By: lew 


 on 4 August 2016 - 02:46
Tags:
on 4 August 2016 - 02:46
Tags:
Topics:

Evan Klitzke จาก Uber เขียนบล็อกเล่าถึงสถาปัตยกรรมภายในของ Uber ที่แต่เดิมพัฒนาระบบหลังบ้านด้วย Python และ PostgreSQL ทั้งระบบ แต่ระบบใหม่ๆ กลับหันไปใช้ Schemaless บน MySQL แทน
บล็อกของ Uber ลงลึกระดับสถาปัตยกรรมของระบบฐานข้อมูลบนดิสก์ที่ PostgreSQL และ MySQL ต่างกัน (ในกรณี MySQL เปลี่ยน storage engine ได้ แต่กรณีนี้พูดถึง InnoDB เท่านั้น) ที่เมื่อเราสร้าง index บนตารางใดๆ แล้ว PostgreSQL จะสร้างตาราง index ขึ้นมาใหม่เพื่อชี้ตรงไปยังแถวของข้อมูลบนดิสก์ทันที ขณะที่ MySQL จะชี้ตำแหน่งบนดิสก์ด้วยตาราง primary index เท่านั้น การสร้าง index อื่นๆ จะต้องชี้มายัง primary index อีกชั้น นอกจากนี้ แนวคิดของ PostgreSQL ยังไม่แก้ข้อมูลเดิมบนดิสก์แต่อาศัยการสร้างแถวใหม่เพื่อวางข้อมูลใหม่ลงไป
ความต่างของสถาปัตยกรรมเช่นนี้มีเหตุผลคนละแบบ แต่ในกรณีของ Uber ที่ระบบฐานข้อมูลมีการอัพเดตจำนวนมาก สถาปัตยกรรมของ PostgreSQL จะทำให้เมื่ออัพเดตข้อมูลใดๆ ในตารางจะต้องอัพเดต index ทั้งหมด ไม่ว่าข้อมูลในหลัก (column) ที่กำลังแก้จะเกี่ยวข้องกับ index เหล่านั้นหรือไม่ก็ตาม เพราะเมื่ออัพเดตแล้วข้อมูลจะหลายเป็นแถวใหม่ และทุกๆ index ต้องชี้ตรงมายังตำแหน่งของแถวบนดิสก์โดยตรง
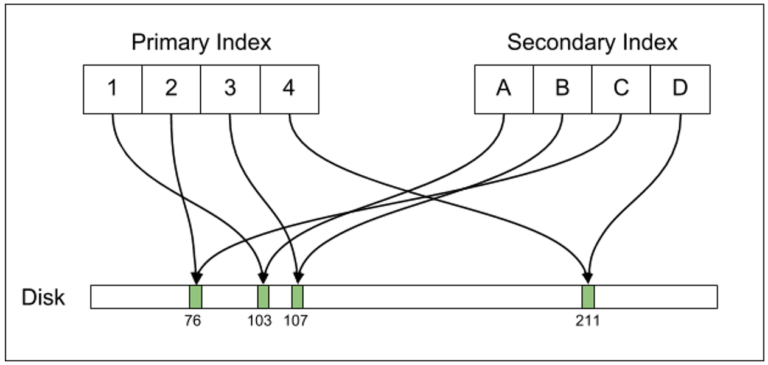
ระบบ index ของ PostgreSQL จะสร้างตารางสำหรับทุก index และชี้ตรงไปยังตำแหน่งบนดิสก์
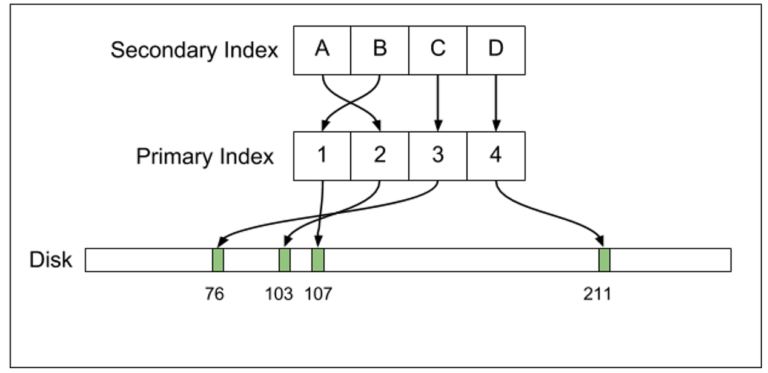
ระบบ index ของ MySQL (InnoDB) จะสร้างตาราง index เพื่อชี้ไปยัง primary index อีกครั้ง
Klitzke ชี้ว่า PostgreSQL อาศัยการซิงก์ข้ามเครื่องผ่าน write-ahead-log (WAL) ที่ทำหน้าที่คือรักษาข้อมูลบนดิสก์ให้ตรงกับทั้งเครื่องต้นทางและปลายทางเท่านั้น PostgreSQL เลือกแนวทางนี้เพราะประสิทธิภาพในการอัพเดตที่เร็วกว่า แต่ก็มีข้อจำกัดในกรณีของ Uber ที่ข้อมูลมี index มากทำให้ข้อมูลที่ต้องเปลี่ยนแปลงมากไปด้วย ส่งผลไปถึงแบนวิดท์เพื่อใช้ในการซิงก์ฐานข้อมูลสูงขึ้นเป็นเงาตามตัว
ข้อจำกัดสำคัญของ PostgreSQL อีกอย่างคือไม่สามารถซิงก์ข้อมูลข้ามเวอร์ชั่นกันได้ เพื่ออัพเกรดระบบฐานข้อมูลจำเป็นต้องดาวน์ระบบเพื่อรันอัพเกรด แล้วจึงรันระบบฐานข้อมูลขึ้นมาใหม่ ทาง Uber เคยอัพเกรดครั้งหนึ่งจากเวอร์ชั่น 9.1 ไปยัง 9.2 ซึ่งใช้เวลาหลายชั่วโมง แต่ระบบทุกวันนี้ใหญ่กว่าเดิมาาก และไม่สามารถยอมรับการดาวน์ระบบแบบเดิมได้
ทางฝั่ง PostgreSQL มี Simon Riggs จาก 2ndQuadrant ออกมาเขียนบล็อกชี้แจง ระบุว่าแนวทางของ PostgreSQL มีความได้เปรียบในกรณีส่วนใหญ่ กระบวนการชี้ index ตรงไปยังข้อมูลทำให้การเข้าถึงเร็วกว่า และกระบวนการออปติไมซ์ เช่น Heap Only Tuple (HOT) ของ PostgreSQL ก็ควรจะลดปัญหาที่ Uber พบไปแล้ว
ประเด็นสำคัญที่ PostgreSQL เสียเปรียบคือการไม่มีทางเลือกสำหรับซิงก์ข้ามเครื่องแบบ logical ซึ่ง Riggs ระบุว่า pglogical ของ 2ndQuadrant เข้ามาแก้ปัญหานี้แล้ว และรองรับตั้งแต่ PostgreSQL รุ่น 9.4 ขึ้นไป ส่วน 9.1 ทาง 2ndQuadrant มีบริการให้เฉพาะ และ 9.2/9.3 จะเปิดให้บริการปีหน้า รวมถึง pglogical จะรวมไว้ในโครงการหลักของ PostgreSQL ตั้งแต่รุ่น 10.0 เป็นต้นไป
ที่มา - Uber Engineering, 2ndQuadrant

Get latest news from Blognone
Follow @twitterapi



Blognone Jobs Premium
Cloudnone
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
- สรุปของใหม่และสาระสำคัญจาก AWS re:Invent 2023 | Cloudnone Special EP
Comments
อ่านแล้วตกใจกำลังจะไปฝึกใช้ pg อยู่พอดี แต่ชอบ MariaDB มากกว่า
หรือนี่เป็นอีกเหตุผลหนึ่งที่ผู้ให้บริการ hosting ใช้ pg น้อยกว่า my
กรณีนี้มันเฉพาะมากๆ ครับ (มี index เยอะบนตารางเดียว, อัพเดตถี่ๆ, มี hot-backup ต้องซิงก์ข้ามเครื่อง) hosting ทั่วๆ ไปในบ้านเราน่าจะไม่เข้าข่าย น่าจะเป็นเรื่องแอพที่รองรับมากกว่า
lewcpe.com, @wasonliw
ถามผู้รู้ ตอนนี้มี database in-memory ที่ฟรีและน่าใช้มั้ยครับ
เอาแบบ hybrid disk-ram ก็ดีครับ
อยากรู้ด้วยคนครับ ฟรีๆ
เล่น in-mem กับข้อมูลจริง ไม่จัด Hardware รองรับดีๆ ไฟมีปัญหาระวังชีวิตลำบากนะครับ
ผมกำลังสงสัยอยู่ ว่า in ram กับ ssd เนี่ย performance ไกลกันขนาดไหน คุ้มรึเปล่า
แต่ก่อนเคยคิดอยากใช้ตอนเขียนโปรแกรมแล้ว db ช้า
แต่พอแก้ที่ SQL ก็เร็วขึ้นแล้วเลยไม่ได้ตามต่อ
SSD ไม่คุ้มหากจะเอามาใช้งาน IO หนักๆ เพราะ Write Cycle จำกัด แล้วคุณจะต้องเสียเงินไปกับค่าเปลี่ยน SSD ทุกเดือน
สมัยที่ยังไม่มี In-Memory DB ผมทำ RamDisk เลย เฉพาะข้อมูลที่ถูกเรียกบ่อย อันไหนทำจบ transaction จับลง DB หลัก สะดวกดี
SSD หลายที่ก็ยังใช้คุ้มครับ คำว่าหนักๆนี่คือต้องยัดข้อมูลเยอะมากเลยนะมันถึงจะนับเร็วขนาดนั้นปกติมันก็วนๆกว่าจะได้ cycle จริงนี่นานโข ซื้อ SSD เกินขนาดที่จะใช้ไปเยอะๆหน่อยก็อยู่ได้ยาวครับแรงกว่า HDD ธรรมดาเยอะเลย สมัยนี้ไม่แพงมากแล้วครับมีความคุ้มอยู่พอสมควร
cycle ของ SSD ที่เคยใช้สำหรับงานตอนนั้นคือ 6 เดือนครับ ถ้าขืนไม่ลงแรมผมว่าได้ไม่เกินเดือนเศษ
เกือบลืม ผมทำให้ HDD ลูกใหม่ลาโลกได้ในหนึ่งอาทิตย์ครับ
SSD เอามาใช้เป็น Temp tablespace ตัวหลัก ตัวรองๆเป็น HDD ก็ได้ครับ (เวลาเสียแล้วจะได้ disable ส่งต่อให้ disk ตัวอื่นทำงานแทน)
เป็นทางผ่านของการ process เสร็จแล้วก็เอาไปไว้ Target ที่ tablespace เป็น HDD
ก็เพราะเป็น temp ไม่จำเป็นต้องห่วงเรื่อง lost data ก็ได้เพราะ source,target อยู่ที่HDD
จริงๆกรณี้นี้ก็ไม่ต่างกับการทำ in-memory
ต่างแค่ว่า DB แต่ละเจ้ารองรับอะไรๆได้ไม่เหมือนกัน
Dev นี่ข้อมูลทดสอบเยอะขนาดไหนครับถึงช้า ใช้ ODM ถึกๆยังไม่เคยเจอช้ามากๆเลยปกติช้าสุดตอน compile นี่แหละ
เพราะเมื่ออัพเดตแล้วข้อมูลจะหลายเป็นแถวใหม่ **กลาย
แต่ระบบทุกวันนี้ใหญ่กว่าเดิมาาก **เดิมมาก