By: arjin 

 on 7 September 2017 - 09:39
Tags:
on 7 September 2017 - 09:39
Tags:
Topics:

Jeremy Hermann และ Mike Del Balso วิศวกรด้านวิศวกรรมข้อมูลของ Uber เปิดเผยข้อมูลของแพลตฟอร์มที่พัฒนาเพื่อใช้กันภายในองค์กรชื่อ Michelangelo ซึ่งเรียกว่าเป็น Machine Learning-as-a-service เพื่อให้พนักงานสามารถใช้งานได้ในวงกว้าง
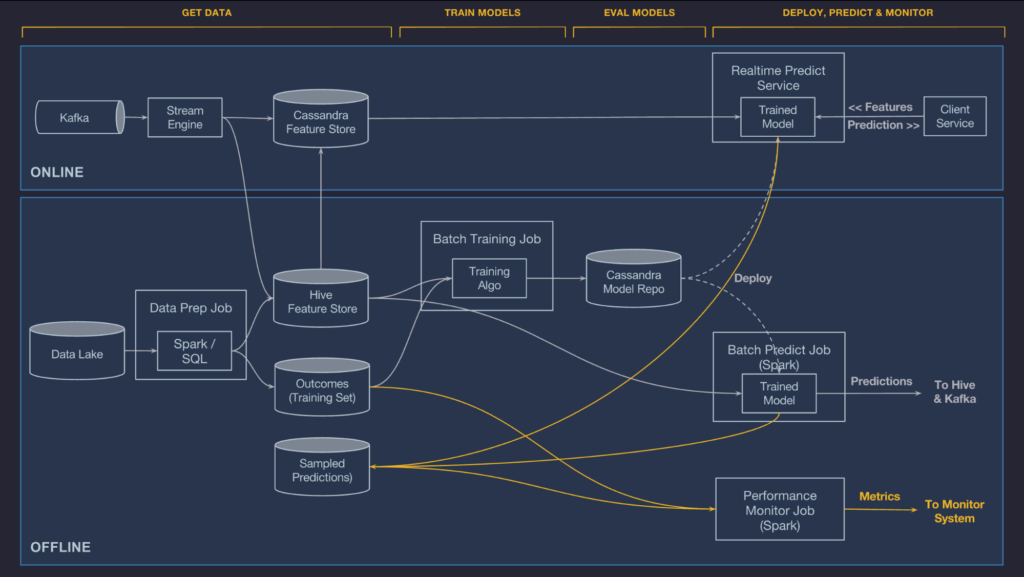
ที่มาของการสร้างแพลตฟอร์มนี้ เกิดจากใน Uber มีความต้องการสร้างชุด Machine Learning ที่หลากหลาย แต่ในอดีตนั้นนักวิทยาศาสตร์ข้อมูล ก็เลือกใช้เครื่องมือตามความถนัด ไม่ว่าจะเป็น R, scikit-learn จนถึงเขียนอัลกอริทึมขึ้นเอง ทำให้การสร้างโมเดลต่างๆ จำกัดอยู่ในนักวิทยาศาสตร์ข้อมูล และไม่ทันต่อความต้องการ อีกทั้งเมื่อต่างคนต่างสร้างโมเดล ก็ไม่สามารถหามาตรฐานและเปรียบเทียบกันได้ง่าย จึงเป็นที่มาของการสร้างแพลตฟอร์มกลาง Michelangelo
Michelangelo เริ่มพัฒนาเมื่อปี 2015 ปัจจุบันใช้งานกันใน Uber มาราว 1 ปี แล้ว โดยพัฒนาจากโอเพนซอร์สคือ HDFS, Spark, Samza, Cassandra, MLLib, XGBoost และ TensorFlow มีระบบปิดที่พัฒนาใช้เองเพียงเล็กน้อย กรณีที่ไม่สามารถหาโอเพนซอร์สมารองรับได้
ในบล็อกนี้ยังยกตัวอย่างการนำ Michelangelo ไปใช้งานจริง โดยเป็นการแก้ปัญหาของ UberEATS เพื่อคำนวณหาระยะเวลาในการจัดส่งอาหารที่แม่นยำที่สุด เนื่องจากมีปัจจัยที่ซับซ้อนสูง อาทิ คิวรอทำอาหารในร้านตามช่วงเวลา, ความยากในการหาที่จอดรถเพื่อไปรับ-ส่งอาหารของผู้จัดส่ง ฯลฯ
แพลตฟอร์มนี้ทำให้คนใน Uber สามารถจัดการเลือกข้อมูล เทรนข้อมูล ทดสอบด้วยโมเดลต่างๆ และเริ่มนำไปใช้งานได้เลย รายละเอียดการใช้งานค่อนข้างยาว สามารถอ่านเพิ่มเติมได้จากที่มาครับ
ที่มา: Uber Engineering Blog

Get latest news from Blognone
Follow @twitterapi
Hiring! บริษัทที่น่าสนใจ



Blognone Jobs Premium
Cloudnone
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
- สรุปของใหม่และสาระสำคัญจาก AWS re:Invent 2023 | Cloudnone Special EP