By: mk 
 on 16 February 2017 - 14:55
Tags:
on 16 February 2017 - 14:55
Tags:

ซอฟต์แวร์แห่งโลกยุคใหม่ที่มาแรงสองตัวคือ Apache Hadoop/Spark สำหรับงานประมวลผล Big Data และ TensorFlow สำหรับงาน Machine Learning
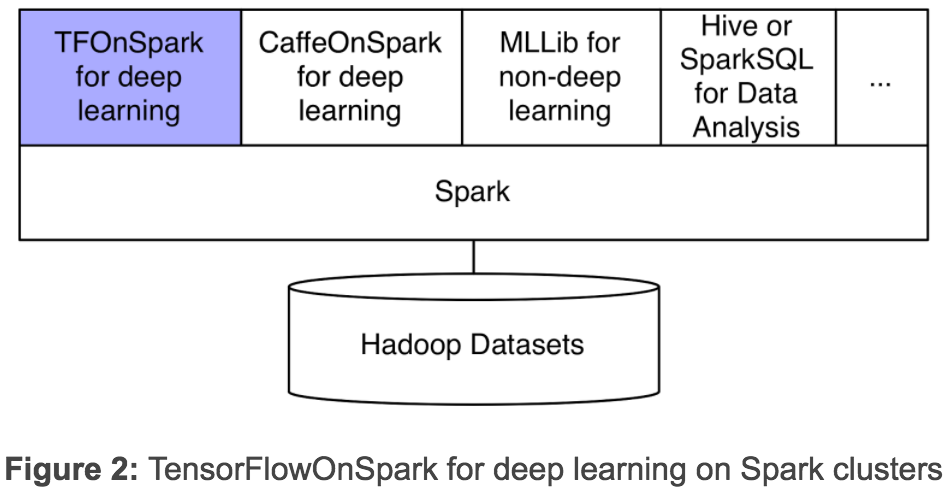
ล่าสุดทีมพัฒนาจาก Yahoo จับมันมารวมกันแล้วในชื่อว่า TensorFlowOnSpark หน้าที่ของมันคือการนำฟีเจอร์เรียนรู้ของ TensorFlow มารันอยู่บนคลัสเตอร์ Hadoop/Spark โดยตรง เพื่อไม่ให้ต้องย้ายข้อมูลระหว่างคลัสเตอร์สองระบบ ซึ่งเสียเวลาและทรัพยากรในการย้ายข้อมูลขนาดใหญ่
แนวคิดนี้ไม่ใช่ของใหม่ เพราะปีที่แล้ว Yahoo เคยนำ Caffe เฟรมเวิร์คด้าน Deep Learning ชื่อดังอีกตัวมารันบน Spark โดยใช้ชื่อว่า CaffeOnSpark มาก่อนแล้ว คราวนี้เมื่อ TensorFlow ได้รับความนิยมมากขึ้น Yahoo จึงพัฒนาระบบแบบเดียวกัน
TensorFlowOnSpark เปิดโค้ดเป็นโอเพนซอร์ส ใช้สัญญาอนุญาต Apache 2.0 โค้ดอยู่บน GitHub
ที่มา - Yahoo

Get latest news from Blognone
Follow @twitterapi



Blognone Jobs Premium
Cloudnone
- สงคราม GenAI บนคลาวด์ในปี 2024 ไปถึงไหนกันแล้ว | Cloudnone x AWS
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
Comments
Keras มีนานแล้วครับท่าน ใช้ Library Elephas
แล้วที่ตลกคือ Keras มัน Complie Code ตัวเองเป็น TensorFlow นะครัช
ปล.บางคนเขาไม่ชอบเขียน TensorFlow นะครับ เพราะมันเขียนยากมากๆ ลองดูเทียบกับ Keras ได้เลย