By: lew 


 on 13 May 2018 - 00:36
Tags:
on 13 May 2018 - 00:36
Tags:
Topics:
ในบรรดาการเปิดตัวด้านปัญญาประดิษฐ์ของกูเกิลในงาน Google I/O ปีนี้ ส่วนที่เกี่ยวข้องกับนักพัฒนาที่สุดคงเป็น ML Kit ที่ช่วยให้การนำโมเดลปัญญาประดิษฐ์ที่พัฒนาขึ้นเองไปรันบนอุปกรณ์โดยตรงทำได้ง่ายขึ้น แต่ปัญหาสำคัญคือโทรศัพท์มักมีหน่วยความจำและพลังประมวลผลไม่สูงนัก การนำโมเดลขนาดใหญ่ไปรันมักจะรันไม่ไหว แต่กูเกิลก็เปิดบริการ Learn2Compress ให้บริการย่อขนาดโมเดลนิวรอนให้เล็กลงโดยคงความแม่นยำให้ใกล้เคียงของเดิม
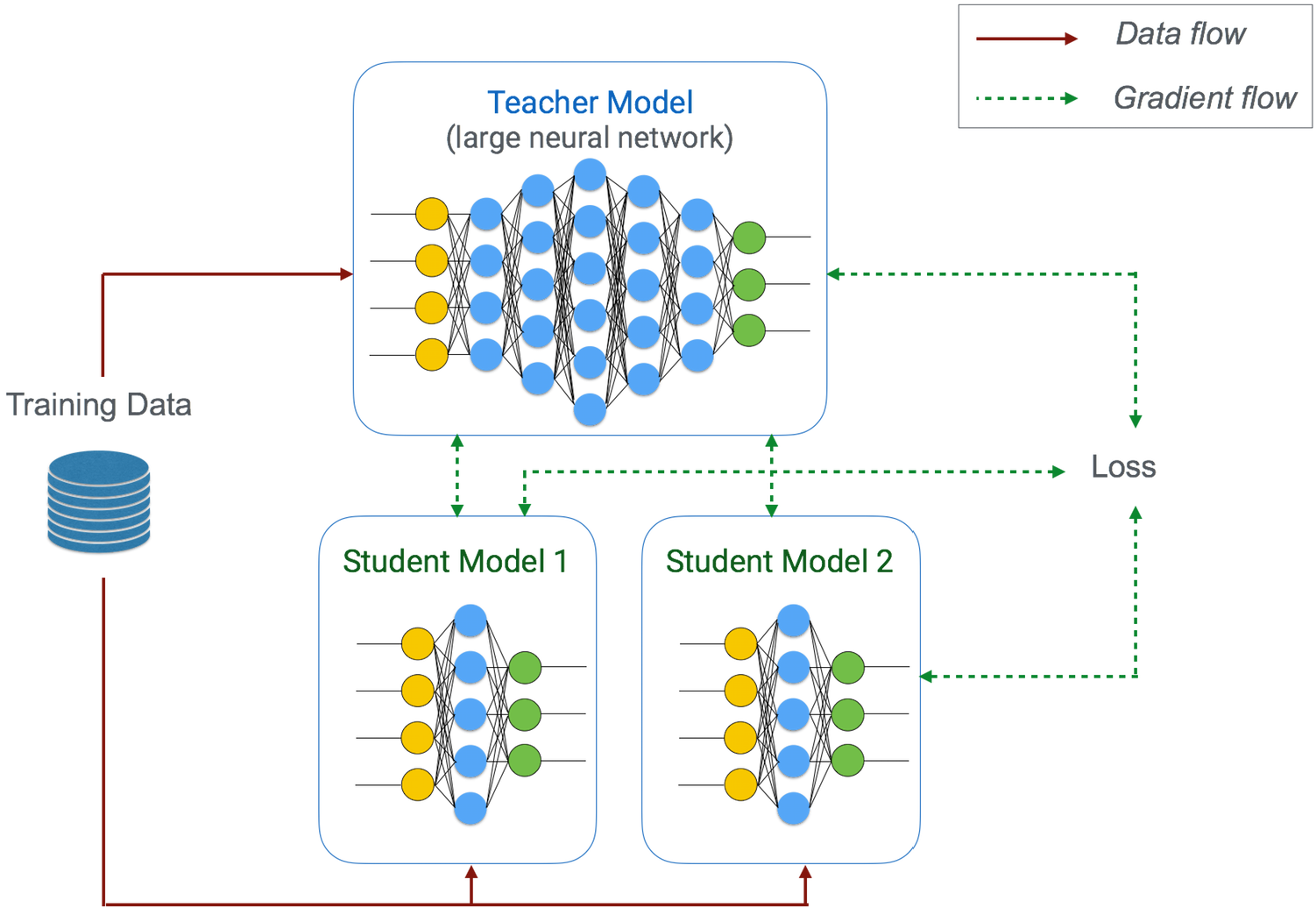
Learn2Compress อาศัยเทคนิค 3 อย่างหลักในการย่อขนาดโมเดลนิวรอน ได้แก่
- Pruning ตัดนิวรอนที่ไม่ค่อยมีผลต่อผลลัพธ์สุดท้ายออกไป ทำให้ได้โมเดลที่อาจจะเล็กลงเหลือเพียงครึ่งเดียว แต่ความแม่นยำยังได้ถึง 97%
- Quantization หลังจากตัดนิวรอนแล้วก็ลดความละเอียดของนิวรอนลงไป เช่น หานิวรอนรับค่าเป็น floating point 32 บิต ก็เปลี่ยนเป็น integer 8 บิตเสีย ทำให้ขนาดลดลงได้ถึง 4 เท่าตัว
- Join Training นำข้อมูลฝึกมาฝึกโมเดลที่ย่อแล้ว (เรียกว่าโมเดลนักเรียน / student model) มาดูผลการทำนายของโมเดลที่นักพัฒนาส่งเข้าไป แล้วพยายามให้โมเดลนักเรียนฝึกให้ผลลัพธ์ที่เหมือนกัน โดย Learn2Compress จะสร้างโมเดลนักเรียนขึ้นมาหลายแบบ และเลือกโมเดลที่เรียนได้ดีที่สุด
กูเกิลได้ใช้ Learn2Compress ย่อโมเดลเช่น NASNet ขนาด 54MB ที่ทำนายการจัดหมวดหมู่ภาพจากชุดข้อมูล CIFAR-10 ได้แม่นยำถึง 97.6% สามารถย่อไปจนเหลือขนาดโมเดลเพียง 0.5MB หรือเพียง 1 ใน 100 แต่ความแม่นยำยังได้ที่ 90.2%
Learn2Compress ยังเปิดให้ใช้งานในวงจำกัด ต้องลงทะเบียนล่วงหน้าและได้รับคำเชิญให้เข้าใช้งานเท่านั้น
ที่มา - Google AI

Get latest news from Blognone
Follow @twitterapi



Blognone Jobs Premium
Cloudnone
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11
- สรุปของใหม่และสาระสำคัญจาก AWS re:Invent 2023 | Cloudnone Special EP