์ ในพระราชบัญญัติส่งเสริมและรักษาคุณภาพสิ่งแวดล้อมแห่งชาติ พ.ศ. 2535 ยังไม่มีการระบุว่าเป็นมลพิษ จึงใช้คำว่า Pollution แทน
The post ภาษีสรรพสามิตช่วยลดก๊าซคาร์บอนไดออกไซด์จริงหรือ appeared first on EnergyThai.
Fonts-TLWG OTF and WOFF in Debian
ดังที่ได้กล่าวไว้ในท้าย blog ที่แล้ว ว่าผมได้ตัดสินใจที่จะผลักดันการใช้ฟอนต์รูปแบบอื่นนอกจาก TTF ใน Debian ซึ่งล่าสุดก็ได้เตรียมแพกเกจรุ่น 1:0.6.2-2 และได้ ผ่าน NEW queue เข้าสู่ sid แล้ว เมื่อคืนนี้ ก็ขอบันทึกแนวคิดเบื้องหลังไว้สักหน่อย
โครงการ Fonts-TLWG ได้รวบรวมฟอนต์ต่าง ๆ ที่เจ้าของอนุญาตให้เผยแพร่แบบโอเพนซอร์สได้ เพื่อนำมาพัฒนาต่อให้เข้ากับความต้องการและเทคโนโลยีใหม่ ๆ โดยต้นฉบับก็มักจะมาในรูป TrueType (TTF) ซึ่งใช้เส้นโค้ง quadratic Bézier แต่เมื่อ import เข้าสู่โครงการจะถูกแปลงเป็น cubic Bézier ทั้งหมด ด้วยเหตุผลคือ:
- การใช้งานกับ LaTeX ซึ่งเน้นการรองรับ e-TeX และ pdfTeX engine นั้น การใช้ฟอนต์ Postscript (ซึ่งใช้เส้นโค้ง cubic Bézier) จะจัดการได้ง่ายกว่า
- เส้นโค้ง cubic Bézier สามารถปรับแก้ไขได้ง่ายกว่า quadratic Bézier (เคยอธิบายไว้ใน blog เก่า)
การใช้ cubic Bézier ทำให้เราสามารถปรับแต่งฟอนต์ได้เต็มที่ โดยที่ยังสามารถ generate ฟอนต์เป็น TrueType ได้เหมือนเดิม โดยใช้สคริปต์แปลงโค้ง cubic เป็น quadratic พร้อมกับ apply auto instruction ด้วย ซึ่งวิธีนี้ก็มีข้อดีข้อเสียเมื่อเทียบกับการทำงานกับ TrueType โดยตรง คือ
ข้อดี:
- โค้ง cubic ปรับแก้ได้สะดวกกว่ามาก
- generate ฟอนต์ได้ทั้งฟอร์แมตที่ใช้ cubic และ quadratic Bézier โดยไม่เกิดจุดต่อโค้งส่วนเกินที่เกินความจำเป็น อันจะทำให้ข้อมูลฟอนต์มีขนาดใหญ่ขึ้น (โดยปกติ โค้ง quadratic จะต้องใช้จุดควบคุมมากกว่าโค้ง cubic ในการแทนเส้นโค้งเดียวกัน และเมื่อแปลงโค้ง quadratic เป็น cubic ก็จะเกิดจุดต่อโค้งระหว่างกลางเพิ่มขึ้นอีก ทำให้ข้อมูลของโค้ง cubic เกิดการขยายตัวเกินความจำเป็นถึง 2 ชั้น ในขณะที่การใช้โค้ง cubic เป็นต้นทาง จะได้ข้อมูลของโค้ง cubic ขนาดเล็ก และจะเกิดการขยายตัวของข้อมูลเพียงชั้นเดียวขณะแปลงเป็น quadratic)
- ทำ hinting ได้ง่าย เนื่องจากฟอนต์ Postscript อาศัย global hint ควบคุมเส้นอักษรเป็นหลัก (ดู blog เก่า เกี่ยวกับ blue zones และ stem hints) ในขณะที่ TrueType ใช้ instruction ควบคุมจุดต่าง ๆ ซึ่งแทบจะไม่ต่างอะไรกับภาษาแอสเซมบลี
ข้อเสีย:
- การแปลงโค้ง cubic เป็น quadratic จะต้องเกิดการ interpolate จุดเพิ่มเติม เนื่องจากโค้ง quadratic มีความสามารถในการบรรยายโค้งต่ำกว่า ต้องใช้จุดมากกว่า ในขณะที่การแปลงจาก quadratic เป็น cubic จะได้จุดแบบแม่นตรง (ไม่ใช่ interpolate) และเนื่องจากการ interpolate เป็นไปแบบอัตโนมัติ จึงไม่อาจควบคุมจำนวนจุดที่ interpolate ได้เต็มที่นัก
- คุณภาพของ TrueType instruction ที่สร้างแบบอัตโนมัติอาจไม่สูงนักเมื่อเทียบกับการเขียน instruction ด้วยมือ
เมื่อเทียบข้อดี-ข้อเสียแล้ว ผมยังคงเลือกเอาโค้งแบบ cubic แม้ข้อเสียจะเกิดกับฟอนต์ TrueType ที่มีผู้ใช้มากที่สุด เพราะข้อเสียต่าง ๆ ถือว่ายอมรับได้ ความคลาดเคลื่อนจากการ interpolate ขณะแปลงเส้นโค้งไม่ได้มีนัยสำคัญอะไร ส่วนเรื่องคุณภาพของ TrueType instruction นั้น เราก็ทำอะไรไม่ได้มาก เนื่องจากเป็นเรื่องที่ถ้าจะทำจริงจะต้องอาศัยแรงงานมหาศาล โดยที่ไม่ได้ช่วยเพิ่มคุณภาพให้กับฟอนต์ที่ใช้ cubic Bézier แต่อย่างใด (ในขณะที่การปรับแต่ง hint ของ Postscript สามารถช่วยเพิ่มคุณภาพของ TrueType instruction ที่สร้างแบบอัตโนมัติได้บ้าง)
กล่าวโดยสรุป โค้ง cubic Bézier คือโค้งที่เป็น native ที่ใช้ในการพัฒนา ถ้าสามารถใช้โค้งนี้ได้โดยตรงก็ย่อมควบคุมอะไรต่าง ๆ ได้ดีกว่า อย่างน้อยก็ในทางทฤษฎี
ที่ผ่านมา การใช้งานฟอนต์ที่ดูจะเหมาะสมในทางปฏิบัติก็คือ
- เดสก์ท็อป ใช้ TrueType (quadratic Bézier)
- LaTeX ใช้ Type 1 (cubic Bézier)
ที่ผมยังไม่กล้าผลักดันการใช้ฟอนต์ที่ใช้โค้ง cubic บนเดสก์ท็อปในช่วงที่ผ่านมา ก็เนื่องจากรูปแบบการ hint ของ Postscript นั้น อิงอาศัยความฉลาดของ rasterizer ในการใช้ hint ในฟอนต์มาปรับเส้นโค้งต่าง ๆ (ไม่เหมือนกับ TrueType instruction ที่มีคำสั่งครบสำหรับ rasterizer ไม่ว่าใช้ rasterizer ตัวไหนก็ได้คุณภาพใกล้เคียงกัน) ซึ่งในช่วงแรกนั้น Postscript rasterizer ที่มากับ FreeType วาดตัวอักษรได้ดีเฉพาะบางขนาดเท่านั้น แต่พอใช้กับขนาดอื่น เส้นนอนจะเริ่มหนาและเบลอ (เสียดายที่ไม่ได้จับภาพไว้เป็นเรื่องเป็นราว) จนเมื่อ Adobe contribute CFF rasterizer ให้กับ FreeType คุณภาพที่ได้ก็ดีขึ้นอย่างเห็นได้ชัด ซึ่งเริ่มเปิดใช้จริงใน FreeType 2.5.0.1
ในรอบ Debian Jessie นั้น ผมถึงกับเปลี่ยนฟอร์แมตฟอนต์จาก TTF เป็น OTF ในรุ่น 1:0.6.0-2 ซึ่งทำให้ได้ฟอนต์ที่กินเนื้อที่น้อยลงแทบจะครึ่งต่อครึ่งโดยที่คุณภาพก็ไม่ได้ด้อยกว่า TTF เลย แต่ก็ต้องชะงักเมื่อเจอ Debian #730742 ที่มีผู้ร้องเรียนว่า rasterizer ตัวใหม่ทำให้ฟอนต์ Cantarell ไม่สวย ทำให้ผู้ดูแลแพกเกจ FreeType ของ Debian ต้อง disable CFF rasterizer ของ Adobe แล้วกลับไปใช้ rasterizer ตัวเก่า ผมจึงต้องถอยกลับมาใช้ TTF ในรุ่น 1:0.6.1-2
จนกระทั่งเข้าสู่รอบพัฒนา Stretch ฟอนต์ Cantarell ได้รับการแก้ปัญหาแล้ว จึงได้มีผู้ร้องขอเปิดใช้ CFF rasterizer ของ Adobe อีกครั้ง (Debian #795653) และมีผลตั้งแต่รุ่น 2.6-1 หลังจากรอดูอยู่พักหนึ่งจนแน่ใจว่าเขาไม่ disable กลับอีก ผมจึงตั้งใจไว้ว่าจะเริ่มผลักดันฟอนต์ OTF อีกครั้ง แต่ครั้งนี้ตัดสินใจเลือกการเปลี่ยนแปลงที่ใหญ่กว่านั้น ด้วยการ build ทั้ง TTF และ OTF ให้ผู้ใช้เลือกติดตั้งตามชอบ โดยมีโครงสร้างดังนี้:
- fonts-thai-tlwg (metapackage)
- fonts-tlwg-kinnari (dependency package + fontconfig stuffs)
- fonts-tlwg-kinnari-ttf (TTF files), OR
- fonts-tlwg-kinnari-otf (OTF files)
- fonts-tlwg-garuda (dependency package + fontconfig stuffs)
- fonts-tlwg-garuda-ttf (TTF files), OR
- fonts-tlwg-garuda-otf (OTF files)
- ...
- fonts-tlwg-kinnari (dependency package + fontconfig stuffs)
- fonts-thai-tlwg-ttf (metapackage สำหรับติดตั้ง fonts-tlwg-*-ttf ทั้งหมด)
- fonts-thai-tlwg-otf (metapackage สำหรับติดตั้ง fonts-tlwg-*-otf ทั้งหมด)
คราวนี้ถ้าจะ disable rasterizer ของ Adobe อีก ผู้ใช้ก็สามารถเปลี่ยนกลับไปใช้ TTF ได้ทันที โหะ ๆ
พร้อมกันนี้ ก็ได้เพิ่มแพกเกจ fonts-thai-tlwg-web สำหรับติดตั้ง web font ในรูปแบบ WOFF สำหรับเซิร์ฟเวอร์ที่ต้องการใช้ web font ในเว็บไซต์ต่าง ๆ ด้วย
หากคุณใช้ Debian Sid ก็ติดตั้งได้เลยตั้งแต่วันนี้ หากคุณใช้ Debian testing ก็รออีกสักพัก
Fonts-TLWG 0.6.2
Fonts-TLWG 0.6.2 ได้ออกไปแล้ว หลังจากใช้เวลาพัฒนาจากรุ่น 0.6.1 อยู่เกือบปีครึ่ง ความเปลี่ยนแปลงหลัก ๆ ของรุ่นนี้คือการรองรับการเขียนภาษามลายูปาตานีด้วยอักษรไทยในฟอนต์ต่าง ๆ แต่ก็มีรายการอื่น ๆ อีกพอประมาณ
สรุปการเปลี่ยนแปลงในรุ่นนี้คือ
- เพิ่ม Preferred Family/Subfamily (Name ID 16, 17) ในทุกฟอนต์ เพื่อให้ Windows สามารถรองรับ style ได้มากกว่า 4 style ซึ่งจำเป็นสำหรับฟอนต์ Kinnari และ Norasi ซึ่งมีทั้ง Oblique และ Italic และฟอนต์ Umpush ที่มี Light เพิ่มเติมด้วย (ตามคำแนะนำของคุณ Martin Hosken) นอกจากนี้ บางโปรแกรมบนลินุกซ์อย่าง GNOME Software ยังใช้ข้อมูลนี้ในการจัดกลุ่มแพกเกจฟอนต์ให้เป็นกลุ่มเดียวกันด้วย (ตาม รายงานของคุณ Richard Hughes สำหรับฟอนต์ Arundina)
- กำหนด weight ของฟอนต์น้ำหนักปกติเป็น Regular จากเดิมที่เป็น Regular บ้าง Medium บ้าง Book บ้าง เพื่อให้เป็นไปตามข้อกำหนดของ Name ID 2 เหมือนกันทั้งหมด
- validate ทุกฟอนต์ พร้อมแก้ปัญหาที่ตรวจพบ ตัวอย่างของปัญหาที่พบก็เช่น จุดต่อโค้งมีความชันเกือบอยู่ในแนวดิ่งหรือราบแต่ไม่ดิ่งหรือราบพอดี (ก็แก้ให้ดิ่งหรือราบพอดี), จุดมีพิกัดไม่เป็นจำนวนเต็ม (ก็ปัดเศษให้เป็นจำนวนเต็ม), Blue zone แคบหรือกว้างเกินไป ฯลฯ
- เซ็ต OS/2 Version เป็น 4 ทุกฟอนต์ เดิมนั้นกำหนดเป็นค่า Auto ซึ่ง Fontforge จะให้ค่าเป็น Version 1 ตาราง OS/2 & Windows Metrics เป็นตาราง metrics ของฟอนต์ TrueType ซึ่งไมโครซอฟท์ได้พัฒนาเพิ่มจาก spec ของ Apple เพื่อใช้กับ OS/2 และ Windows (อ่านรายละเอียดเพิ่มเติม) ซึ่งมีการปรับปรุงมาเรื่อย ๆ โดยรุ่นล่าสุดคือ version 5 แต่รุ่นที่ Fontforge รองรับสูงสุดคือ version 4 จึงกำหนดเลขรุ่นเพื่อให้ฟอนต์มีข้อมูลตาม spec รุ่นใหม่ ๆ ตามคำแนะนำของคุณ Martin Hosken
- รองรับการเขียนภาษามลายูปาตานีด้วยอักษรไทย ดังที่เคย บันทึกรายละเอียดไว้ ซึ่งงานส่วนนี้ถือว่ากินเวลาพัฒนานานที่สุด
- รองรับการสร้าง web font แบบ WOFF ใน configure script เพิ่มเติมจาก Type 1, TTF, OTF
- เพิ่มบริการ on-line web font เพื่อให้เว็บต่าง ๆ สามารถใช้ฟอนต์ชุด TLWG ในเว็บของตนเองได้ โดยได้เตรียม CSS stylesheet ไว้ ดังรายละเอียดในหน้า TLWG Web Fonts
เนื่องจากรุ่นนี้ไม่ได้มีความเปลี่ยนแปลงในส่วนของ LaTeX มากนัก จึงไม่อัปเดตรุ่นใน CTAN
รุ่นนี้ผมตัดสินใจเริ่มผลักดันการใช้ฟอนต์รูปแบบต่าง ๆ จึงได้เตรียม generated fonts ในรูป OTF และ WOFF เพิ่มเติมจากแบบ TTF ที่เคยทำตามปกติ และมีแผนที่จะเพิ่มรูปแบบ OTF (หรืออาจจะ WOFF ด้วย) ใน Debian ให้ผู้ใช้ได้เลือกใช้ด้วยเร็ว ๆ นี้ หลังจากที่ libfreetype6 ใน Debian ได้ enable CFF rasterizer ของ Adobe ใน FreeType อีกครั้งใน Stretch มาระยะหนึ่งแล้ว (Debian #795653) ซึ่งทำให้คุณภาพการ render ฟอนต์ OTF ดีขึ้นมาก (rasterizer ตัวนี้ควรจะได้ใช้กันตั้งแต่รุ่น Jessie แต่เพราะผู้ใช้บางส่วนไม่ชอบ จึงถูก disable ไป [Debian #730742] จนกระทั่งเริ่มรอบพัฒนา Stretch จึง enable ใหม่อีกครั้ง)
COP21 – การประชุมรัฐภาคีว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศใกล้สรุป
 source: http://www.bbc.com
source: http://www.bbc.com
(www.bcc.com DEC 12, 2015)…French Foreign Minister Laurent Fabius, who is chairing the summit.
Mr Fabius told reporters in Paris that he would present a new version of the draft text on Saturday morning at 0800 GMT, which he was “sure” would be approved and “a big step forward for humanity as a whole”.
“We are almost at the end of the road and I am optimistic,” he added
ที่มาการประชุมสมัชชาประเทศภาคีอนุสัญญาสหประชาชาติว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศ (Conference of Parties: COP) ช่วงเช้าของวันเสาร์ที่ 12 ธันวาคม 2558 นี้จะมีแถลงการณ์อย่างเป็นทางการของข้อสรุปที่ได้รับการยินยอมจากทั้ง 195 ประเทศ (ไม่รวมเกาหลีเหนือ ซีเรีย และอีก 8 ประเทศ)
ย้อนดูเป้าหมายของการประชุมนี้ที่มีมายาวนานเกือบ 20 ปี เริ่มจากประเทศพัฒนาแล้ว และด้วยเหตุผลที่ประเทศกำลังพัฒนาต้องช่วยกันเพราะมีสัดส่วนการปล่อยก๊าซเรือนกระจกสูงจนอาจทำให้ไม่สามารถควบคุมอุณหภูมิโลกภายใต้ 2 องศาเซลเซียส ในปี ค.ศ.2100 ได้นั้น
ประเทศกำลังพัฒนาได้รับการรายงานค่าทางสถิติการปล่อยก๊าซเรือนกระจกที่แซงประเทศสหรัฐอเมริกากลายเป็นอันดับ 1 คือ ประเทศจีน ในช่วง 2-3 เดือนก่อนการประชุมมีข่าวความร่วมมือของประเทศจีน สหรัฐ ออกมาอย่างต่อเนื่อง ซึ่งอาจเป็นความร่วมมือในเรื่องนี้โดยเฉพาะ
การขยับตัวของประเทศไทยก่อนหน้าการประชุมที่กรุงปารีสครั้งนี้ มีความถี่และการอัพเดทอย่างสูงในการออกสื่อเรื่องการรายงานเป้าหมาย ปีเป้าหมาย การลดก๊าซเรือนกระจก ของแต่ละประเทศ ไปยัง UN เพื่อให้ผู้นำแต่ละประเทศต้องตื่นตัวในการแสดงความรับผิดชอบ และประเทศไทยก็เช่นเดียวกัน มติ ครม.สรุปเป้าหมายการลดก๊าซเรือนกระจกตามแผน INDCs (Intended Nationally Determined Contributions) 20-25% ในปี 2030 ประกอบกับผู้แทนกระทรวงต่างประเทศที่มีการคอมเม้นต์เข้มทุกครั้งในการประชุมเตรียมงานในเรื่องการตั้งค่าเป้าหมายฯ อาจเป็นเพราะช่วงนี้ประเทศไทยมีประเด็นอยู่หลายเรื่องให้จัดการ เช่น การค้ามนุษย์ชาวโรฮิงญา, ICAO กับกรมการบินพลเรือน เป็นต้น
การประชุม COP21ปี 2015 การประชุมที่กรุงปารีสครั้งนี้จึงมีความเข้มข้นตลอดระยะเวลาเกือบ 2 ปี และมีเป้าหมายการประชุมที่สำคัญ คือ
- Differentiation ความแตกต่างของระดับการพัฒนา และฐานะการเงินของแต่ละประเทศ เป็นความยากที่สุดของการประชุมเจรจาเพื่อให้ได้มติที่ประชุมฉบับทางการออกมา โดยสิ่งที่ท้าทายคนทั้งโลกคือเศรษฐกิจโลกจากทิศทางการประชุมด้วย
Overall Target เป้าหมายประธานของประเทศฝรั่งเศสในการตั้งค่าเป้าหมายสูงสุดที่ 2 oC (Ambitious Target) แต่เห็นด้วยที่ทุกประเทศจะตั้งเป้าหมายในความพยายามสูงสุดที่จะรักษาอุณหภูมิโลกที่ 1.5 oC จึงเป็นหน้าที่ผู้แทนประเทศต้องลดถ้อยคำในแถลงการณ์ฉบับทางการในการบังคับต่อประเทศตัวเอง ซึ่งอุณหภูมิโลกสูขึ้นราว 1 oC จากยุคก่อนการปฏิวัติอุตสาหกรรม
Climate Finance การสนับสนุนทางการเงินจากประเทศพัฒนาแล้ว สู่ประเทศกำลังพัฒนาที่ได้รับผลกระทบ ดังเช่น ประเทศจีน และอินเดีย ที่แถลงไม่เห็นด้วยกับทั้งหมดของข้อสรุปช่วงโค้งสุดท้ายของการประชุมนี้
Transparency ความโปร่งใสในขั้นตอนของ MRV ที่ประเทศสหรัฐอเมริกามีระบบเดียวที่ทำทุกกระบวนการได้อย่างโปร่งใสตรวจสอบได้ เป็นสิ่งซึ่งประเทศจีนและอินเดียยังไม่มีการตกลงในระบบเดียวกันนี้
 งานของผู้แทนการประชุมจากทุกประเทศ ต้องปรับข้อความให้เหมาะสมกับประเทศตัวเองมากที่สุด และประชุมต่อรอง (Source: http://www.bbc.com/news/science-environment-35079532 )
งานของผู้แทนการประชุมจากทุกประเทศ ต้องปรับข้อความให้เหมาะสมกับประเทศตัวเองมากที่สุด และประชุมต่อรอง (Source: http://www.bbc.com/news/science-environment-35079532 )
 ช่วงสุดท้ายของการส่งฉบับแก้ไขก่อนเป็นแถลงการณ์ฉบับทางการ
ช่วงสุดท้ายของการส่งฉบับแก้ไขก่อนเป็นแถลงการณ์ฉบับทางการ
ติดตามการถ่ายทอดสดที่ http://unfccc6.meta-fusion.com/cop21/channels/plenary-1
The post COP21 – การประชุมรัฐภาคีว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศใกล้สรุป appeared first on EnergyThai.
COP21 – การประชุมรัฐภาคีว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศใกล้สรุป
 source: http://www.bbc.com
source: http://www.bbc.com
(www.bcc.com DEC 12, 2015)…French Foreign Minister Laurent Fabius, who is chairing the summit.
Mr Fabius told reporters in Paris that he would present a new version of the draft text on Saturday morning at 0800 GMT, which he was “sure” would be approved and “a big step forward for humanity as a whole”.
“We are almost at the end of the road and I am optimistic,” he added
ที่มาการประชุมสมัชชาประเทศภาคีอนุสัญญาสหประชาชาติว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศ (Conference of Parties: COP) ช่วงเช้าของวันเสาร์ที่ 12 ธันวาคม 2558 นี้จะมีแถลงการณ์อย่างเป็นทางการของข้อสรุปที่ได้รับการยินยอมจากทั้ง 195 ประเทศ (ไม่รวมเกาหลีเหนือ ซีเรีย และอีก 8 ประเทศ)
ย้อนดูเป้าหมายของการประชุมนี้ที่มีมายาวนานเกือบ 20 ปี เริ่มจากประเทศพัฒนาแล้ว และด้วยเหตุผลที่ประเทศกำลังพัฒนาต้องช่วยกันเพราะมีสัดส่วนการปล่อยก๊าซเรือนกระจกสูงจนอาจทำให้ไม่สามารถควบคุมอุณหภูมิโลกภายใต้ 2 องศาเซลเซียส ในปี ค.ศ.2100 ได้นั้น
ประเทศกำลังพัฒนาได้รับการรายงานค่าทางสถิติการปล่อยก๊าซเรือนกระจกที่แซงประเทศสหรัฐอเมริกากลายเป็นอันดับ 1 คือ ประเทศจีน ในช่วง 2-3 เดือนก่อนการประชุมมีข่าวความร่วมมือของประเทศจีน สหรัฐ ออกมาอย่างต่อเนื่อง ซึ่งอาจเป็นความร่วมมือในเรื่องนี้โดยเฉพาะ
การขยับตัวของประเทศไทยก่อนหน้าการประชุมที่กรุงปารีสครั้งนี้ มีความถี่และการอัพเดทอย่างสูงในการออกสื่อเรื่องการรายงานเป้าหมาย ปีเป้าหมาย การลดก๊าซเรือนกระจก ของแต่ละประเทศ ไปยัง UN เพื่อให้ผู้นำแต่ละประเทศต้องตื่นตัวในการแสดงความรับผิดชอบ และประเทศไทยก็เช่นเดียวกัน มติ ครม.สรุปเป้าหมายการลดก๊าซเรือนกระจกตามแผน INDCs (Intended Nationally Determined Contributions) 20-25% ในปี 2030 ประกอบกับผู้แทนกระทรวงต่างประเทศที่มีการคอมเม้นต์เข้มทุกครั้งในการประชุมเตรียมงานในเรื่องการตั้งค่าเป้าหมายฯ อาจเป็นเพราะช่วงนี้ประเทศไทยมีประเด็นอยู่หลายเรื่องให้จัดการ เช่น การค้ามนุษย์ชาวโรฮิงญา, ICAO กับกรมการบินพลเรือน เป็นต้น
การประชุม COP21ปี 2015 การประชุมที่กรุงปารีสครั้งนี้จึงมีความเข้มข้นตลอดระยะเวลาเกือบ 2 ปี และมีเป้าหมายการประชุมที่สำคัญ คือ
- Differentiation ความแตกต่างของระดับการพัฒนา และฐานะการเงินของแต่ละประเทศ เป็นความยากที่สุดของการประชุมเจรจาเพื่อให้ได้มติที่ประชุมฉบับทางการออกมา โดยสิ่งที่ท้าทายคนทั้งโลกคือเศรษฐกิจโลกจากทิศทางการประชุมด้วย
Overall Target เป้าหมายประธานของประเทศฝรั่งเศสในการตั้งค่าเป้าหมายสูงสุดที่ 2 oC (Ambitious Target) แต่เห็นด้วยที่ทุกประเทศจะตั้งเป้าหมายในความพยายามสูงสุดที่จะรักษาอุณหภูมิโลกที่ 1.5 oC จึงเป็นหน้าที่ผู้แทนประเทศต้องลดถ้อยคำในแถลงการณ์ฉบับทางการในการบังคับต่อประเทศตัวเอง ซึ่งอุณหภูมิโลกสูขึ้นราว 1 oC จากยุคก่อนการปฏิวัติอุตสาหกรรม
Climate Finance การสนับสนุนทางการเงินจากประเทศพัฒนาแล้ว สู่ประเทศกำลังพัฒนาที่ได้รับผลกระทบ ดังเช่น ประเทศจีน และอินเดีย ที่แถลงไม่เห็นด้วยกับทั้งหมดของข้อสรุปช่วงโค้งสุดท้ายของการประชุมนี้
Transparency ความโปร่งใสในขั้นตอนของ MRV ที่ประเทศสหรัฐอเมริกามีระบบเดียวที่ทำทุกกระบวนการได้อย่างโปร่งใสตรวจสอบได้ เป็นสิ่งซึ่งประเทศจีนและอินเดียยังไม่มีการตกลงในระบบเดียวกันนี้
 งานของผู้แทนการประชุมจากทุกประเทศ ต้องปรับข้อความให้เหมาะสมกับประเทศตัวเองมากที่สุด และประชุมต่อรอง (Source: http://www.bbc.com/news/science-environment-35079532 )
งานของผู้แทนการประชุมจากทุกประเทศ ต้องปรับข้อความให้เหมาะสมกับประเทศตัวเองมากที่สุด และประชุมต่อรอง (Source: http://www.bbc.com/news/science-environment-35079532 )
 ช่วงสุดท้ายของการส่งฉบับแก้ไขก่อนเป็นแถลงการณ์ฉบับทางการ
ช่วงสุดท้ายของการส่งฉบับแก้ไขก่อนเป็นแถลงการณ์ฉบับทางการ
ติดตามการถ่ายทอดสดที่ http://unfccc6.meta-fusion.com/cop21/channels/plenary-1
The post COP21 – การประชุมรัฐภาคีว่าด้วยการเปลี่ยนแปลงสภาพภูมิอากาศใกล้สรุป appeared first on EnergyThai.
ประเมินประสิทธิภาพพลังงานของโครงการโรงไฟฟ้า
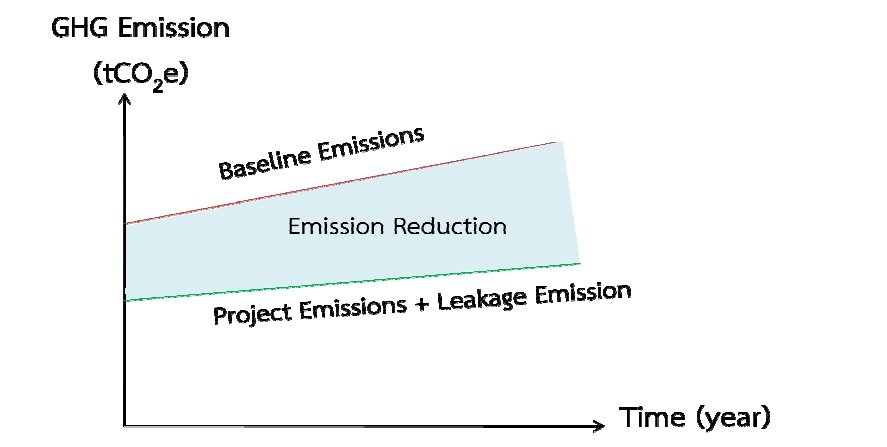
ต่อจาก Blog ที่แล้วได้แบ่งนิยามการปรับปรุงอุปกรณ์ของโรงไฟฟ้าไว้เป็น 3 ระดับ ใน Blog วันนี้เพิ่มเติมการสร้างและเปลี่ยนโรงไฟฟ้าใหม่ และต่อยอดจากการปรับปรุงที่ประโยชน์นอกจากการช่วยเพิ่มศักยภาพการผลิตให้สูงขึ้น ลดต้นทุนเชื้อเพลิง แล้วยังช่วยลดก๊าซเรือนกระจกตอบสนองเป้าหมายรักษ์โลกอีกด้วย
ในฐานะประเทศที่ซื้อเทคโนโลยีมาใช้ดังประเทศไทย การสร้างโรงงานใหม่ย่อมต้องอาศัยการติดตามเทคโนโลยีของผู้ผลิต (OEM: Original Equipment Manufacturer) ซึ่งมีการ Trigger ผู้ใช้ (Technology User) ตามเวลาที่เหมาะสมอย่าง Dynamic ในบางครั้งไม่ใช่เลือกกันได้ง่ายๆ ตามพื้นฐานเดิมๆ ที่ใช้งานกันในประเทศ แต่เทคโนโลยีมีการเปลี่ยนแปลงอย่างก้าวกระโดด หรือเปลี่ยนรูปแบบการให้ความร้อน (Heat) ยกตัวอย่างเช่น การเผาไหม้เชื้อเพลิงเพื่อให้ความร้อนกับ Working Fluid ในกระบวนการผลิต เปลี่ยนเป็น การให้ความร้อนจากพลังงานนิวเคลียร์โดยปฏิกริยา Fission กันไปเลย ดังนั้น ต้องมีการอัพเดทประสิทธิภาพของแต่ละเทคโนโลยีอย่างสม่ำเสมอ
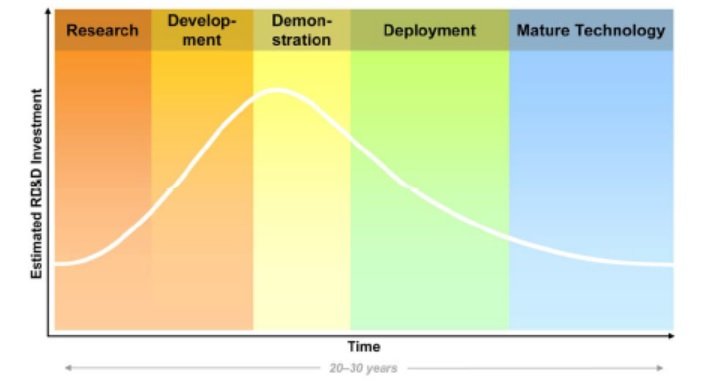
แนวโน้มปัจจุบัน พบว่า ศาสตร์ที่มี Impact สูงต่อการเปลี่ยนเทคโนโลยีของการผลิตไฟฟ้ามาก คือ เคมี และ โลหการ เนื่องจาก โดยคอนเซ็ปต์คิดไปจนทะลุแล้ว จึงอยู่ในช่วงการทำให้ใช้งานจริงได้ (Mature Technology) ซึ่งเป็นยุคที่มีเป้าหมายเพื่อรักษาสิ่งแวดล้อม และมีความพยายามอย่างสูงสุดในการลดข้อจำกัดด้านวัสดุให้ทนต่อสภาพความดันและอุณหภูมิสูงได้ แสดงขั้นของการพัฒนาดังรูปที่ 1
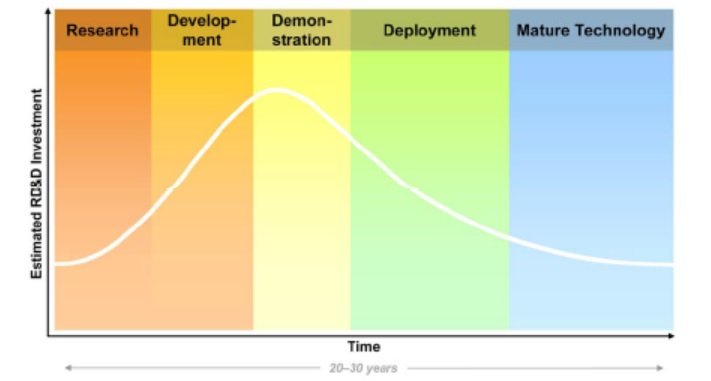 รูปที่ 1 กรอบเวลาและขั้นตอนของเทคโนโลยีด้านการผลิตไฟฟ้าอ้างอิงจากการประเมินและรวบรวมโดย Electric Power Research Institute อ่านเเพิ่มเติมที่ www.epri.com
รูปที่ 1 กรอบเวลาและขั้นตอนของเทคโนโลยีด้านการผลิตไฟฟ้าอ้างอิงจากการประเมินและรวบรวมโดย Electric Power Research Institute อ่านเเพิ่มเติมที่ www.epri.com
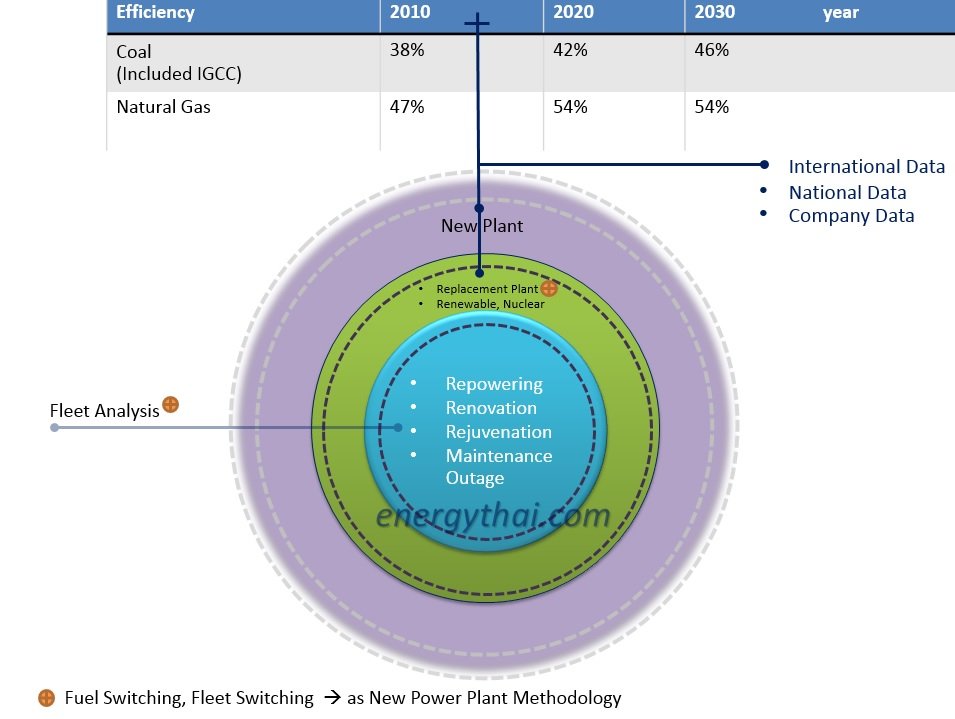
ภาพด้านล่างนี้แสดงในลักษณะของ Bubble Chart ของกิจกรรมที่เกิดขึ้นเพื่อการเพิ่มกำลังการผลิต และเพิ่มประสิทธิภาพการใช้เชื้อเพลิง กำหนดให้ขนาดของ Bubble Chart แสดงถึงปริมาณเชื้อเพลิงที่ใช้ในระดับปกติ (Baseline) และเมื่อมีการทำโครงการต่างๆ ขนาดของ Bubble เส้นประแสดงถึงปริมาณการใช้เชื้อเพลิงที่ลดลงจากระดับปกติ (Project) ซึ่งปัจจุบันปี ค.ศ. 2015 อยุู่ในช่วงที่ประสิทธิภาพการผลิตจากถ่านหินและก๊าซธรรมชาติที่ 38% และ 47% ตามลำดับ
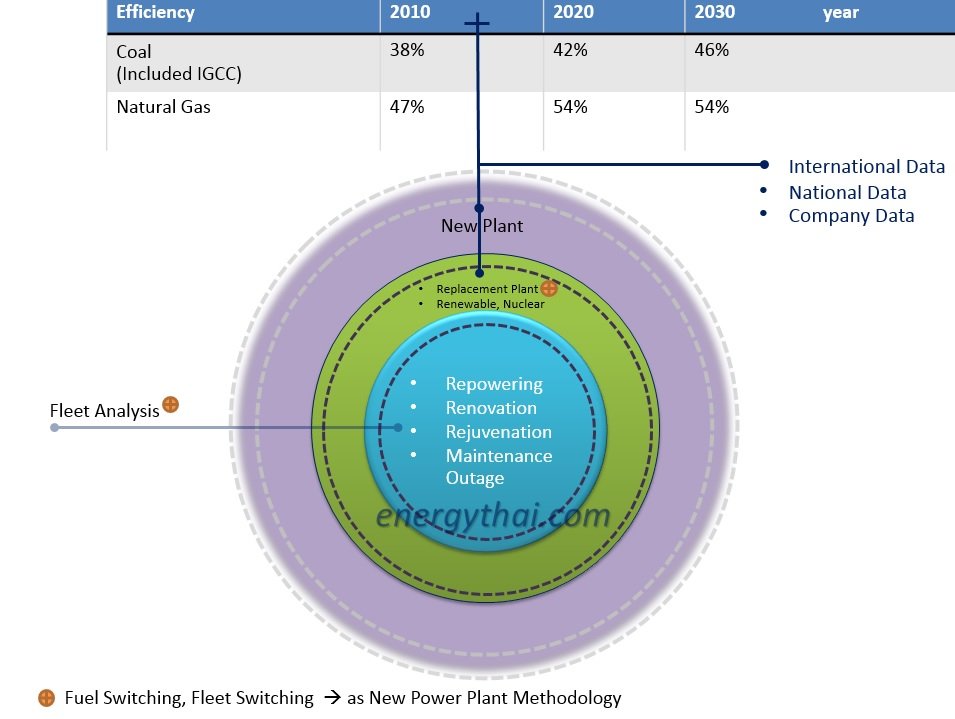 รูปที่ 2 Project Greenhouse Gas Reduction
รูปที่ 2 Project Greenhouse Gas Reduction
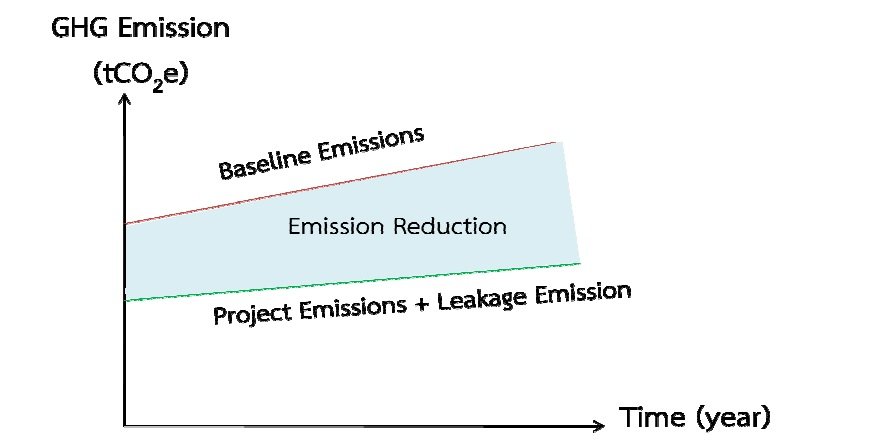 รูปที่ 3 การลดก๊าซเรือนกระจกของกรณีฐานและกรณีดำเนินโครงการ
รูปที่ 3 การลดก๊าซเรือนกระจกของกรณีฐานและกรณีดำเนินโครงการ
อ้างอิง องค์การบริหารจัดการก๊าซเรือนกระจก
เป็นเช่นเดียวกับการปล่อยก๊าซเรือนกระจก หรือ CO2e (ก๊าซคาร์บอนไดออกไซด์เทียบเท่า) ซึ่งเมื่อการใช้เชื้อเพลิงลดลง การปล่อย CO2e ย่อมลดลงเช่นเดียวกัน ตามรูปที่ 3 ซึ่งเป็นวิธีการคำนวณก๊าซเรือนกระจกที่ประกาศใช้โดย องค์การบริหารจัดการก๊าซเรือนกระจก
โดยสรุปคอนเซ็ปต์การประเมินประสิทธิภาพพลังงานของ โครงการ หรือ กิจกรรมใดใด ในโรงไฟฟ้า โรงงานอุตสาหกรรม จำเป็นต้องจัดลำดับความสำคัญของแนวคิดให้ถูกต้อง โดยมีจุดเริ่มต้นจาก ประเมินปริมาณการใช้พลังงานภาพรวมของแต่ละระดับก่อน (Baseline) ถัดมาเมื่อมีการดำเนินโครงการแล้วจึงได้ปริมาณการใช้พลังงานซึ่งอาจลดลงหรือเพิ่มขึ้นจาก Baseline ก็เป็นได้ นั่นแสดงถึง Output ของโครงการ/กิจกรรมว่าเป็นไปตามเป้าหมายหรือไม่ และเมื่อได้ผลการลดการใช้พลังงานแล้ว จึงค่อยต่อยอดการลดก๊าซ CO2e ต่อไป
อย่างไรก็ตาม Blog นี้ยังไม่ได้รวมถึงการประเมิน Outcome ที่จะไปกระทบกับแผนพลังงานของชาติ แผนจัดการพลังงานและแผน PDP อีกนะคะ
The post ประเมินประสิทธิภาพพลังงานของโครงการโรงไฟฟ้า appeared first on EnergyThai.
ประเมินประสิทธิภาพพลังงานของโครงการโรงไฟฟ้า
ต่อจาก Blog ที่แล้วได้แบ่งนิยามการปรับปรุงอุปกรณ์ของโรงไฟฟ้าไว้เป็น 3 ระดับ ใน Blog วันนี้เพิ่มเติมการสร้างและเปลี่ยนโรงไฟฟ้าใหม่ และต่อยอดจากการปรับปรุงที่ประโยชน์นอกจากการช่วยเพิ่มศักยภาพการผลิตให้สูงขึ้น ลดต้นทุนเชื้อเพลิง แล้วยังช่วยลดก๊าซเรือนกระจกตอบสนองเป้าหมายรักษ์โลกอีกด้วย
ในฐานะประเทศที่ซื้อเทคโนโลยีมาใช้ดังประเทศไทย การสร้างโรงงานใหม่ย่อมต้องอาศัยการติดตามเทคโนโลยีของผู้ผลิต (OEM: Original Equipment Manufacturer) ซึ่งมีการ Trigger ผู้ใช้ (Technology User) ตามเวลาที่เหมาะสมอย่าง Dynamic ในบางครั้งไม่ใช่เลือกกันได้ง่ายๆ ตามพื้นฐานเดิมๆ ที่ใช้งานกันในประเทศ แต่เทคโนโลยีมีการเปลี่ยนแปลงอย่างก้าวกระโดด หรือเปลี่ยนรูปแบบการให้ความร้อน (Heat) ยกตัวอย่างเช่น การเผาไหม้เชื้อเพลิงเพื่อให้ความร้อนกับ Working Fluid ในกระบวนการผลิต เปลี่ยนเป็น การให้ความร้อนจากพลังงานนิวเคลียร์โดยปฏิกริยา Fission กันไปเลย ดังนั้น ต้องมีการอัพเดทประสิทธิภาพของแต่ละเทคโนโลยีอย่างสม่ำเสมอ
แนวโน้มปัจจุบัน พบว่า ศาสตร์ที่มี Impact สูงต่อการเปลี่ยนเทคโนโลยีของการผลิตไฟฟ้ามาก คือ เคมี และ โลหการ เนื่องจาก โดยคอนเซ็ปต์คิดไปจนทะลุแล้ว จึงอยู่ในช่วงการทำให้ใช้งานจริงได้ (Mature Technology) ซึ่งเป็นยุคที่มีเป้าหมายเพื่อรักษาสิ่งแวดล้อม และมีความพยายามอย่างสูงสุดในการลดข้อจำกัดด้านวัสดุให้ทนต่อสภาพความดันและอุณหภูมิสูงได้ แสดงขั้นของการพัฒนาดังรูปที่ 1
 รูปที่ 1 กรอบเวลาและขั้นตอนของเทคโนโลยีด้านการผลิตไฟฟ้าอ้างอิงจากการประเมินและรวบรวมโดย Electric Power Research Institute อ่านเเพิ่มเติมที่ www.epri.com
รูปที่ 1 กรอบเวลาและขั้นตอนของเทคโนโลยีด้านการผลิตไฟฟ้าอ้างอิงจากการประเมินและรวบรวมโดย Electric Power Research Institute อ่านเเพิ่มเติมที่ www.epri.com
ภาพด้านล่างนี้แสดงในลักษณะของ Bubble Chart ของกิจกรรมที่เกิดขึ้นเพื่อการเพิ่มกำลังการผลิต และเพิ่มประสิทธิภาพการใช้เชื้อเพลิง กำหนดให้ขนาดของ Bubble Chart แสดงถึงปริมาณเชื้อเพลิงที่ใช้ในระดับปกติ (Baseline) และเมื่อมีการทำโครงการต่างๆ ขนาดของ Bubble เส้นประแสดงถึงปริมาณการใช้เชื้อเพลิงที่ลดลงจากระดับปกติ (Project) ซึ่งปัจจุบันปี ค.ศ. 2015 อยุู่ในช่วงที่ประสิทธิภาพการผลิตจากถ่านหินและก๊าซธรรมชาติที่ 38% และ 47% ตามลำดับ
 รูปที่ 2 Project Greenhouse Gas Reduction
รูปที่ 2 Project Greenhouse Gas Reduction
 รูปที่ 3 การลดก๊าซเรือนกระจกของกรณีฐานและกรณีดำเนินโครงการ
รูปที่ 3 การลดก๊าซเรือนกระจกของกรณีฐานและกรณีดำเนินโครงการ
อ้างอิง องค์การบริหารจัดการก๊าซเรือนกระจก
เป็นเช่นเดียวกับการปล่อยก๊าซเรือนกระจก หรือ CO2e (ก๊าซคาร์บอนไดออกไซด์เทียบเท่า) ซึ่งเมื่อการใช้เชื้อเพลิงลดลง การปล่อย CO2e ย่อมลดลงเช่นเดียวกัน ตามรูปที่ 3 ซึ่งเป็นวิธีการคำนวณก๊าซเรือนกระจกที่ประกาศใช้โดย องค์การบริหารจัดการก๊าซเรือนกระจก
โดยสรุปคอนเซ็ปต์การประเมินประสิทธิภาพพลังงานของ โครงการ หรือ กิจกรรมใดใด ในโรงไฟฟ้า โรงงานอุตสาหกรรม จำเป็นต้องจัดลำดับความสำคัญของแนวคิดให้ถูกต้อง โดยมีจุดเริ่มต้นจาก ประเมินปริมาณการใช้พลังงานภาพรวมของแต่ละระดับก่อน (Baseline) ถัดมาเมื่อมีการดำเนินโครงการแล้วจึงได้ปริมาณการใช้พลังงานซึ่งอาจลดลงหรือเพิ่มขึ้นจาก Baseline ก็เป็นได้ นั่นแสดงถึง Output ของโครงการ/กิจกรรมว่าเป็นไปตามเป้าหมายหรือไม่ และเมื่อได้ผลการลดการใช้พลังงานแล้ว จึงค่อยต่อยอดการลดก๊าซ CO2e ต่อไป
อย่างไรก็ตาม Blog นี้ยังไม่ได้รวมถึงการประเมิน Outcome ที่จะไปกระทบกับแผนพลังงานของชาติ แผนจัดการพลังงานและแผน PDP อีกนะคะ
The post ประเมินประสิทธิภาพพลังงานของโครงการโรงไฟฟ้า appeared first on EnergyThai.
เปิดแผนพัฒนากำลังผลิตไฟฟ้าของเพื่อนบ้าน
เปิดแผนพัฒนากำลังผลิตไฟฟ้าของเพื่อนบ้าน
แผนพัฒนากำลังผลิตไฟฟ้าของประเทศต่างๆ สะท้อนนโยบายของประเทศ ณ ขณะนั้น และแสดงถึงการใช้พลังงานเพื่อการผลิตในประเทศซึ่งเป็นพลังงานพื้นฐานสำหรับอุตสาหกรรม ขนส่ง ครัวเรือนในประเทศทั้งหมด อีกทั้งภาค Power Generation เป็นภาคการผลิตที่มีการปล่อยก๊าซเรือนกระจก ซึ่งเป็น Emission ที่ได้รับความสนใจอย่างมากในช่วงนี้
จากที่ประเทศไทยได้ประกาศ แผนพัฒนากำลังผลิตไฟฟ้าของประเทศไทย ปี 2558-2579 ที่รู้จักกันในชื่อเล่น ว่า พีดีพี2015 (PDP2015) เมื่อ 30 มิถุนายน 2558 นั้น
ใน พีดีพี2015 นี้ได้แสดงก๊าซเรือนกระจก (GHG: Greenhouse Gas) ที่มีแนวโน้มลดลงทั้งในแบบปริมาณ (Absolute พันตัน : 1000 TonCO2e) และความเข้มข้น (Intensity kgCO2e/kWh) ซึ่งสอดคล้องกับการประกาศแสดงเป้าหมายของประเทศไทยอย่างตั้งใจว่าเป้าหมายลด GHG 20%-25% สำหรับการทำ INDCs: Intended Nationally Determined Contributions ภายในปี 2030 ตามรูป
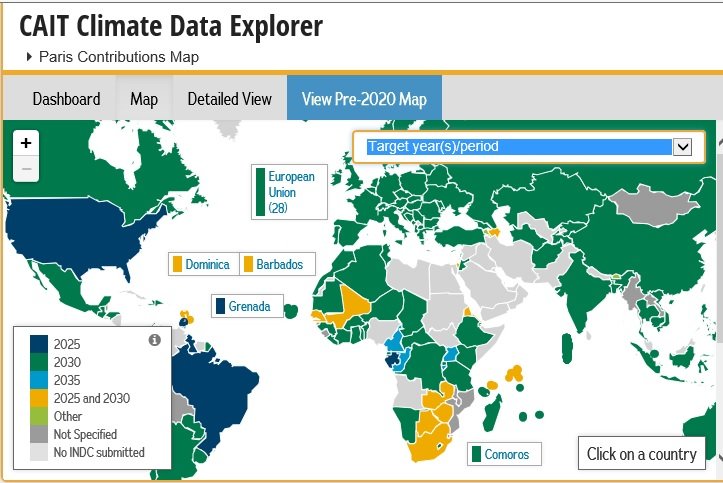
(Source: www.climatecentral.org สามารถคลิ๊กแสดงผลได้หลายรูปแบบ )
โดยประเทศในกลุ่ม CLMV: Cambodia, Laos, Myanmar, Vietnam รวมถึงไทยเรา ได้มีการประกาศเป้าหมายไปแล้วคือ ประเทศไทย กัมพูชา และเวียดนาม แสดงว่าภาพต่อสหประชาชาติ มีความชัดเจนว่า ใน 3 ประเทศนี้ต้องมีการทำขับเคลื่อนนโยบาย ประกาศ ดำเนินการอย่างเป็นรูปธรรมอย่างใดอย่างหนึ่งแสดงให้เห็นเร็วๆ นี้
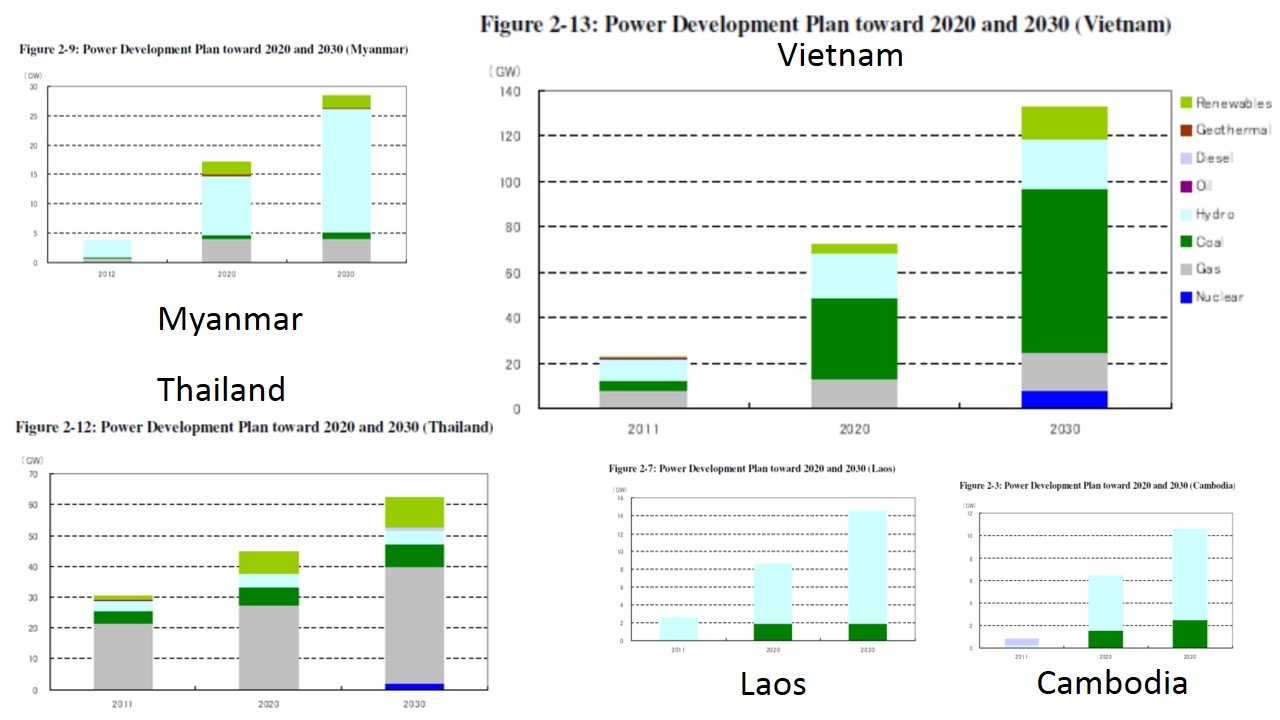 Source: อ่านฉบับเต็มจาก www.eria.org
Source: อ่านฉบับเต็มจาก www.eria.org
เมื่อดูสถานการณ์แผนแต่ละประเทศ ได้นำมาเปรียบเทียบกับแผนของเราและแผนของเพื่อนบ้าน เพื่อดูวิสัยทัศน์การจัดลำดับความสำคัญของประเทศเราและรอบบ้านเรา ระหว่างต้นทุนพลังงาน และ การลดก๊าซเรือนกระจก ดังรูป แสดงให้เห็นว่า
ลำดับความสำคัญของไทย ซึ่งมีการผลิตไฟฟ้าด้วยก๊าซธรรมชาติ มาตั้งแต่อดีต มีความพยายามควบคุมต้นทุนโดยวางแผนให้มีการเพิ่มสัดส่วนของ พลังงานจากถ่านหินและนิวเคลียร์เข้ามา ดังนั้น ลำดับความสำคัญของไทยจึงเป็น ต้นทุนพลังงาน
ลำดับความสำคัญของเวียดนาม เป็นต้นทุนพลังงานอย่างเห็นได้ชัด จากการเพิ่มสัดส่วนของถ่านหิน และมีนิวเคลียร์ในแผน ท่ามกลางการวางแผนให้ประเทศเติบโตถึง 6 เท่าใน 20 ปี และไม่ทิ้งการรักษาระดับของก๊าซเรือนกระจกด้วยการมีพลังงานน้ำและพลังงานหมุนเวียนเพิ่มสัดส่วนขึ้นเช่นกัน กรณีนี้เมื่อเทียบกับไทย ซึ่งใช้ศักยภาพของน้ำอย่างเต็มที่แล้ว จึงมีเฉพาะสัดส่วนของพลังงานหมุนเวียนเท่านั้นที่รัฐพยายามผลักดันเพื่อให้ตอบนานาประเทศได้
ลำดับความสำคัญของกัมพูชา ลาว และเมียนม่าร์ เนื่องจากทั้ง 3 ประเทศมีปริมาณการใช้พลังงานไม่มาก และมีศักยภาพ Hydro อยู่ปริมาณมาก จึงใช้ทรัพยากรภายในประเทศอย่างเต็มที่ กรณีนี้จึงเป็นการช่วยให้ต้นทุนพลังงานต่ำ จึงใช้อย่างเต็มที่ อีก 20 ปี ก็ยังเป็นพลังงานสะอาดอยู่นั่นเอง อย่างไรก็ตาม กรณีกัมพูชามีการใช้พลังงานจากน้ำมันดีเซล (Diesel) เต็มที่ เข้าใจว่าน่าจะเหมือนกับประเทศพม่าที่มีเครื่องปั่นไฟอยุ่หน้าโรงแรม โรงงานขนาดใหญ่ และช่วงหลังมีการพัฒนาโรงไฟฟ้าพลังน้ำ และถ่านหินมาทดแทน เช่นเดียวกับประเทศลาว
อีกทั้งตัวเลขการเติบโต GDP ไทยและ ASEAN ล่าสุดจากธนาคารโลก พบความเป็นไปได้ของการตอบสนองค่าเป้าหมาย 3 ประเทศนี้ในกรณีที่ตั้งค่ากรณีฐาน Base Year ในอดีตดังเช่นประเทศพัฒนาแล้วเริ่มตั้งค่าเป้าหมายกัน แสดงดังนี้
ประเทศไทย : การเติบโตต่ำ การใช้พลังงานในประเทศย่อมเพิ่มขึ้นน้อย เป้าหมายการลด GHG ย่อมมีความเป็นไปได้สูง
กัมพูชา : ทรัพยากรน้ำในประเทศกัมพูชามีมาก คาดการณ์เป้าหมายการปล่อย GHG ค่อนข้างไม่ซีเรียส เพราะการใช้พลังงานในประเทศที่ปล่อย GHG สูงนั้นแทบไม่มีอยู่แล้ว แต่อย่างไรก็ตาม การประกาศเป้าหมายการลด GHG นี่สิ! จะต้องมีคำตอบระดับยุทธศาสตร์ประเทศแล้วว่า ประเทศตั้งเป้าหมายการ Growth ในช่วง 10-20 ปีข้างหน้านี้อย่างไร ยอมรับว่าน่าจะคิดหนักมากทีเดียว แต่ยอมรับว่าเป็นประเทศกัมพูชามีความมั่นใจกับการประกาศค่าเป้าหมายมาก สำหรับประเทศที่มีสถานะทรัพยากรน้ำมากเหมือนกัน เช่น ลาว เมียนม่าร์ ยังไม่ประกาศ
เวียดนาม: การเติบโตของประเทศสูงมากแสดงจากปริมาณ GW ที่เพิ่มสูงขึ้นเกือบ 2 เท่าตัวของไทยในปี ค.ศ.2030 และการใช้พลังงานจากถ่านหินมีสัดส่วนที่สูงขึ้นในปริมาณที่สูงขึ้น ยิ่งทวีขึ้นไปอีก ดังนั้น การตั้งเป้าหมายของประเทศเวียดนามมีความท้าทายสูง การเจรจาต่อรองก็มีความท้าทายสูงมากเช่นกัน
ดังนั้น ประเทศเวียดนามนี้ น่าจะมีกิจกรรมของประเทศที่น่าสนใจมากทีเดียว ระหว่างการเติบโตของประเทศ การใช้พลังงานที่เพิ่มสูงขึ้น การควบคุมต้นทุนเชื้อเพลิง และการคำนึงถึงด้านการลดก๊าซเรือนกระจก ว่าจะมีการสร้างสมดุลอย่างไร !
The post เปิดแผนพัฒนากำลังผลิตไฟฟ้าของเพื่อนบ้าน appeared first on EnergyThai.
LibThai Thread-safety
อันเนื่องมาจากการที่ Pango 1.38.0 ที่ออกมาพร้อมกับ GNOME 3.18 ได้ตัดระบบ dynamic module ทิ้ง แล้วใช้วิธีรวมเข้าในซอร์สโค้ดเลย (GNOME #733882) ทำให้ผู้ดูแลหลัก คือ Behdad Esfahbod ได้มีโอกาสรื้อมอดูลภาษาต่าง ๆ รวมถึงภาษาไทย และพบประเด็นของ libthai ที่รองรับการตัดคำของมอดูลภาษาไทยอยู่ จึงได้ติดต่อมาที่ผมเพื่อให้แก้ไข โดยประเด็นสำคัญคือเรื่อง thread-safety
โค้ดใน libthai มีส่วนหนึ่งที่ทำให้ไม่ปลอดภัยเมื่อเรียกใช้ผ่าน thread หลาย thread พร้อมกัน ซึ่งเป็นส่วนที่ผมใช้ลดปริมาณการเรียก malloc() โดยยังไม่ free() โหนดทางเลือกต่าง ๆ ของการตัดคำที่เลิกใช้แล้วในทันที แต่เอาไปฝากไว้ใน free list เพื่อนำกลับมาใช้ใหม่ และไอ้เจ้า free list ที่เป็นเสมือนโกดังเก็บของเก่ารอ reuse นี่แหละ ที่ implement แบบ static โดยไม่มีการจองก่อนเข้าใช้ ทำให้เมื่อมีหลาย thread เข้าใช้พร้อมกันจะเกิด race condition ขึ้นได้
ประเด็นนี้ pango รุ่นนี้แก้ปัญหาเฉพาะหน้าด้วยการ ล็อคก่อนเรียก th_brk() เพื่อให้ thread ต่าง ๆ เข้าใช้ฟังก์ชันนี้ทีละ thread ซึ่งอาจกลายเป็นคอขวดของระบบหลาย thread ได้ ทางที่ดีคือทำให้ libthai threadsafe เสีย
ทางเลือกที่เป็นไปได้จึงมี 3 ทาง
- ยกเลิก free list ไปเสีย (ซึ่ง Behdad สนับสนุน โดยให้เหตุผลว่า malloc() ใน libc รุ่นหลัง ๆ ทำงานเร็วขึ้นมากแล้ว และ CPU สมัยใหม่ก็ทำงานเร็วขึ้นมากแล้วด้วย จะไปนั่งออปติไมซ์ทำไมให้เมื่อยตุ้ม)
- ใช้ free list 1 ชุดต่อ 1 thread แทนที่จะใช้ร่วมกันหมด (แต่ละ thread เก็บโหนดที่เลิกใช้ไว้ในกระเป๋า recycle ของใครของมัน ไม่ต้องใช้ร่วมกัน)
- ใช้ free list กลางเหมือนเดิม แต่ให้มีระบบ lock (แต่ละ thread ต้องล็อคโกดังขณะเข้าใช้ thread อื่นต้องรอให้ thread ที่ใช้งานอยู่ใช้ให้เสร็จเสียก่อนจึงจะเข้าใช้ได้)
วิธียกเลิก free list อาจจะง่าย แต่ก่อนจะเชื่อก็ต้องวัดดูก่อน ซึ่งจากการทดลองของผมก็พบว่า th_brk() จะทำงานนานขึ้นถึง 18% ถ้าใช้ malloc() ตรง ๆ ทุกครั้ง หรือถ้าเทียบกลับ การใช้ free list สามารถประหยัดเวลาจากการใช้ malloc() ได้ถึง 15% ซึ่งผมถือว่ามีนัยสำคัญ ฉะนั้นจึงไม่เลือกวิธีนี้
จากนั้นจึงมาทดลองวิธีใช้ free list 1 ชุดต่อ 1 thread ซึ่งวิธีการก็ไม่ได้มีอะไรมาก เพียงแค่เปลี่ยนจากการใช้ตัวแปร static มาเป็นการสร้าง free list ใหม่ในการเรียก th_brk() แต่ละครั้งเท่านั้นเอง เนื่องจากตัว libthai เองไม่ได้สร้าง thread ใหม่อยู่แล้ว การสร้าง thread เกิดจากโค้ดผู้เรียกอย่าง pango หรือผู้ที่เรียก pango อีกทีทั้งสิ้น การสร้าง free list ต่อ 1 call ก็เท่ากับการสร้างต่อ 1 thread นั่นเอง
ผลการทดลองคือ free list แบบต่อ thread ก็ยังสามารถประหยัดเวลาได้ถึง 13% (2% ที่หายไปพบภายหลังว่าเกิดจากการสร้าง free list ผิดจากจุดเดิมในโค้ด ทำให้เกิดการสร้างและทำลาย free list เพิ่มขึ้น เมื่อแก้ให้ตรงกับจุดเดิมก็ปรากฏว่าประหยัดเวลาได้เท่าๆ ของเดิม) ซึ่งถือว่าน่าพอใจ
วิธีสุดท้ายที่ใช้ระบบล็อคนั้น จะทำให้ libthai ต้องมีการแทรกโค้ดการเรียก pthread เข้ามา ซึ่งทำให้โค้ดส่วนนี้ดูแปลกแยกไม่สวยงาม และในเมื่อวิธีที่ใช้ free list ต่อ thread ได้ผลเป็นที่น่าพอใจอยู่แล้ว ผมจึงไม่พิจารณาวิธีนี้อีก
จึงได้เป็น rev 577 (และแก้ไขเพิ่มเติมใน rev 583 หลังจากพบสาเหตุที่ทำให้การประหยัดเวลาลดลง 2%)
นอกจากนั้น ก็เป็นความพยายาม optimize การตัดคำของ libthai ต่อ ดังรายการต่อไปนี้:
- optimize libdatrie ในส่วน AlphaMap (การแม็ปอักขระให้เป็นดัชนีสำหรับ trie transition ซึ่งจะเกิด ทุกครั้ง ที่มี transition) จากการคำนวณหาลำดับของอักขระจากช่วงต่าง ๆ ที่กำหนด มาเป็นการเปิดตารางที่สร้างไว้ล่วงหน้า ฟังดูอาจจะนึกว่ามันคงเร็วขึ้นอย่างมโหฬาร แต่สำหรับ libthai แล้วไม่ใช่ เนื่องจากเรากำหนดช่วงอักขระภาษาไทยเป็นช่วงต่อเนื่องเพียงช่วงเดียว การคำนวณลำดับอักขระจึงไม่ซับซ้อน เพียงแค่ลบด้วยอักขระแรกของช่วงแล้วบวกด้วย 1 ก็จบแล้ว การทำงานที่ประหยัดได้จากการเปิดตารางจึงเป็นเรื่องของโสหุ้ยของการวนลูปเล็ก ๆ น้อย ๆ เท่านั้น ซี่งปรากฏว่าทำให้ตัวฟังก์ชันใช้เวลาทำงานลดลง 14.6% และทำให้การตัดคำของ libthai ใช้เวลาลดลงโดยรวม 0.2% เท่านั้น (libdatrie rev 277) แต่สำหรับ use case ที่อักขระอินพุตมีหลายช่วงไม่ต่อเนื่อง การเปิดตารางนี้จะช่วยประหยัดเวลาได้มาก
- optimize libthai ในส่วนของการยุบรวมกรณีตัดคำที่ตกตำแหน่งเดียวกัน (การตัดคำของ libthai ใช้วิธีลองตัดคำแบบต่าง ๆ เทียบกับพจนานุกรม แล้วเลือกเอาวิธีที่ได้จำนวนคำน้อยที่สุด โดยใช้การค้นแบบ best-first search ซึ่งคล้ายกับ breadth-first search แต่มีการคำนวณ heuristic ของกรณีต่าง ๆ และยุบรวมกรณีที่คืบหน้าเท่ากันเป็นระยะ ๆ) ซึ่งปรากฏว่าฟังก์ชัน brk_pool_match() ขึ้นชาร์ตฟังก์ชันที่กินเวลานานในรายงานของ Callgrind จึงพยายาม optimize ด้วยการทำให้ตัวฟังก์ชันเร็วขึ้นด้วยการแยกลูปเพื่อลด branching (rev 579 ตัวฟังก์ชันใช้เวลาลดลง 9.3%, runtime โดยรวมลดลง 0.067%) และด้วยการลดปริมาณงานของฟังก์ชันโดยค้นต่อจากจุดเดิมแทนการเริ่มที่ต้นลิสต์เสมอ (rev 582 ตัวฟังก์ชันใช้เวลาลดลง 8.85%, อันดับในชาร์ตเลื่อนลง 2 ขั้น, runtime โดยรวมลดลง 0.0388%) รวมแล้ว ตัวฟังก์ชันใช้เวลาลดลง 17.3% runtime โดยรวมลดลงประมาณ 0.1%
สรุปแล้ว การตัดตำของ libthai โดยรวมใช้เวลาลดลงประมาณ 0.28% (รวมเวลาโหลดพจนานุกรม) พร้อมกับปลอดภัยสำหรับการทำงานหลาย thread โดยไม่ต้องล็อคด้วย
ถ้าไม่มีไอเดียใหม่อีก ก็คงจะออกรุ่นใหม่เร็ว ๆ นี้ครับ
ในอีกด้านหนึ่ง ทีม debian-cd ได้กระทุ้งมาอีกครั้งว่าช่วยทำ udeb ของ libthai ให้หน่อย จะได้ใช้ในโปรแกรมติดตั้งของเดเบียน (Debian #800369) ก็ทยอยทำตั้งแต่ libdatrie1-udeb (0.2.9-3) รอจนผ่าน NEW queue แล้วก็ทำ libthai-data-udeb และ libthai0-udeb ต่อ (ขณะที่เขียน blog ยังรออยู่ใน NEW)
Thanks
ขอขอบคุณย้อนหลัง สำหรับผู้สนับสนุนงานพัฒนาซอฟต์แวร์เสรีของผมในช่วงปลายเมษายน 2558 ถึงต้นกันยายน 2558 ที่ผ่านมาครับ คือ:
- ปลายเดือนเมษายน 2558
- ผู้ไม่แสดงตน 1 ท่าน
- เดือนพฤษภาคม 2558
- อ.พฤษภ์ บุญมา
- คุณธนาธิป ศรีวิรุฬห์ชัย
- เดือนมิถุนายน 2558
- คุณธนาธิป ศรีวิรุฬห์ชัย
- ผู้ไม่แสดงตน 1 ท่าน
- เดือนกรกฎาคม 2558
- คุณธนาธิป ศรีวิรุฬห์ชัย
- ผู้ไม่ประสงค์จะออกนาม
- เดือนสิงหาคม 2558
- อ.พฤษภ์ บุญมา
- คุณธนาธิป ศรีวิรุฬห์ชัย
- ต้นเดือนกันยายน 2558
- คุณธนาธิป ศรีวิรุฬห์ชัย
- คุณเริงฤทธิ์ รักคณิ
- อ.พฤษภ์ บุญมา
ขอให้ทุกท่านมีความเจริญก้าวหน้าในหน้าที่การงาน คิดสิ่งใดก็ขอให้สมปรารถนานะครับ
สี่เดือนที่ผ่านมา นับจาก บันทึกขอบคุณครั้งที่แล้ว งานพัฒนาที่ทำไปพอสรุปได้ดังนี้:
- Optimize LibThai/LibDATrie เพิ่มเติม ตรวจสอบความเรียบร้อยทั่วไป และออกรุ่น libdatrie 0.2.9 และ libthai 0.1.22 พร้อมอัปโหลดเข้า Debian (libdatrie 0.2.9-1 และ libthai 0.1.22-1)
- ตามแก้ปัญหาในแพกเกจ libdatrie-dev และ libthai-dev ที่อัปโหลดไว้ ดังที่มีผู้รายงานบั๊ก Debian #788163 และ Debian #788164
- ออกรุ่น thaixfonts 1.2.7 ซึ่งได้เตรียมการแก้ปัญหาข้อมูล copyright ที่ขาดไว้ พร้อมทั้งเรื่อง reproducibility ที่ระบบของ Debian ตรวจพบ และแก้ปัญหาเล็ก ๆ น้อย ๆ ในตัว Debian package แล้วอัปโหลดเข้า Debian (thaixfonts 1.2.7-1)
- ปรับแก้ฟอนต์ในชุด Fonts-TLWG ต่อ เพื่อรองรับภาษามลายูปาตานีเต็มรูปแบบ พร้อมกับเตรียม fallback โดยใช้ภาษาแต้จิ๋วเป็นโจทย์ ดังที่ได้ บันทีกไว้ ซึ่งขณะนี้ยังอยู่ระหว่างดำเนินการต่อ
- อัปเดตแพกเกจ scim-thai ใน Debian เล็กน้อย เพื่อเป็นส่วนหนึ่งของการย้ายไป GCC5 ของ Debian
- อัปเดตคำแปลชื่อภาษาใน ISO 639 และ ISO 639-3 ในแพกเกจ iso-codes (มีผลใน iso-codes 3.61)
- ตรวจทานคำแปล GNOME ตามที่มีผู้ส่งเข้ามา
ขณะเดียวกัน ช่วงนี้งานที่ผมรับเพื่อ support ตัวเองเป็นงานสอน ซึ่งต้องใช้เวลาค่อนข้างมากในการเตรียมเนื้อหา จึงอาจเหลือเวลามาทำงานพัฒนาน้อยลง แต่ก็พยายามเจียดเวลาเท่าที่จะทำได้ครับ
ชไนเดอร์ อิเล็คทริค เผยผลสำรวจการใช้พลังงานของภาคธุรกิจไทย
ข่าวประชาสัมพันธ์
กรุงเทพฯ – 1 กันยายน 2558 : ชไนเดอร์ อิเล็คทริค จัดทำผลสำรวจด้านพลังงาน (Energy Survey) จากผู้เข้าร่วมงาน Xperience Efficiency 2015 กว่า 1,200 ราย ใน 4 จังหวัดใหญ่ที่เป็นศูนย์กลางด้านเศรษฐกิจ และอุตสาหกรรมทั้ง กรุงเทพมหานคร ระยอง ขอนแก่น และสุราษฎ์ธานี ผลสำรวจชี้ชัดทั้งภาคธุรกิจ และภาคอุตสาหกรรมต่างมุ่งให้ความสำคัญกับแนวคิดการใช้พลังงานอย่างมีประสิทธิภาพ (energy efficiency) เพื่ออนาคตทางธุรกิจที่ยั่งยืน
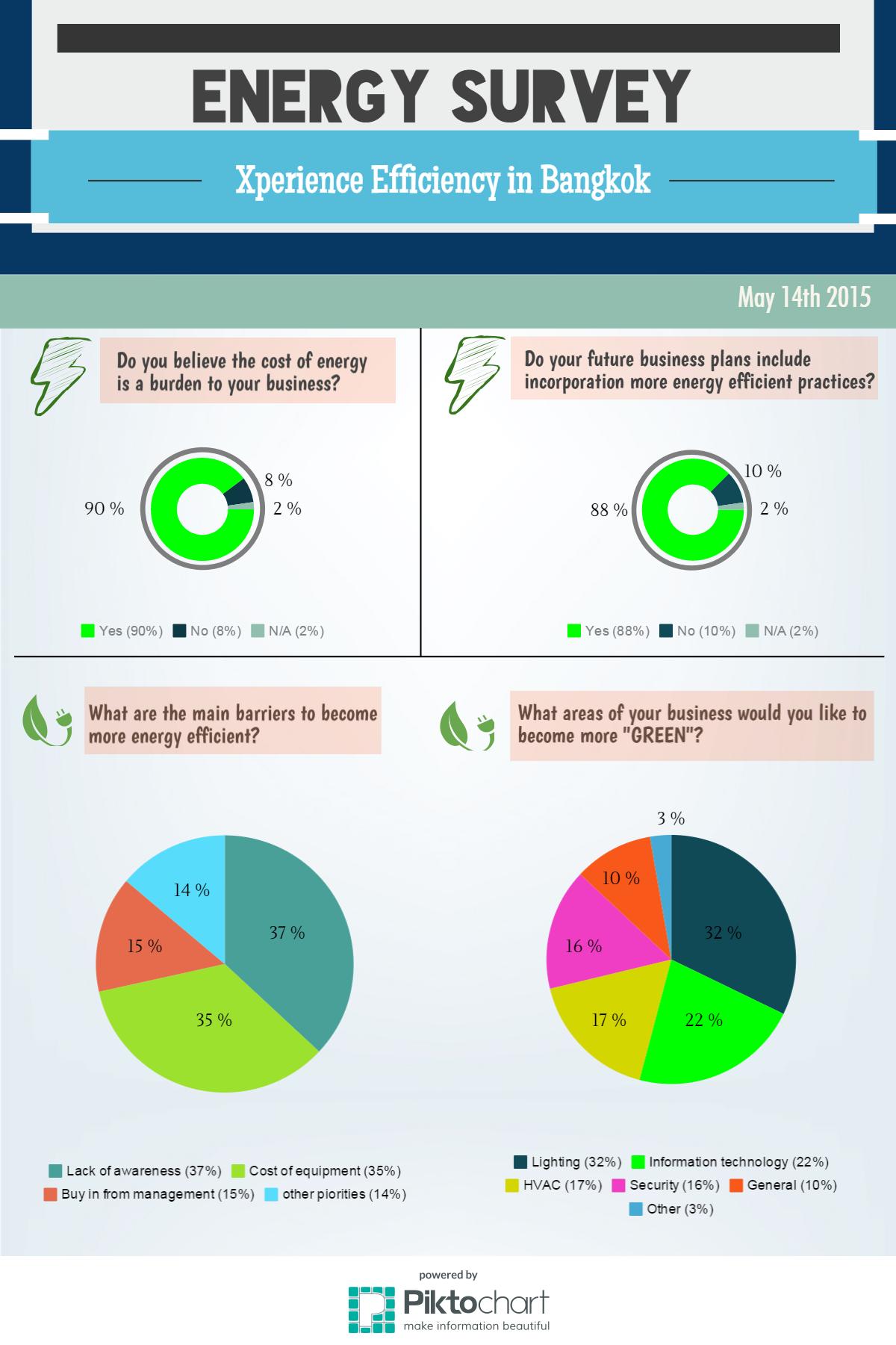 ผลสำรวจ Energy Efficiency ของ กรุงเทพมหานคร
ผลสำรวจ Energy Efficiency ของ กรุงเทพมหานคร
มร.มาร์ค เพลิทิเยร์ ประธาน ชไนเดอร์ อิเล็คทริค ประเทศไทย กล่าวว่า “ในการสำรวจดังกล่าว ชไนเดอร์ อิเล็คทริค ได้แยกผลการสำรวจการใช้พลังงานออกเป็น 2 กลุ่มหลัก ได้แก่ กลุ่มภาคธุรกิจ อันประกอบไปด้วย องค์กรธุรกิจขนาดต่างๆ ในกรุงเทพมหานคร และภาคอุตสาหกรรมต่างจังหวัด ซึ่งประกอบด้วยผู้ผลิตจากอุตสาหกรรมต่างๆ เพื่อเป็นการรับทราบแนวคิด ตลอดจนความพร้อมขององค์กรธุรกิจ ผู้ประกอบการ และผู้ผลิตในอุตสาหกรรมต่างๆ ในการนำแนวคิด และเทคโนโลยีด้านการประหยัดพลังงานไปใช้อย่างมีประสิทธิภาพ”
จากผลสำรวจ ภาคธุรกิจ และภาคอุตสาหกรรมต่างมองว่าต้นทุน และค่าใช้จ่ายด้านพลังงานคือภาระชิ้นสำคัญทั้งในการดำเนินธุรกิจ และในการการผลิตสูงถึงร้อยละ 90 และร้อยละ 88 ตามลำดับ ผู้ตอบแบบสอบถามทั้งสองกลุ่มต่างต้องการที่จะนำแนวคิดด้านการประหยัดพลังงาน และการใช้พลังงานอย่างมีประสิทธิภาพเข้ามารวมอยู่ในแผนการดำเนินธุรกิจในอนาคตสูงถึงร้อยละ 88 ในกลุ่มธุรกิจ และร้อยละ 91 จากกลุ่มผู้ผลิต
 ผลสำรวจ Energy Efficiency จากภาคอุตสาหกรรม จังหวัด ขอนแก่น ระยอง และสุราษฎร์ธานี
ผลสำรวจ Energy Efficiency จากภาคอุตสาหกรรม จังหวัด ขอนแก่น ระยอง และสุราษฎร์ธานี
หากพิจารณาถึงอุปสรรคสำคัญในการใช้พลังงานอย่างมีประสิทธิภาพแล้วนั้น ทั้งสองกลุ่มให้ความเห็นไปในทิศทางเดียวกันว่า อันดับ 1) คือการขาดความรู้ ความเข้าใจที่มีต่อการใช้พลังงาน (ร้อยละ 43 ในกลุ่มผู้ผลิต และร้อยละ 37 ในกลุ่มธุรกิจ) อันดับ 2) คือต้นทุน และค่าใช้จ่ายด้านอุปกรณ์ (ร้อยละ 38 ในกลุ่มผู้ผลิต และร้อยละ 35 ในกลุ่มธุรกิจ) อันดับ 3) คือการได้รับความเห็นชอบ และยอมรับจากฝ่ายบริหาร (ร้อยละ 10 ในกลุ่มผู้ผลิต และร้อยละ 15 ในกลุ่มธุรกิจ)
นอกจากนี้ การสำรวจยังเจาะลึกถึงความต้องการของทั้งภาคธุรกิจ และภาคอุตสาหกรรมว่าต้องการปรับส่วนใดในการทำงานพื่อให้องค์กร หรือโรงงานมีความเป็นมิตรต่อสิ่งแวดล้อม หรือเป็น “กรีน” เพิ่มมากขึ้น ทั้งสองกลุ่มมีความเห็นเดียวกันคือ การปรับระบบการใช้แสงสว่าง (Lighting) เป็นอันดับแรกที่อยากมีการปรับเปลี่ยน โดยในอันดับ 2 กลุ่มธุรกิจใ ห้ความสนใจในการปรับปรุงระบบเทคโนโลยีสารสนเทศ ในขณะที่ภาคอุตสาหกรรมให้ความสำคัญกับระบบความร้อนความเย็นและระบบปรับอากาศ (HVAC)
“ชไนเดอร์ อิเล็กทริค ในฐานะผู้นำระดับโลกด้านระบบการบริหารจัดการพลังงานและออโตเมชั่น รู้สึกยินดีที่ได้เห็นว่าทั้งภาคธุรกิจ และภาคอุตสาหกรรมของไทย ต่างตระหนักและหันมาให้ความสำคัญในด้านการประหยัดพลังงาน รวมถึงการเตรียมความพร้อมที่จะนำแนวคิดการใช้พลังงานอย่างมีประสิทธิภาพสูงสุดเข้าไปใช้ในการวางแผนการดำเนินงาน และการทำธุรกิจให้เติบโตอย่างยั่งยืน อย่างแท้จริงในอนาคต โดย ชไนเดอร์ อิเล็คทริค จะเดินหน้าสร้างความรู้ความเข้าใจเกี่ยวกับการบริหารจัดการพลังงานอย่างมีประสิทธิภาพสู่ภาคธุรกิจและอุตสาหกรรมในวงกว้าง เพื่อให้ทุกภาคส่วนสามารถวางแผนจัดการพลังงานอย่างเกิดประโยชน์สูงสุด” มร.มาร์ค กล่าวทิ้งท้าย
The post ชไนเดอร์ อิเล็คทริค เผยผลสำรวจการใช้พลังงานของภาคธุรกิจไทย appeared first on EnergyThai.
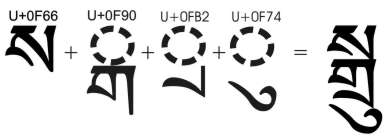
Patani Malay Support in Fonts-TLWG with Teochew Experiment
โครงการ fonts-tlwg กำลังอยู่ระหว่างพัฒนาเพิ่มเติมให้รองรับภาษาชาติพันธุ์ที่เขียนด้วยอักษรไทยได้สมบูรณ์ยิ่งขึ้น โดยรอบนี้เจาะไปที่ภาษามลายูปาตานีที่นอกจากจะต้องผ่อนคลายกฎการซ้อนอักขระต่าง ๆ แล้ว ยังต้องการอักขระเพิ่มเติมจากบล็อคยูนิโค้ดภาษาไทยอีก 4 ตัว เพื่อเป็นเครื่องหมายกำกับเสียงอ่าน กล่าวคือ:
- U+0303 COMBINING TILDE คือสัญลักษณ์ตัวหนอนที่เขียนกำกับเหนือพยัญชนะเพื่อให้ออกเสียงขึ้นจมูก (เสียงนาสิก) คงได้แนวคิดจากตัว ñ ในภาษาสเปน
- U+0331 COMBINING MACRON BELOW คือสัญลักษณ์ขีดเส้นใต้พยัญชนะเพื่อตัดเสียงนาสิกออกจากพยัญชนะนาสิกของไทย 4 ตัว คือ ง ญ น ม
- U+02BC MODIFIER LETTER APOSTROPHE ใช้ในการลดรูปคำให้เหลือจำนวนพยางค์น้อยลง
- U+02D7 MODIFIER LETTER MINUS ใช้ในการกล้ำสองพยางค์ให้ต่อเนื่องเป็นพยางค์เดียว
สองตัวหลังดูไม่มีอะไรมาก แค่เพิ่ม glyph ให้ก็ดูจะเพียงพอ แต่สองคัวแรกซึ่งเป็นอักขระประกอบ (combining character) ก็เลยมีปฏิสัมพันธ์กับสระบน-ล่าง วรรณยุกต์ และเครื่องหมายกำกับเสียงของไทย ทำให้ต้องมาจัดระเบียบใหม่ ซึ่งปรากฏว่าต้องทั้งขยับอักษรไทย ทั้งเปลี่ยนลำดับ normalization ของยูนิโค้ดด้วย
ตัวหนอนบอกเสียงนาสิกดูจะไม่มีประเด็นอะไรสำหรับภาษามลายูปาตานี เนื่องจากคำที่มีเครื่องหมายนี้จะไม่มีสระบนและวรรณยุกต์กำกับอยู่แล้ว ส่วนตัวขีดเส้นใต้ก็ควรขีดเส้นใต้พยัญชนะที่ความกว้างไม่เท่ากันให้สวยงามทั้งสี่ตัวด้วย (กล่าวคือ ไม่ใช่ใช้อักขระเดียวขีดเส้นใต้อักขระทุกตัว แต่ความยาวของขีดควรปรับตามความกว้างของพยัญชนะด้วย) รวมทั้งต้องตัดเชิง ญ เมื่อขีดเส้นใต้ด้วย
ก็ดูไม่ยุ่งยากอะไร ตัวหนอนก็แค่ทำประหนึ่งมันเป็นสระอิอีอึอือเสียก็จบ ส่วนตัวขีดเส้นใต้ก็สร้าง ligature glyph สำหรับ ง ญ น ม ขีดเส้นใต้สำเร็จรูปเท่านั้นเอง ผลออกมาก็งามน่าแล
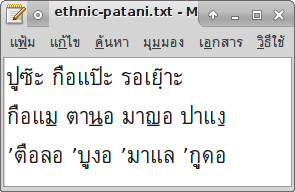
แต่ช้าก่อน ฟีเจอร์ของภาษามลายูปาตานีฟังดูน่าสนใจไม่น้อยสำหรับคนพูดภาษาแต้จิ๋วอย่างผม
- เสียงนาสิกเป็นตัวแยกความหมายของคำในภาษาแต้จิ๋ว ภาษาไทยมีเสียงนาสิกแค่ไม่กี่เสียง คือ ง ญ ณ น ม ถ้าพยัญชนะต้นไม่ใช่เสียงพวกนี้ก็จะไม่ออกเสียงขึ้นจมูก (ญ ไม่มีเสียงนาสิกในไทยกลาง แต่ยังมีในไทยอีสาน [ดู blog เก่าประกอบ] และอาจจะมี ห ฮ ที่ยังขึ้นจมูกบ้างไม่ขึ้นบ้างแล้วแต่สำเนียง) แต่ภาษาแต้จิ๋วสามารถขึ้นจมูกได้ทุกพยางค์ และยังเป็นตัวแยกความหมายอีกด้วย เช่น คำว่า 碗 ที่แปลว่า ชาม จะออกเสียงเป็น อั้ว พร้อมเสียงขึ้นจมูก ซึ่งจะแตกต่างจากคำว่า 我 ที่เป็นสรรพนามบุรุษที่หนึ่งเอกพจน์ ซึ่งออกเสียงเป็น อั้ว เหมือนกันแต่ไม่ขึ้นจมูก ในเมื่อเสียงนาสิกมีความสำคัญถึงขนาดแยกความหมายของคำในภาษาแต้จิ๋วเช่นนี้ ตัวหนอนกำกับเสียงนาสิกของมลายูปาตานีจึงน่าจะนำมาใช้กับแต้จิ๋วได้
- พยัญชนะที่ตัดเสียงนาสิกในภาษาแต้จิ๋วก็มี เช่นในคำว่า 牛 ที่แปลว่า วัว จะออกเสียงเป็น ก๎งู๊ คือเป็น ง ที่กล้ำกับเสียง ก ที่คอและไม่ขึ้นจมูก เสียงพยัญชนะนี้ไม่มีในภาษาไทย และมีความยากลำบากในการเขียนด้วยอักษรไทยมาก ตัวขีดเส้นใต้ตัดเสียงนาสิกของมลายูปาตานีก็น่าจะนำมาใช้ได้เช่นกัน
แต่การนำเครื่องหมายทั้งสองมาใช้กับภาษาแต้จิ๋วก็ทำให้พบกับ requirement ที่สูงขึ้น เพราะพยางค์ในภาษาแต้จิ๋วสามารถผสมกับสระและวรรณยุกต์ของไทยได้อย่างอิสระกว่ามาก ทำให้ตัวหนอนบอกเสียงนาสิกต้องสามารถผสมกับไม้หันอากาศและสระอิอีอึอือและใช้วรรณยุกต์ได้ด้วย ส่วนตัวขีดเส้นใต้ก็ต้องผสมกับสระล่างได้ด้วยเช่นกัน
ในการทำฟอนต์นั้น ไม่ใช่ว่าเราจะรองรับเฉพาะอักขรวิธีที่กำหนดไว้เท่านั้น แต่ยังควรเตรียม fallback สำหรับรองรับการแสดงผลรูปแบบที่อยู่นอกเหนือจากที่กำหนดด้วยตามสมควร ถึงแม้ไม่มีโจทย์ภาษาแต้จิ๋ว ก็ต้องคิดเผื่ออยู่แล้วว่าจะจัดการกับกรณีทั่วไปที่อยู่นอกเหนือข้อกำหนดของภาษามลายูปาตานีอย่างไร การมีโจทย์สมมุติของภาษาแต้จิ๋วเช่นนี้ก็เท่ากับทำให้เห็นแนวทางชัดเจนยิ่งขึ้น
ประเด็นของโจทย์ก็คือ:
- ตัวหนอนนาสิก ฐานข้อมูลอักขระยูนิโค้ดกำหนดให้มี combining class 220 ในขณะที่วรรณยุกต์ไทยเป็น class 107 ตามหลัก normalization ของยูนิโค้ด จะเรียงลำดับอักขระที่อยู่ระหว่างอักขระ class 0 (ได้แก่พยัญชนะบนบรรทัด) ตามลำดับ combining class จากน้อยไปหามาก (เรียกว่า canonical order) ผลคือ เมื่อตัวหนอนนาสิกผสมกับวรรณยุกต์ไทย rendering engine จะสลับมันไปอยู่หลังวรรณยุกต์ก่อนส่งให้ฟอนต์แสดงผลเสมอ แต่สิ่งที่เราต้องการคือวางตัวหนอนก่อนวรรณยุกต์ เพื่อให้อยู่ชิดพยัญชนะ แล้วจึงซ้อนวรรณยุกต์ทับทีหลัง ดังนั้น ฟอนต์จะต้องรู้จักกลับลำดับคืนด้วย แต่ถ้ามีสระบนมาคั่นกลางก็ไม่ต้องทำอะไร เพราะสระบน, ไม้ไต่คู้, ทัณฑฆาต, นิคหิต, ยามักการ ต่างถูกกำหนด combining class เป็น 0 เหมือนพยัญชนะบนเส้นบรรทัด จึงเป็นจุดกั้นแบ่งโซนการเรียงลำดับ combining character โดยปริยาย
- ตัวขีดเส้นใต้ ฐานข้อมูลอักขระยูนิโค้ดกำหนดให้มี combining class 220 ในขณะที่สระอุ สระอู มี combining class เป็น 103 (แต่ Uniscribe และ Harfbuzz แก้เองให้เป็น 3 ด้วยเหตุผลใดไม่อาจทราบได้) และพินทุมี combining class เป็น 9 ทำให้ตัวขีดเส้นใต้จะถูก rendering engine normalize ให้ไปอยู่หลังสระล่างและพินทุเสมอ และถ้ามีวรรณยุกต์ก็จะเลื่อนไปอยู่หลังวรรณยุกต์ด้วย แต่สิ่งที่เราต้องการคือวางตัวขีดเส้นใต้ก่อนเพื่อน เพื่อให้อยู่ชิดพยัญชนะ ดังนั้น ฟอนต์จะต้องรู้จักกลับลำดับคืนด้วย
- พินทุกับสระล่าง ตาม combining class ในฐานข้อมูลอักขระยูนิโค้ดแล้ว พินทุ (class 9) จะต้องมาก่อนสระล่าง (class 103) ใน canonical order ซึ่งเป็นสิ่งที่ต้องการอยู่แล้วสำหรับภาษามลายูปาตานี แต่ด้วยเหตุผลกลใดไม่ทราบได้ Uniscribe ของไมโครซอฟท์ได้แก้ทับคลาสของสระล่างจาก 103 เป็น 3 ทำให้สระล่างมาก่อนพินทุ และเพื่อความเข้ากันได้กับ Uniscribe ทำให้ Harfbuzz ก็ทำอย่างเดียวกันด้วย สิ่งที่ฟอนต์ต้องทำคือกลับลำดับนี้คืนอีกชั้นหนึ่ง
ปัญหาของตัวหนอนนาสิกไม่มีอะไรซับซ้อน แก้ได้ด้วยการเพิ่มกฎ GSUB สำหรับสลับตัวหนอนนาสิกกับวรรณยุกต์ทั้งสี่ตัวเท่านั้นก็จบ และอาจจะนับตัวหนอนเป็นสระบนอีกหนึ่งตัวในกฎที่ยกไม้ไต่คู้ นิคหิต ยามักการขึ้นสูงและย่อขนาดลงเพื่อความสวยงามสักหน่อยด้วย
แต่ปัญหาของตัวขีดเส้นใต้ซับซ้อนกว่าที่คาดไว้มาก เพราะมีประเด็นอื่นที่ต้องพิจารณาร่วมด้วยอีก 2 ประเด็น คือ
- การขีดเส้นใต้ ง ญ น ม ซึ่งความกว้างไม่เท่ากัน จัดการได้ด้วยการสร้าง precomposed glyph ที่ขีดเส้นใต้พยัญชนะดังกล่าวเสร็จสรรพ (ตัดเชิงสำหรับ ญ ไปในตัว) พร้อมกฎ ligature สำหรับเปลี่ยนคู่อักขระให้เป็นตัว precomposed กฎนี้ต้องทำงานในขณะที่พยัญชนะดังกล่าวกับตัวขีดเส้นใต้อยู่ติดกัน
- กฎเดิมที่จัดการกรณีคำว่า ปู่ ซึ่งจะเปลี่ยนวรรณยุกต์ให้เป็นตัวต่ำพร้อมกับสลับสระล่างกับวรรณยุกต์ให้วรรณยุกต์มาก่อน เพื่อจะได้วางหลบหาง ป ฝ ฟ (และอาจจะ ฬ) ด้วย GPOS ได้ กฎนี้ต้องทำงานในขณะที่สระล่างตามหลังด้วยวรรณยุกต์ทันที
การเพิ่มกฎสำหรับกลับลำดับตัวขีดเส้นใต้จึงต้องระวังที่จะไม่ไปกีดขวางการทำงานของกฎดังกล่าวด้วย โดยถ้าทำก่อน ตัวขีดเส้นใต้ก็จะมาขวางกฎ ปู่ ให้ไม่ทำงาน และถ้าทำทีหลัง วรรณยุกต์จากกฎ ปู่ ก็จะมาขวางกฎสร้าง precomposed glyph ให้ไม่ทำงาน
หลังจากคิดและทดลองอยู่หลายตลบ ผมก็ได้ข้อสรุปเป็นลำดับกฎว่าดังนี้ :-
สตริงเริ่มแรก: C + Macron + BV + T Uniscribe/Harfbuzz: C + BV + T + Macron 1: สลับ T กับ Macron C + BV + Macron + T 2: สลับ BV กับ Macron C + Macron + BV + T 3: ligature C-Macron-lig + BV + T || C + Macron + BV + T 3: สลับ Macron กับ BV C + BV + Macron + T 4: สลับ Macron กับ T C + BV + T + Macron general composition C + T.low + BV + Macron 5: สลับ BV กับ Macron C + T.low + Macron + BVกล่าวคือ เริ่มจากเลื่อนตัวขีดเส้นใต้ไปชิดกับพยัญชนะก่อนเพื่อให้กฎ ligature ทำงาน และถ้าตัวขีดเส้นใต้ไม่ได้ทำให้เกิด ligature ก็เลื่อนกลับที่เดิมเพื่อให้กฎ ปู่ ใน general composition ทำงาน จากนั้นจึงสลับตัวขีดเส้นใต้ให้มาก่อนสระล่าง ก็เป็นอันได้ลำดับที่เราต้องการ
กรณีลำดับของพินทุกับสระล่างที่ Uniscribe/Harfbuzz แปลงสารมาก็ทำนองเดียวกัน มีความซับซ้อนเล็กน้อย แต่ก็แค่กับกฎ ปู่ เท่านั้น :-
สตริงเริ่มแรก: C + Ph + BV + T Uniscribe/Harfbuzz: C + BV + Ph + T 1: สลับพินทุกับ BV C + Ph + BV + T general composition: C + Ph + T.low + BV 2: สลับพินทุกับ T.low C + T.low + Ph + BVกล่าวคือ สลับพินทุกับสระล่างกลับให้เป็นเหมือนเดิม แล้วปล่อยให้กฎ ปู่ ใน general composition ทำงาน เสร็จแล้วก็เลื่อนวรรณยุกต์ตัวต่ำให้เข้าไปชิดกับพยัญชนะ
ผลที่ได้ดูจะทำงานได้ดีเมื่อทำ stress test ด้วยภาษาแต้จิ๋ว:
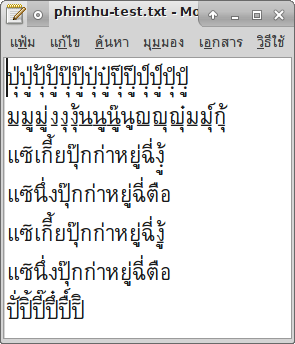
และเนื่องจาก requirement ในเรื่องตัวหนอนนาสิกและตัวขีดเส้นใต้ของภาษาแต้จิ๋ว เป็น superset ของมลายูปาตานี การผ่านการทดสอบด้วยภาษาแต้จิ๋วย่อมถือว่าครอบคลุมภาษามลายูปาตานีโดยปริยาย
สังเกตว่า ในขณะที่ทำภาษามลายูปาตานีในขั้นแรกนั้น ผมลืมกรณีที่พยัญชนะขีดเส้นใต้มีสระล่างไปเสียสนิทด้วยซ้ำ การเล่นกับภาษาแต้จิ๋วยังช่วยจับบั๊กนี้ให้ด้วย
เมื่อทดลองกับฟอนต์ Garuda เป็นที่พอใจแล้ว ก็มาสรุปขั้นตอนทุกอย่างอีกครั้งกับฟอนต์ Kinnari:
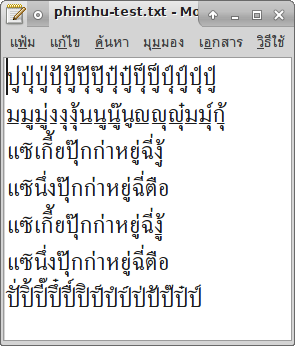
แล้วก็ใช้ฟอนต์ Kinnari เป็นแบบสำหรับฟอนต์อื่น ๆ ต่อไป โดยเริ่มจากฟอนต์ Norasi:
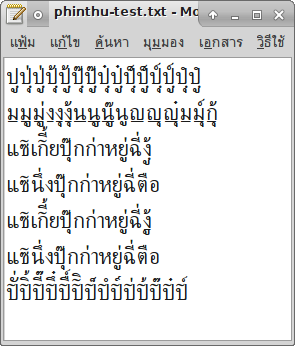
ตอนนี้ทำถึงขั้นนี้เท่านั้นครับ ยังมีฟอนต์อื่น ๆ อีกสิบกว่าฟอนต์ในชุด fonts-tlwg ที่ผมจะค่อยทยอยทำต่อไปเมื่อมีเวลาว่าง คาดว่าคงใช้เวลาอีกหลายเดือน :-P
ผมสร้าง หน้าทดสอบ โดยใช้ web font ที่สร้างจากตัวล่าสุดที่อยู่ระหว่างพัฒนาไว้ด้วย คงจะอัปเดตไปเรื่อย ๆ ตามความคืบหน้าครับ
ในอีกด้านหนึ่ง ก็ได้ อภิปรายและเสนอแพตช์ สำหรับ Harfbuzz เพื่อขอตัดการ override combining class ของสระล่างของไทยเสียด้วย ดูจะได้รับความเห็นชอบ แต่ยังไม่ apply เสียที อาจจะเกรงความไม่เข้ากันกับ Uniscribe หรือเปล่าก็ไม่ทราบได้ แต่การแก้ในฟอนต์ที่ผมทำไปก็เท่ากับทำให้มันทำงานบนวินโดวส์ได้ด้วย