By: lew 


 on 29 August 2018 - 20:02
Tags:
on 29 August 2018 - 20:02
Tags:
Topics:
NVIDIA เผยแพร่งานวิจัย Video-to-Video Synthesis หรือ vid2vid โครงการสังเคราะห์วิดีโอในรูปแบบต่างๆ โดยมีความเหนือกว่าโมเดลเดิมๆ คือสามารถสร้างวิดีโอความละเอียดสูงระดับ 2K (2018x1024)
นักวิจัยลองฝึกโมเดลด้วยชุดข้อมูลต่างๆ เช่น ชุดข้อมูล Cityscape มาจัดส่วนต่างๆ ของภาพ (segmentation) ด้วย Mask R-CNN แล้วฝึกให้โมเดลสร้างวิดีโอจากภาพ segmentation ผลที่ได้คือวิดีโอที่สามารถแปลงสภาพแวดล้อม จากพื้นถนนปูนให้เป็นพื้นอิฐ หรือแปลงสภาพแวดล้อมจากต้นไม้ให้เหลือแต่ตึก
อีกการทดลองหนึ่งอาศัยวิดีโอเต้นโคฟเวอร์จาก YouTube แล้วแปลงวิดีโอเป็นท่าทางของคนเต้น (pose) ด้วยโมเดล DensePose และ OpenPose จากนั้นฝึกกลับให้สร้างวิดีโอจากท่าเต้น นักวิจัยพบว่าโมเดลสามารถสร้างท่าเต้นได้สมจริง แม้จะพบท่าเต้นที่ไม่เคยเจอมาก่อนในชุดข้อมูลฝึก ตัวอย่างวิดีโอที่สร้างจากคนเต้นจริง (วิดีโอตัวอย่าง แสดงวิดีโอต้นฉบับอันซ้าย และวิดีโอที่สร้างขึ้นอีกสองอัน)
ทีมวิจัยฝึกโมเดลด้วยการ์ดกราฟิก 8 ใบโดยแต่ละใบมีแรม 24GB ซอฟต์แวร์ใช้ PyTorch 0.4
ที่มา - GitHub: NVIDIA/vid2vid, ArXiV


Get latest news from Blognone
Follow @twitterapi
Hiring! บริษัทที่น่าสนใจ



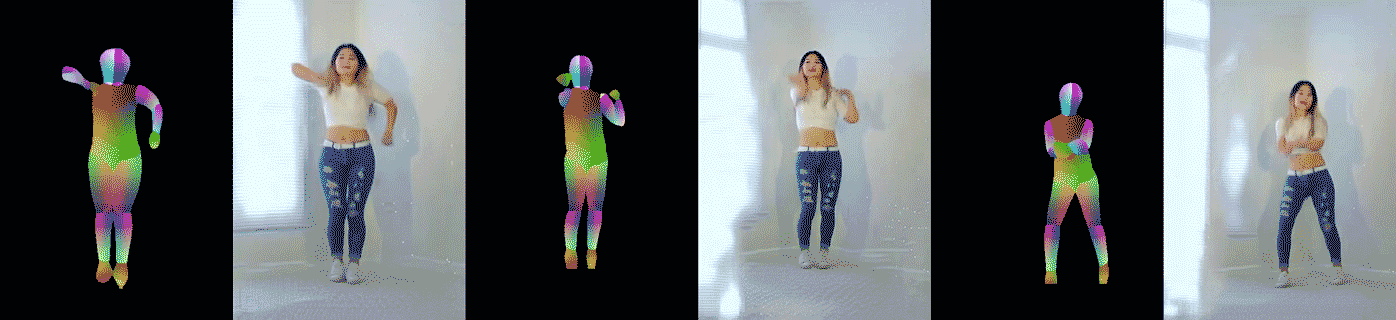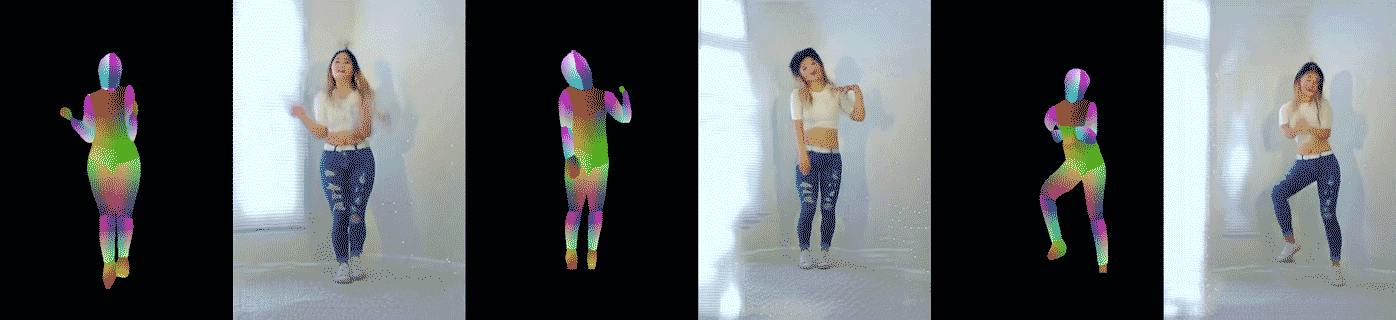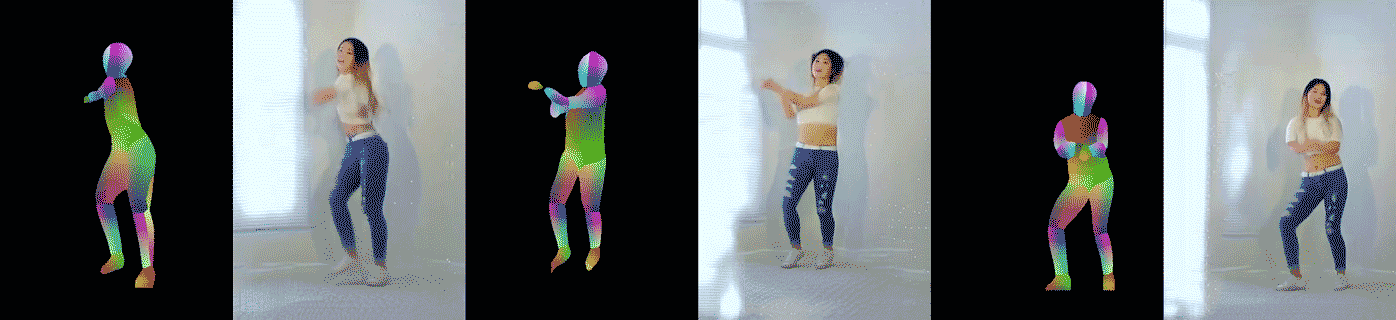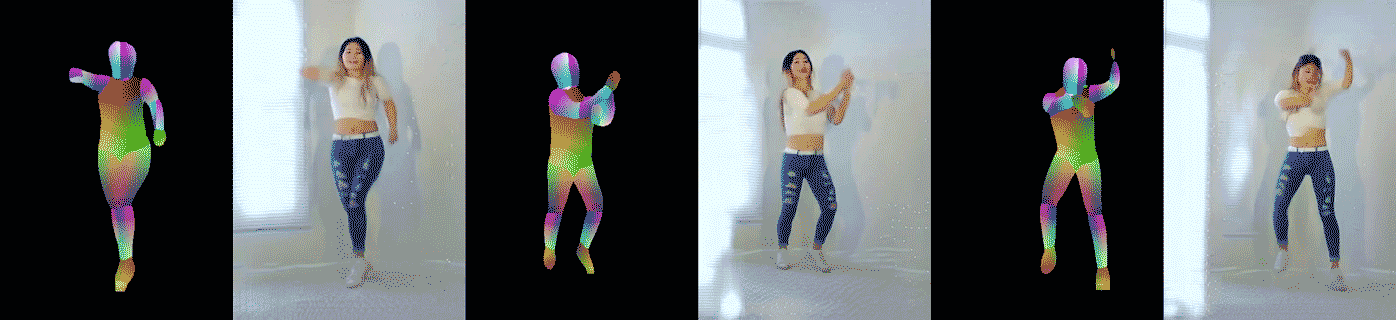{kind=link}
Blognone Jobs Premium
Cloudnone
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
- สรุปของใหม่และสาระสำคัญจาก AWS re:Invent 2023 | Cloudnone Special EP
Comments
ต่อไป จะสร้างคลิปยัดคำพูดใส่ปากใครก็ได้แล้วสินะ
ขณะที่ คลิปที่นักการเมืองพูดพล่อยๆจริงๆ ก็จะอ้างได้ว่าตัดต่อได้อย่างเต็มปาก (- -')
แม้ไม่มีนักการเมืองมาแล้วหลายปี ก็ยังคงมีการอ้างถึงนักการเมืองวนเวียนไปมา
จะไม่มีได้ไงครับ ตอนนี้ออกหาเสียงทั่วประเทศ ดูดนักการเมืองกันมาได้มาเกิน 250 เก้าอี้แน่ๆ แถมพูดออกรายการตัวเองวันหนึ่งอีกวันบอกไม่ได้พูดหน้าตาเฉยไม่ต้องบอกว่าตัดต่อเลยครับ คนดีย์
ทำได้มาสักพักแล้วครับ ลองดูคลิปนี้ก็ได้ https://www.youtube.com/watch?v=AmUC4m6w1wo
ขอบคุณครับสำหรับข่าวเทคโนโลยีที่ไม่มีเนื้อหาการเมือง ขอบคุณครับ
วงการหนัง วงการเกมส์ร้อง Wow กันเลยทีเดียว นักปั้น Model รัองอ๊ากกันเลยทีเดียว