By: lew 


 on 5 October 2017 - 13:25
Tags:
on 5 October 2017 - 13:25
Tags:
Topics:

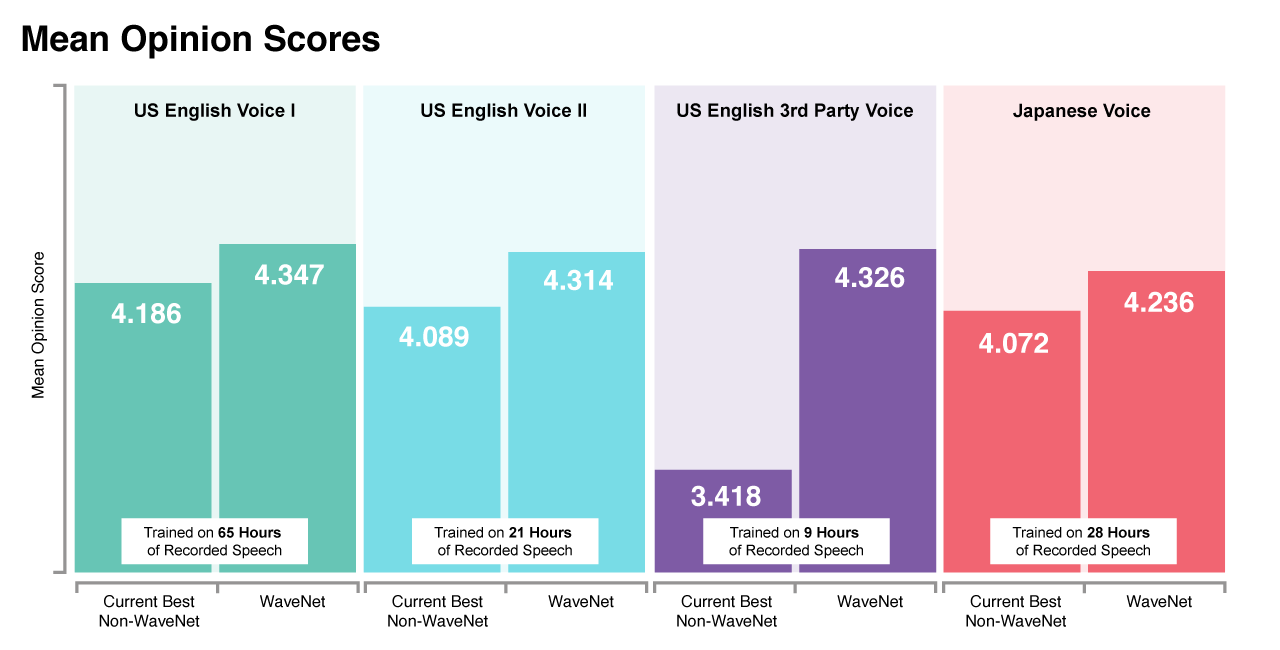
งานเปิดตัวสินค้าของกูเกิลเมื่อวานนี้พระเอกของงานนอกจากจะเป็นฮาร์ดแวร์แล้ว ฝั่งซอฟต์แวร์ Google Assistant ก็ถูกหลอมรวมเข้าไว้แทบทุกผลิตภัณฑ์ สิ่งหนึ่งที่เปลี่ยนไปคือเทคโนโลยีการสังเคราะห์เสียง (text to speech - TTS) ที่ทีมงาน DeepMind ออกมารายงานว่าตอนนี้เป็น WaveNet เวอร์ชั่นใหม่
WaveNet เปิดตัวตั้งแต่เดือนกันยายนปีที่แล้ว จุดเด่นของมันคือสร้างเสียงจากโครงสร้างคำพูดก่อนหน้าทำให้เสียงมีความเป็นธรรมชาติมากขึ้น แต่การสร้างเสียงที่มีรายละเอียดสูงเช่นนี้กลับกินพลังประมวลผลอย่างหนักจนไม่สามารถใช้งานจริงได้
ปีที่ผ่านมาทีมงาน DeepMind จึงปรับปรุงประสิทธิภาพของ WaveNet จนทำงานได้เร็วขึ้นพันเท่า จากการปรับปรุงโมเดล และนำไปรันบน TPU Cloud ของกูเกิลเอง ทำให้ตอนนี้ เวลาประมวลผล 1 วินาทีสามารถสร้างเสียงได้ 20 วินาที ขณะที่ความละเอียดของไฟล์เสียงที่ออกมาก็เพิ่มจาก 8 บิตเป็น 16 บิต
ตอนนี้เอนจิน WaveNet ใช้งานกับภาษาอังกฤษและภาษาญี่ปุ่นเท่านั้น
ที่มา - DeepMind

Get latest news from Blognone
Follow @twitterapi



Blognone Jobs Premium
Cloudnone
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
- สรุปของใหม่และสาระสำคัญจาก AWS re:Invent 2023 | Cloudnone Special EP
Comments
Current best non-Wavenet ของภาษาญี่ปุ่นนี่อย่าบอกนะว่า Vocaloid?
vocaloid เป็น vocal synthesis มากกว่าจะเป็ฯ voice นะครับ
อีกอย่างผมว่ามันเป็น Sampler มากกว่า :P